
Explore our expert-made templates & start with the right one for you.
Table of contents
Intro
Amazon Athena is one of the fastest growing services in AWS. But what types of use cases is it best suited for, and how does it fit in with the broader cloud ecosystem?
With the broad range of databases, analytics tools and query engines available, it can be daunting to understand when you should use Athena and when you should choose another tool such as Amazon Redshift, and how to successfully implement Athena to get the most value out of it.
In this guide, we’ll review 5 case studies of companies that have been very successful with Amazon Athena – including Cox Automative, Sisense, and others – so you can learn exactly how they did it.
1. Real-Time Insights from Streaming Data
The challenge
The Meet Group, a leading provider of interactive online dating solutions, was dealing with common data infrastructure ‘growing pains’. The company through acquisitions, and with each acquisition the data team had to manage different data pipelines.
Given the streaming nature of the data, The Meet Group sought to find a solution to integrate its data pipelines and central data collection to drive better real-time aggregate insights and analysis.
The solution
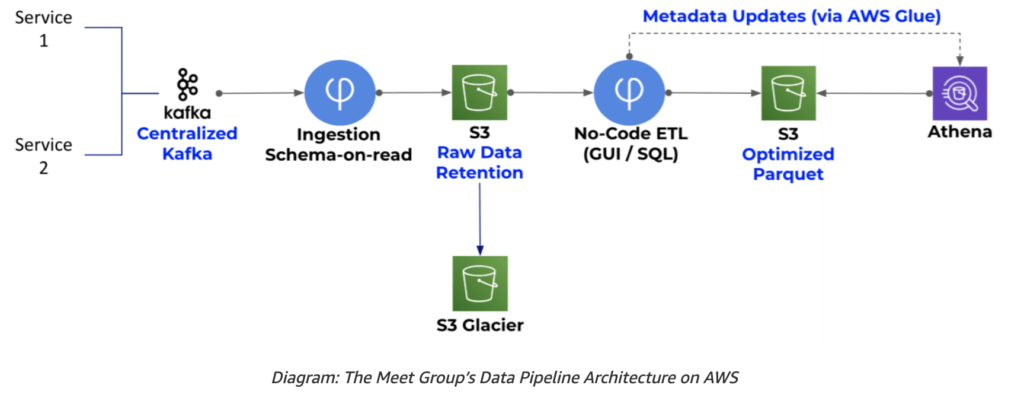
The Meet Group leverages Upsolver as a real-time collection and transformation engine that connects data producers such as Apache Kafka, Amazon Kinesis, and operational databases to analysis tools such as Amazon Athena, Amazon Redshift, and Amazon Elasticsearch Service. By choosing a data lake on AWS, The Meet Group can leverage the best tool for each analytics and data science use case, using Upsolver for scaling and optimizing the data pipelines automatically to meet their business demands.
Why Amazon Athena?
Since Athena queries data directly from Amazon S3, The Meet Group can consolidate large volumes of streaming data on an S3 data lake rather than struggle with the complexity of managing streaming data in a database or data warehouse. Since Athena is serverless, it allows an already-stretched data team to focus on analytics rather than data pipelines, which gives analysts the ability to query data across multiple sources in near-real time.
How Upsolver helps
Upsolver ingests data to Amazon S3 and extracts a strongly typed schema-on-read which is updated in real time and presented in Upsolver’s visual user interface. In turn, The Meet Group users create data transformation jobs by mapping the schema-on-read to tables in various analytics tools. The syntax for these jobs is SQL-based and each job can mesh multiple data sources into a single table. Once the jobs are run by the user, Upsolver continuously updates the target tables and data becomes queryable in Athena. The data Upsolver creates for Athena is optimized for faster queries by using columnar formats such as Apache Parquet, compression, partitioning, and compaction of small files. The metadata for Athena tables is maintained by Upsolver in the AWS Glue Catalog.
2. Big data analytics
The challenge
Browsi provides an AI-powered adtech solution that helps publishers monetize content by offering ad inventory-as-a-service. As an AI company, data is at the heart of all of Browsi’s operations. The company processes over 4bn events per day, generated from the Javascript-powered engine it hosts on publisher websites. The company uses this data for analytics – internal and customer-facing dashboards, as well as data science – refining the company’s predictive algorithms.
Working with data at this scale is always challenging from an ETL perspective. The company had built its data lake infrastructure on ingesting data from Amazon Kinesis via a Lambda function that ensured exactly-once processing, while ETL was handled via a batch process, coded in Spark/Hadoop and running on an Amazon EMR cluster once a day. .Amazon Athena was used to query the data, and due to the batch latencies, the data in Athena was either up to 24 hours old, or expensive and slow to query as it had not yet been compacted
The solution
Events are generated by scripts on publisher websites, which are streamed via Amazon Kinesis Streams. Upsolver ingests the data from Kinesis and writes it to S3 while ensuring partitioning, exactly-once processing, and other data lake best practices are enforced.
From there, the company built its output ETL flows to Amazon Athena, which is used for data science as well as BI reporting via Domo. For internal reporting, Upsolver creates daily aggregations of the data which are processed by a homegrown reporting solution.
