

Explore our expert-made templates & start with the right one for you.
To read a summary (one-pager) of the article in a PDF format click here

Where are you on the Fivetran cost rocketship?
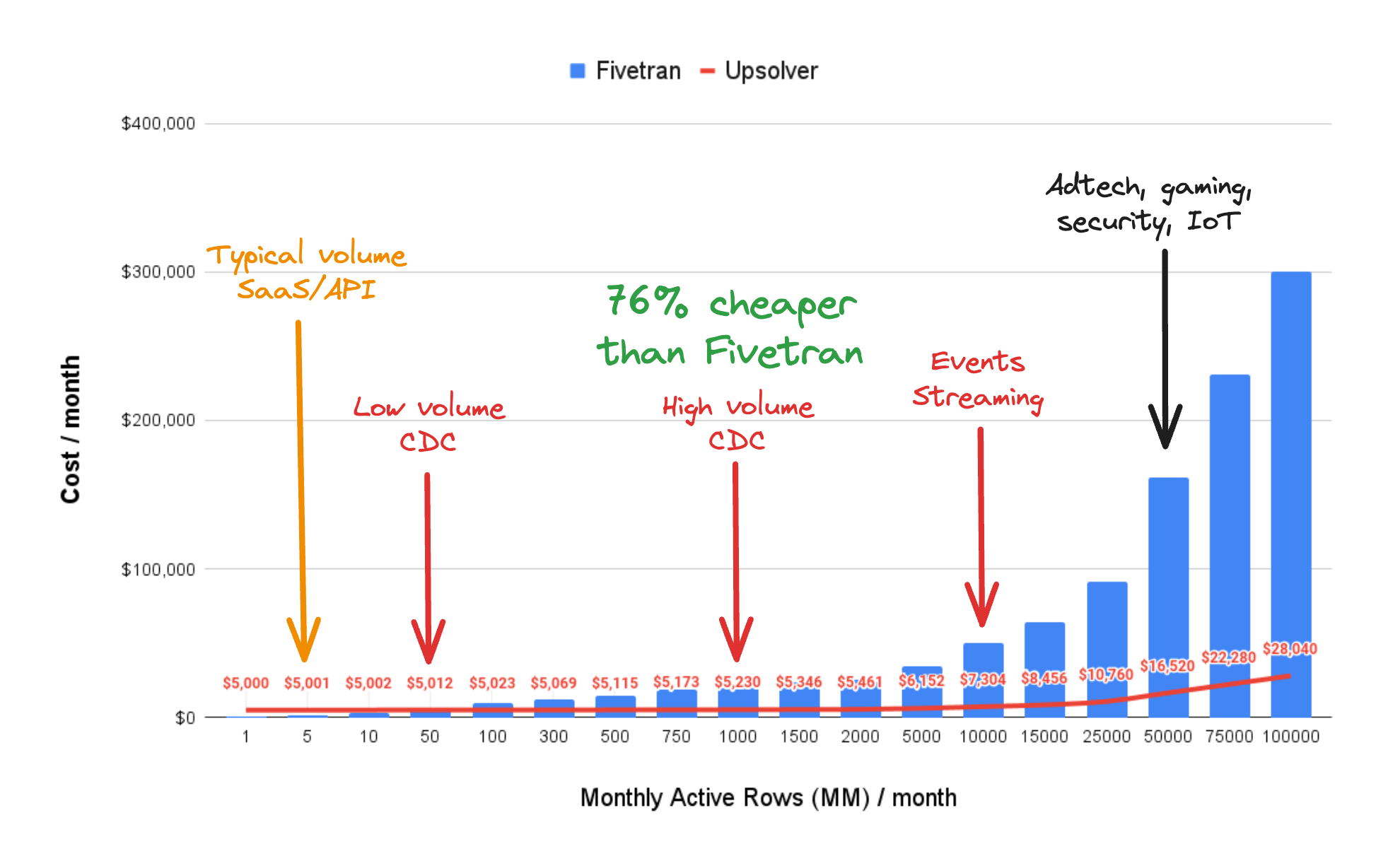
Fivetran is designed and priced for low volume data movement. It is best used for connecting to a wide range of sources that update and sync only a few times a day. As data volume and frequency of changes increase, Fivetran’s cost spikes with no bound!!
