




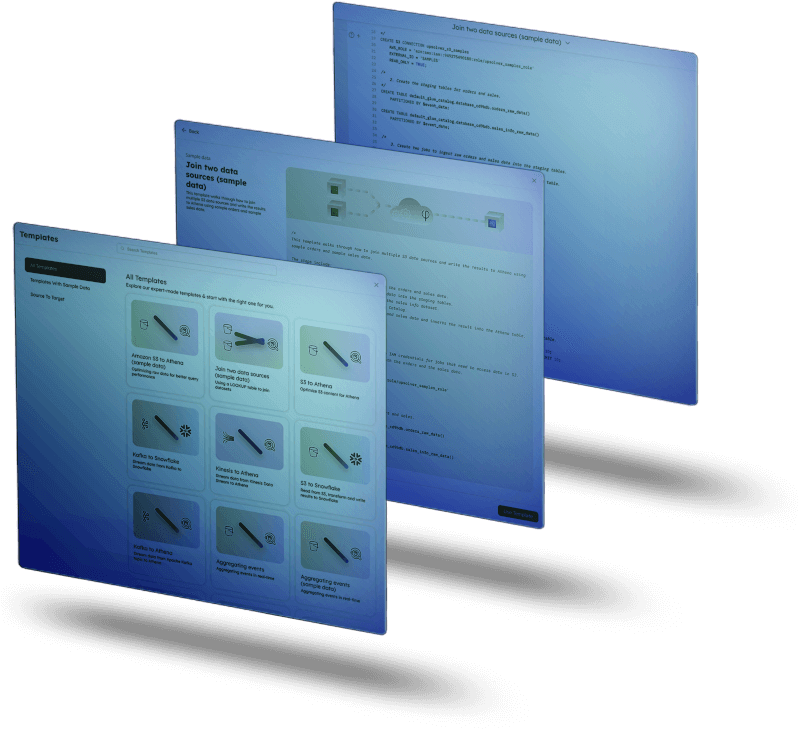
Explore our expert-made templates & start with the right one for you.
Introducing Upsolver SQLake
Build Pipelines. Not DAGs.
- Streaming plus batch in a single pipeline platform
- No Airflow - orchestration inferred from data
- $99 / TB of data ingested | unlimited free pipelines
Or alternatively, try SQLake for free
$99 per TB Ingested | Transformations Free | 30 Day Unlimited Trial
