Explore our expert-made templates & start with the right one for you.
SimilarWeb: Analyzes Hundreds of Terabytes of Data with Amazon Athena and Upsolver
CUSTOMER STORY

INDUSTRY:
Market intelligence company
USE CASE:
Dealing with large amounts of data, and having to deal with different databases deflects the team’s focus on operations
DATA:
Hundreds of TB of data.
Low
cost
Fast
queries using SQL
Minimum
maintenance
The data-collection process is critical for SimilarWeb, because they can’t provide customers’ insights based on a flawed or incomplete data. The data collection team needs analytics to track new types of data, partner integrations, overall performance and more with great effectiveness as quickly as possible. It’s imperative for their team to identify and address anomalies as early as possible. Any tool that supports this process gives a significant advantage.
The Goal
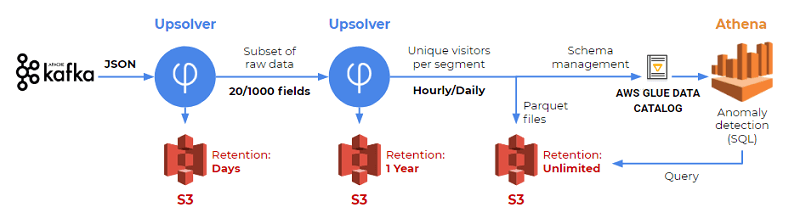
Hundreds of TB of data is streamed into SimilarWeb every month from different sources. The data is complex. It contains hundreds of fields, many of which are deeply nested, in addition to some with null values. This complexity creates a technical challenge because the data must be cleaned, normalized and prepared for querying.
The first option was to use existing on-premises Hadoop cluster, which processes all of SimilarWeb’s data in a daily batch process that takes a few hours to run. For their business-critical monitoring, a 24-hour delay is not acceptable.
SimilarWeb considered developing a new process using Hadoop. But that would require their team to focus away from daily operations to code, scale, and maintain extract, transform and load (ETL) jobs. Also, having to deal with different databases deflects their team’s focus on operations. Therefore, they wanted an agile solution where every team member could create new reports, investigate discrepancies, and add automated tests.
Low
cost
Fast
queries using SQL
Minimum
maintenance
The Solution
SimilarWeb chose Upsolver. Upsolver bridges together the data lake and the analytics users who aren’t big data engineers. Its cloud data lake platform helps organizations efficiently manage a data lake. Upsolver enables a single user to control big streaming data from ingestion to management and preparation for analytics platforms like Athena, Amazon Redshift and Elasticsearch Service (Amazon ES).