Log-based CDC replication from production databases
Change Data Capture (CDC) is the most efficient, low impact and scalable way to replicate large amounts of transactional data from operational databases to your warehouse or lake.
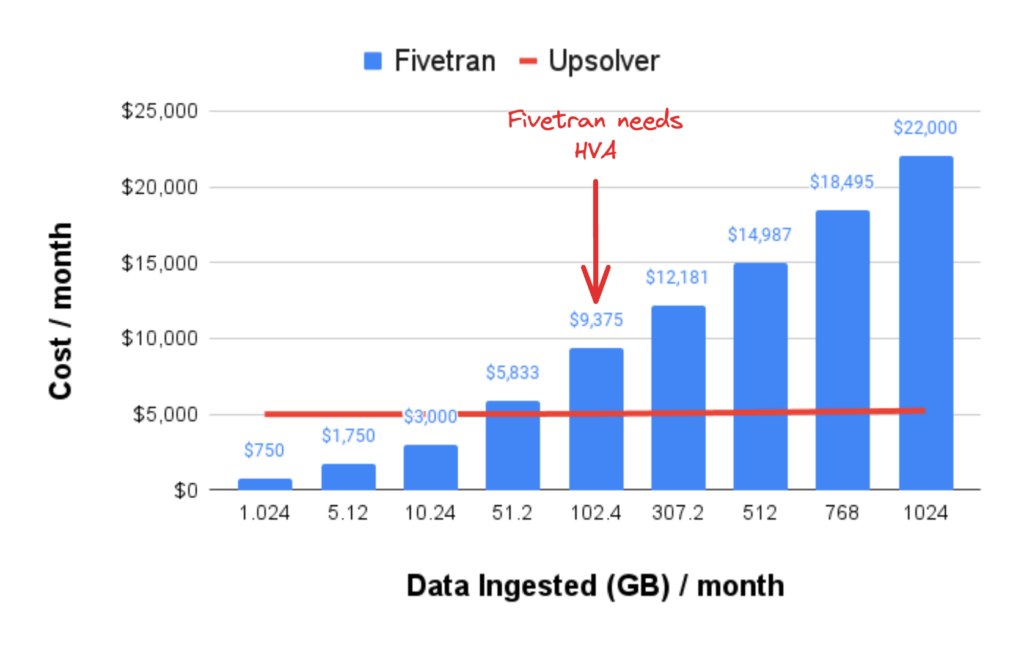
For high volume data movement, starting at ~10MM rows per table, Fivetran’s Teleport sync using full table snapshots and incremental loads fails to scale cost effectively and puts undue stress on your source database. Fivetran also offers a High Volume Agent (HVA) for CDC workloads with typically over 100MM row changes per month. This option comes at an additional cost and requires installing a custom agent on your source database, opening you up to potential security risks and operational challenges.