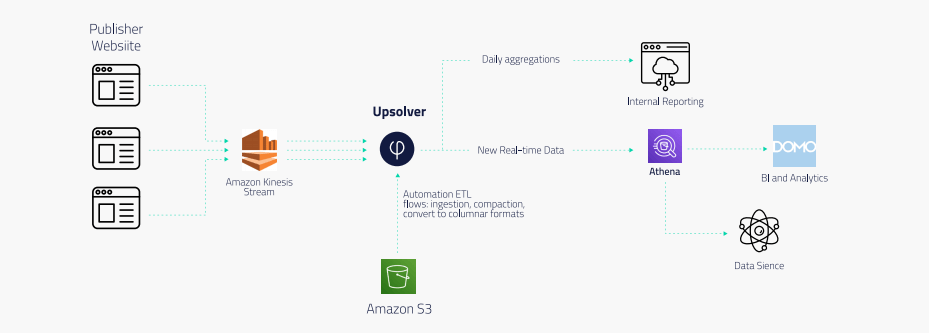
Why Amazon Athena?
Amazon Athena’s ability to query terabyte-scale data directly from the data lake allows data scientists at Browsi to pull ad-hoc datasets for further research and model training, while the JDBC connectivity to Domo allows the data to be used for BI reporting – without the need to manage and operationalize a separate data warehouse infrastructure.
How Upsolver helps
The company implemented Upsolver to replace both the Lambda architecture used for ingest and the Spark/EMR implementation used to process data, transitioning from batch to stream processing and enabling end-to-end latency (Kinesis -> Athena) of mere minutes.
While the previous implementation was based on manual coding, Upsolver enables Browsi to manage all ETL flows from its visual interface and without writing any code. Data engineers are then free to spend their time developing features rather than infrastructure.
3. Log analytics and reducing Splunk costs
The challenge
Cox Automative provides a suite of digital tools that help bridge the gap between consumers, manufacturers, dealers, and lenders at every stage of the automotive experience. As part of a digital modernization, Cox Automative moved their data infrastructure to the cloud.
New cloud environments also allow Cox Automotive to onboard applications and data even faster than before, though the increasing data volume was not without its challenges:
- Exponential cost with rapid business and data growth: ingesting and storing data in its raw form is difficult due to high costs.
- Scalability with business growth: onboarding new applications is a long process that requires a dedicated team with an experienced coding background.
- Business agility: retention of data long-term is required to build machine learning models or replay data from its raw form when needed.
The solution
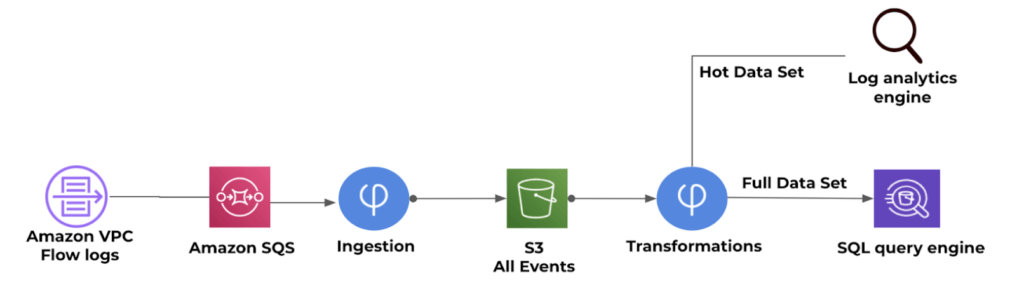
Upsolver and Amazon Athena are being used together to deliver an end-to-end solution for streaming data analytics that is quick to set up and easy to operate without coding. Upsolver processes the raw data to gain powerful visibility into the cloud operations to ensure application uptime and stability while minimizing costs by only ingesting relevant data into Splunk.
The architecture also scales elastically using cloud-native computing and storage without manual maintenance.
Why Amazon Athena?
Rather than spending hundreds of thousands of dollars to send raw VPC flow log data directly to a log analytics engin, Cox Automative moved to a cloud data lake architecture to store all log data in Amazon S3, query it with Amazon Athena using SQL, and push relevant data into Splunk when it’s needed to do a deeper dive into a security anomaly.
How Upsolver helps
Upsolver optimizes Cox Automotive’s data analytics and storage. Using its built-in ETL functions, the team at Cox Automative can easily create a reduced log stream for querying in Splunk, while the data on Amazon S3 is stored as optimized Apache Parquet that can be easily queried for ad-hoc analytics.
4. Product Analytics
The challenge
Sisense is one of the leading software providers in the highly competitive business intelligence and analytics space. Seeking to expand the scope of its internal analytics, Sisense set out to build a data lake in the AWS cloud in order to more effectively store and analyze product usage data. However, the rapid growth in its customer base created a massive influx of data that had accumulated to over 200bn records, with over 150gb of new event data created daily and 20 terabytes overall.