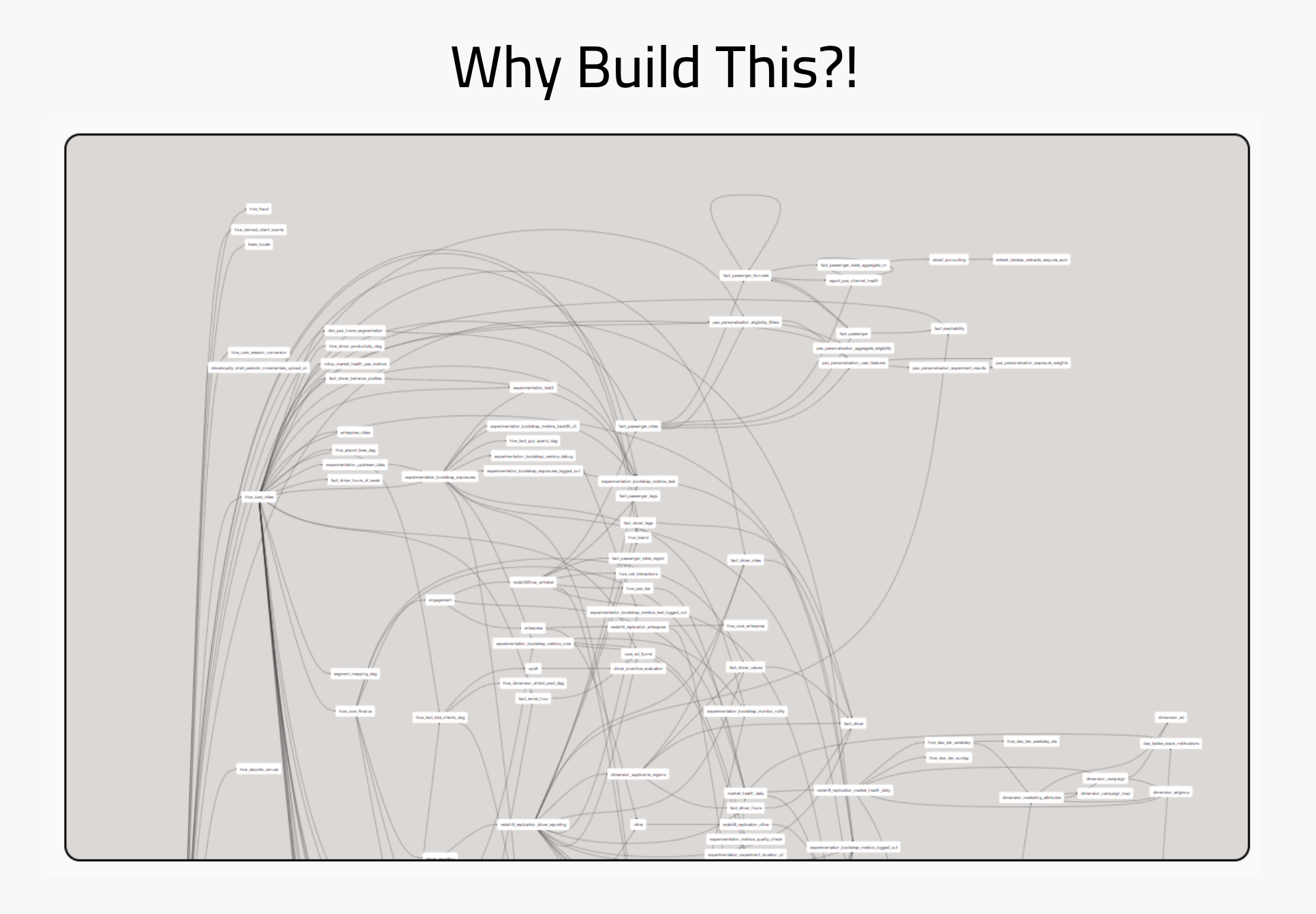
The Broken Pipeline Development Process
When you query a database, it automatically generates an execution plan. While a data pipeline is just query logic that runs continuously, data engineers are forced to spend countless hours manually building execution plans – a.k.a. coding orchestration DAGs.
Having to manually orchestrate data pipelines leads to:
- Long analytics cycles – every pipeline is an engineering project
- Unreliable and untrustworthy data
- High cost from poorly optimized pipelines
- Data engineering burnout from frequent break-fix cycles
- Frustrated data consumers who can’t self-serve raw data
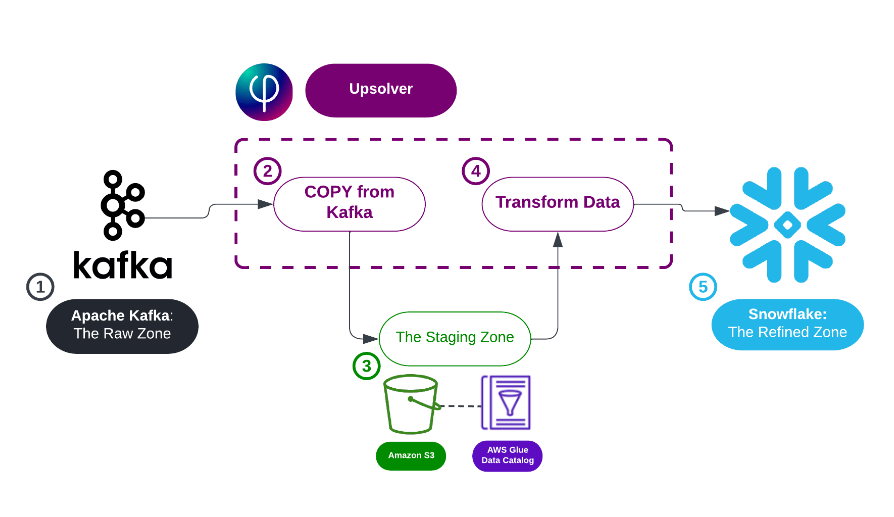
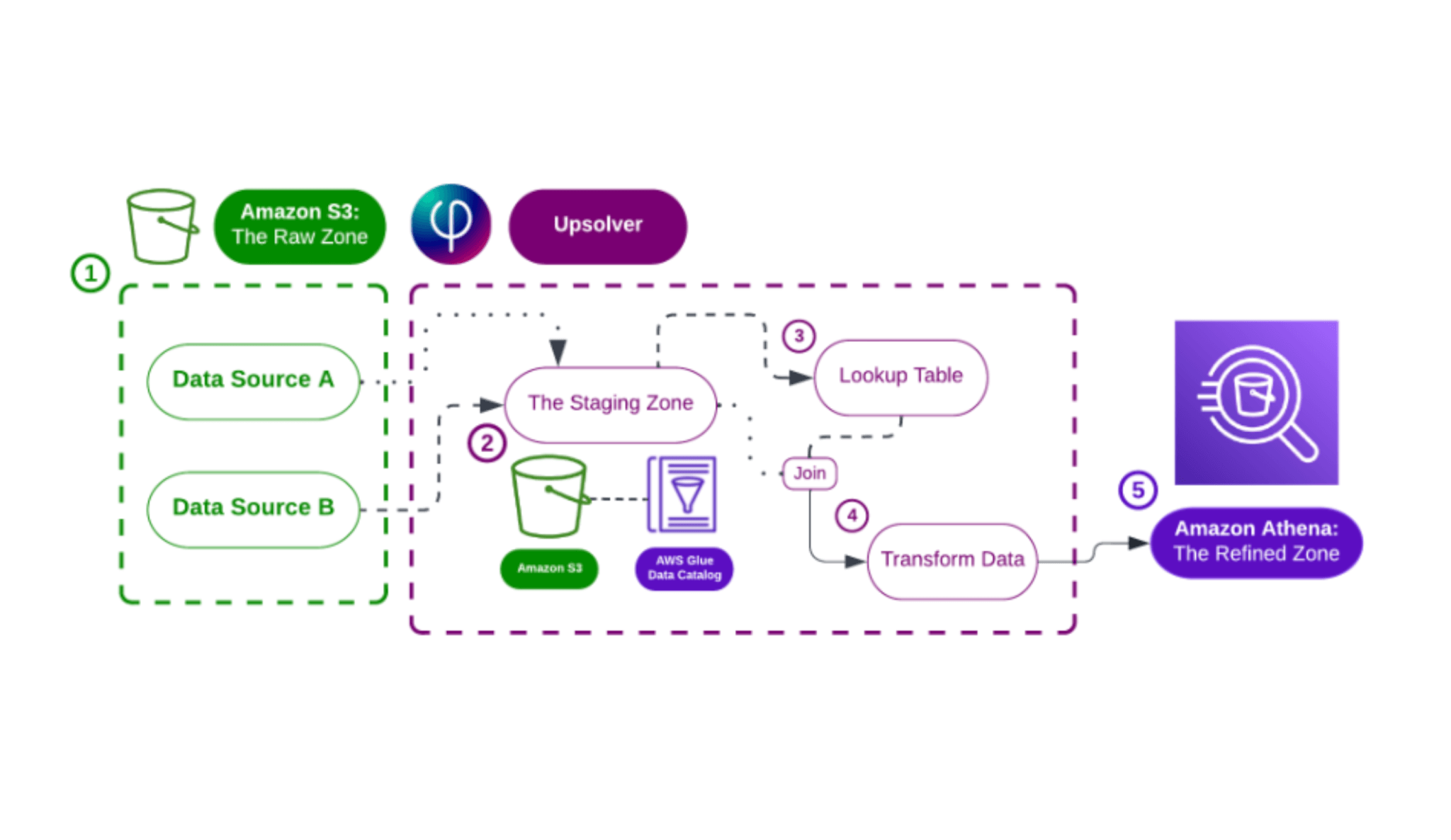
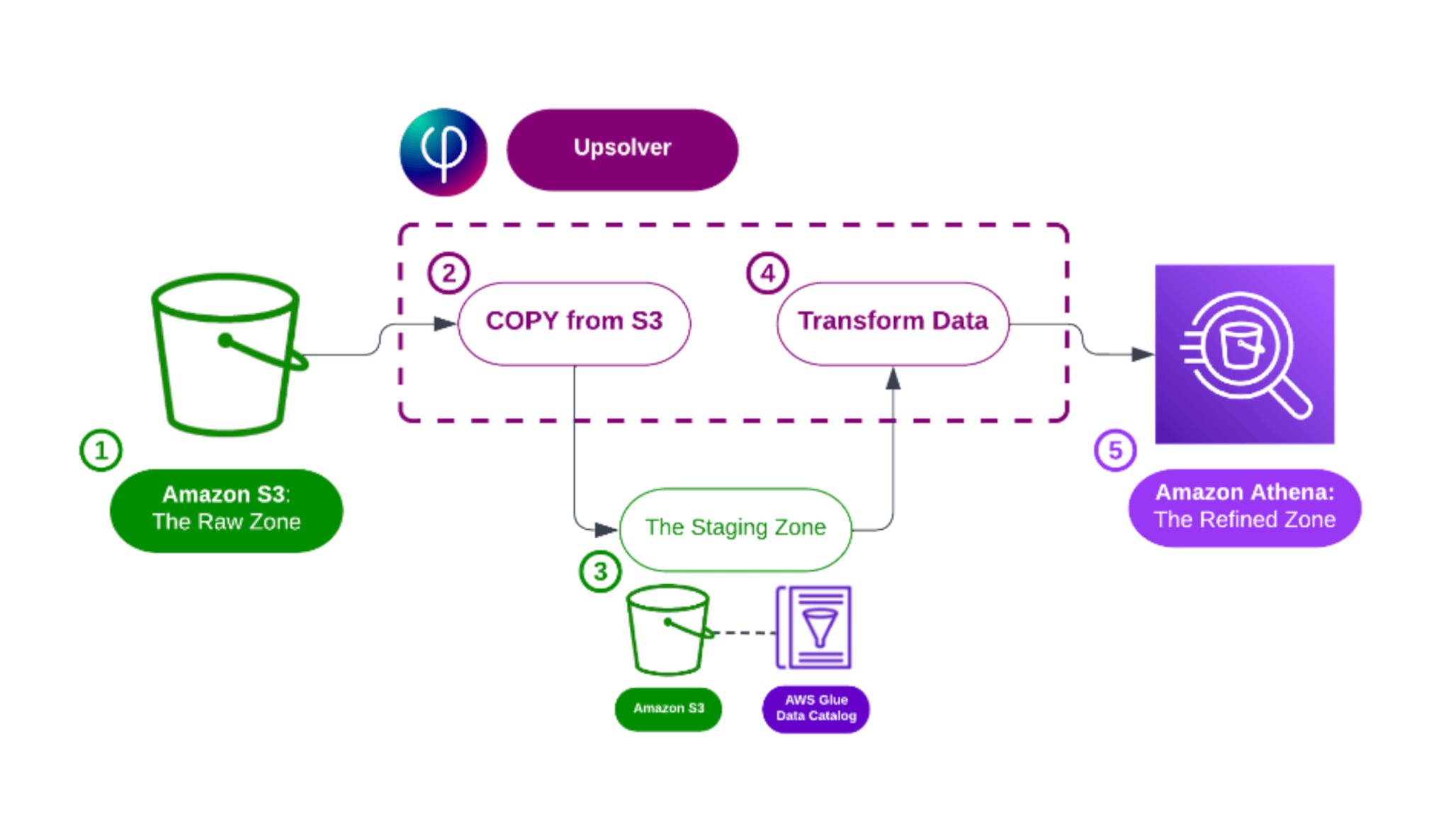
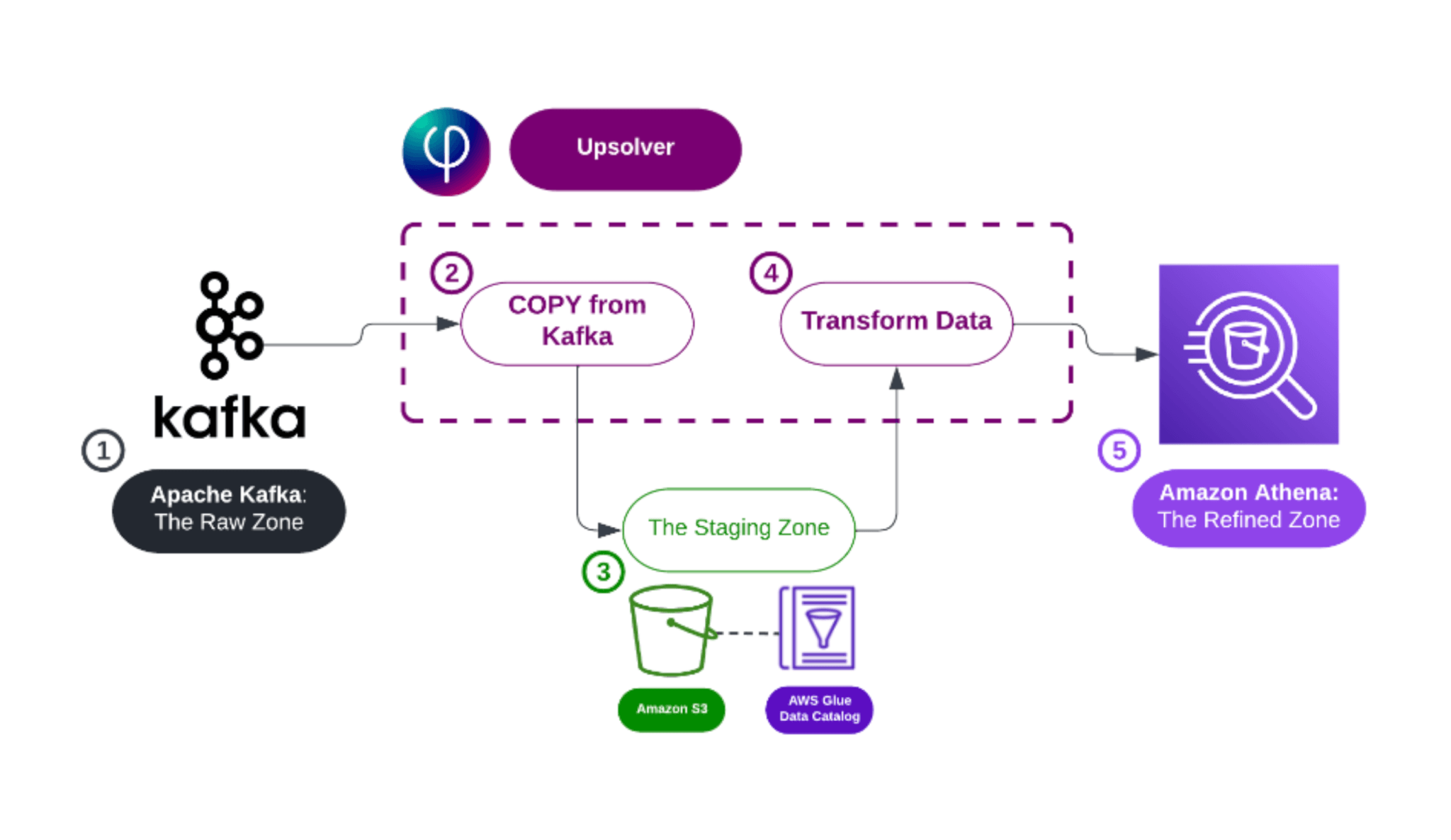
Write a Query -> Get a Pipeline
With SQLake, you use SQL to ingest streams and files into data lake tables and then create jobs which transform, join, and aggregate that data, and stream it into destination systems for analytics consumption.

Check out our SQLake How-to Guides








Check out the Pipeline Builders Hub
- Pipeline Templates
- Documentation
- How-to Guides
- Technical Blogs

Smarter Data Architecture Starts Here
Resources for Data Masterminds

Free Guide
Learn what’s the best way to design and build a data platform that’s aligned with your use cases.

Free eBook
Understand data lake architecture best practices in this practical handbook for data engineers, data scientists and data architects.

Comparison Guide
Learn how Upsolver’s technology differs from platforms built on Apache Spark in our comprehensive guide.