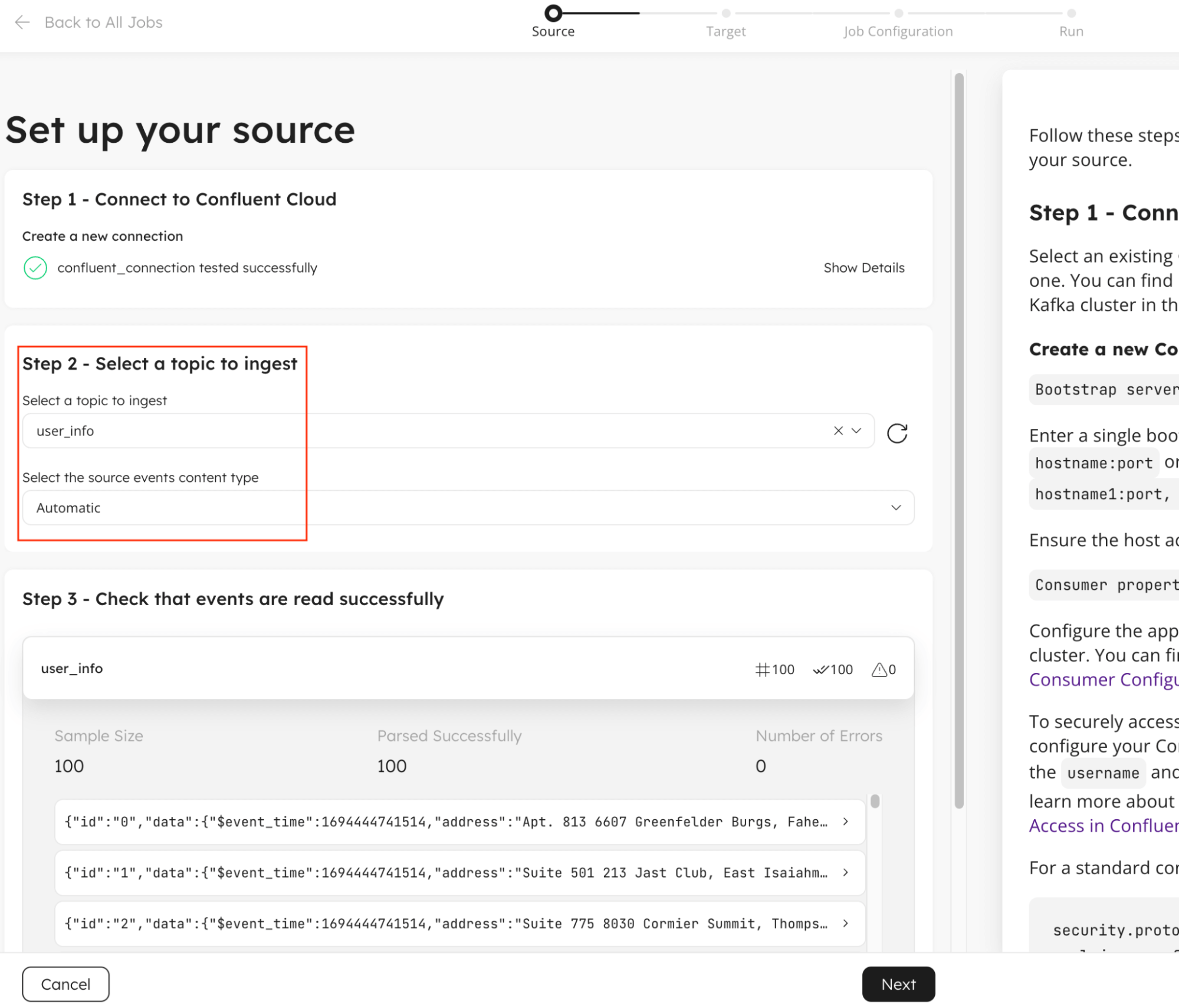
Upsolver’s CDC solution leverages the battle-tested open source Apache Debezium core engine integrated with our shared-nothing distributed processing architecture to provide the most scalable solution on the market for replicating data with no additional agents or fees.
Upsolver charges a nominal platform fee for core features and a fee per TB of data ingested, starting at $225/TB per month for a standard edition – visit the pricing page for more detail. With Upsolver, you can easily predict your cost by simply monitoring the bytes consumed – no convoluted MAR math. Since rows are often very small, averaging ~1KB per row, the total data moved per month remains consistently low; as with anything, your experience may vary – need help figuring all of this out? Talk with our SAs, no strings attached.
Book a meeting with our Solution Architects to see how you can reduce your Fivetran bill for CDC workloads.
Continuous ingestion of semi-structured files from object stores
Cloud object stores like Amazon S3 serve as a cost effective and highly scalable landing zone for files used in analytics and ML. Companies commonly need to manage either many small append-only files like those produced by logging, security and ad tracking systems, or few large frequently updating files like those including product catalogs, inventories, and data dumps from legacy systems (AS400, DB2, etc.).
Fivetran’s MAR-based pricing is not designed for file-based data movement.
Append-only use cases producing millions of small files is akin to streaming and are penalized by Monthly Active Row pricing because each row’s primary key is a combination of the filename and row number, which results in a unique PK for every row.