To effectively manage this sprawling data stream, Sisense set out to build a data lake on AWS S3, from which they could deliver structured datasets for further analysis using its own software – and to do so in a way that was agile, quick and cost-effective.
The solution
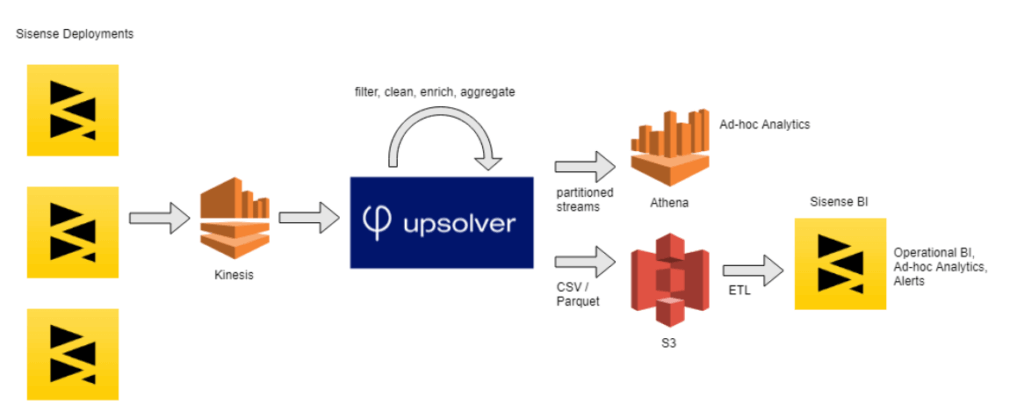
Using a combination of Athena, Sisense’s own BI software, and Upsolver allows different teams at Sisense to access product log analytics with regular SQL: from product managers having a better understanding of how the software is being used, through sales representatives gaining real-time insights into prospect behavior, to data scientists working on machine learning algorithms.
Why Amazon Athena?
Amazon Athena was chosen for its ability to query event data from S3, even at larger scales, and to quickly provide answers to ad-hoc queries. Since product logs are semi-structured and land with evolving schema, data lake storage is the ideal solution to avoid complex ETL processes on ingest – and Athena provides a way to make this data operational using SQL.
How Upsolver helps
Upsolver’s ability to rapidly deliver new tables generated from the streaming data, along with the powerful analytics and visualization capabilities of Sisense’s software, made it incredibly simple for the Sisense team to analyze internal data streams and gain insights from user behavior – including the ability to easily slice and dice the data and pull specific datasets needed to answer ad-hoc business questions.
5. Replacing an on-premise enterprise data warehouse
The challenge
Peer39 is an innovative leader in the ad and digital marketing industry that provides page level intelligence for targeting and analytics. Each day, Peer39 analyzes over 450 million unique webpages holistically to contextualize the true meaning of the page text/topics
The company had been using IBM Netezza for the past 10 years. As the system approached end of life support, Peer39 decided to reevaluate their technology stack. Their legacy process and technology stack presented many challenges, including limited data availability, lack of accuracy, and lack of business agility.
The solution
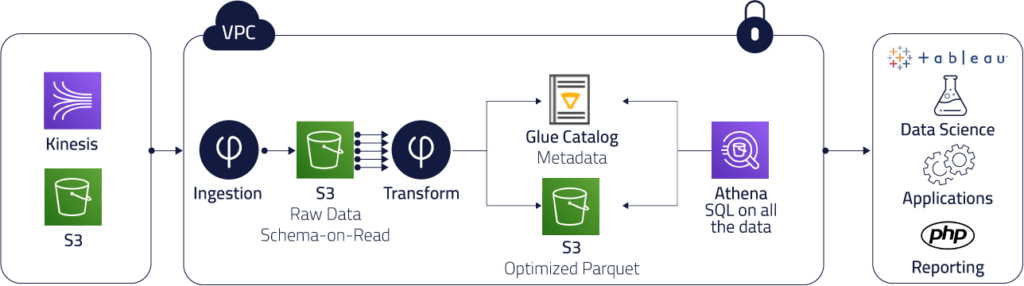
Moving their data infrastructure from on-prem Netezza to a cloud data lake built on Upsolve, Amazon S3 and Amazon Athena gave Peer39 a cloud-native, data stream processing platform with an easy-to-use UI.
Instead of relying solely on Netezza for storage and transformations, with all the limitations that created, Peer39 deployed a modernized data stack in the cloud – with the raw event data stored on Amazon S3, and then curated using Athena for further reporting, analytics and data science.
Why Amazon Athena?
Using Athena’s serverless querying capabilities, the Peer39 can pull whatever data they need for further analysis or operations. Rather than the constant need to manage infrastructure and the delays involved in data warehouse batch processing, data can easily be extracted from the lake and to other databases and query engines, whenever the business needs it.
How Upsolver helps
Upsolver is unifying teams across data scientists, analysts, data engineers and traditional DBAs, enabling Peer39 to speed go-to-market with existing staff. After a thorough comparison with Apache Spark, Peer39 went with Upsolver due to its superior scalability, performance shorter time-to-analytics.