Large, frequently changing files like product catalogs and inventories must be re-sync’ed in their entirety every time one or more rows are modified. Although unique rows are only counted once per month, frequent changes over the lifetime of a file will result in constantly paying for unnecessary and redundant MARs.
Upsolver’s volume based pricing is predictable and cost effective for file based data movement. It is not sensitive to number of files or frequency of changes, making it economical for you to scale.
High-volume data movement isn’t a common use case for Fivetran customers. Published data movement stats across their entire customer base demonstrates this aspect.
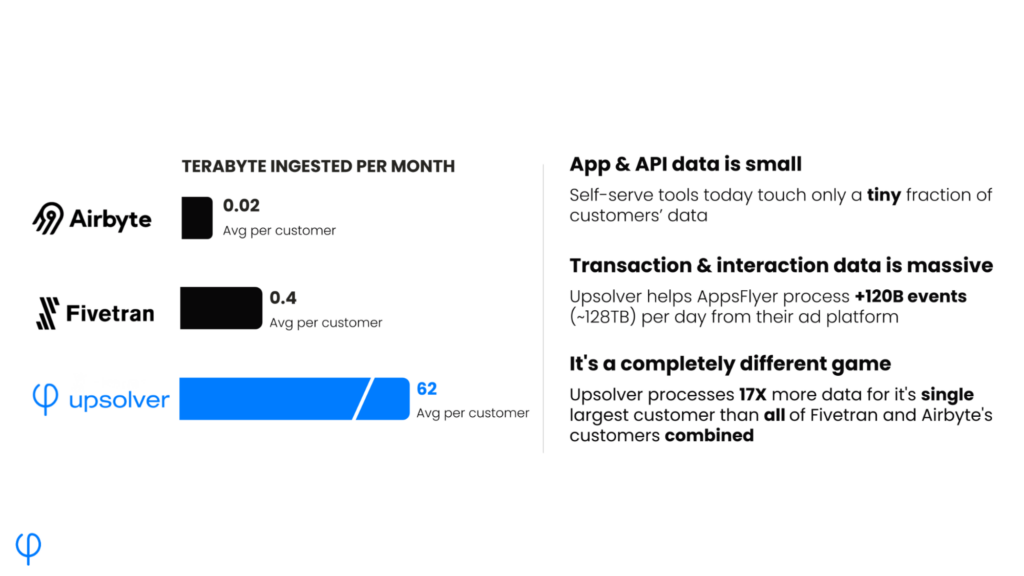
Upsolver is designed to move vast amounts of data, whether concentrated in a few large files or spread across millions of small files. Upsolver can automatically detect files in your bucket or be notified of changed files via a queue like Amazon SQS. Upsolver’s pricing is not bound to number of files or monthly changes so you’re free to manage your data however you want without being penalized.
Book a meeting with our Solution Architects to see how much you can save with Upsolver.
Stream application and security events to your warehouse or lake
Streaming sources like Amazon Kinesis and Apache Kafka are popular ways to ingest interaction data like, clickstream, purchasing activity, ad impressions and clicks, and intrusion detection events. These events are most valuable as soon as they are generated and begin to lose their value soon after.
Kafka and other streaming brokers use offsets in a stream to uniquely identify a message without needing to unpack its content. This means that offsets are guaranteed to be unique within a partition.

To calculate MARs, Fivetran counts the number of primary keys in a stream derived from joining the stream’s partition value and message offset – the message’s numerical position in the stream.
Since offsets are guaranteed to be unique, you are guaranteed to pay for every single message consumed from a stream using Fivetran.
Upsolver charges by the amount of data consumed, saving you tens of thousands of dollars. In the case of streaming this is easily calculated by multiplying the number of events by their size in bytes. For truly high volume streaming workloads, Upsolver offers volume discounts where applicable.
Book a meeting with our Solution Architects to see how you can cost effectively scale your streaming ingestion workloads.
Upsolver is designed and priced specifically for high-volume, high-scale data ingestion workloads. With Upsolver you get more than 76% lower prices than Fivetran for production grade CDC and file-based data ingestion, and more than 90% lower prices for streaming workloads. It’s a no brainer!