Explore our expert-made templates & start with the right one for you.
Videos
Learn more about Upsolver's data pipeline platform through our many videos.
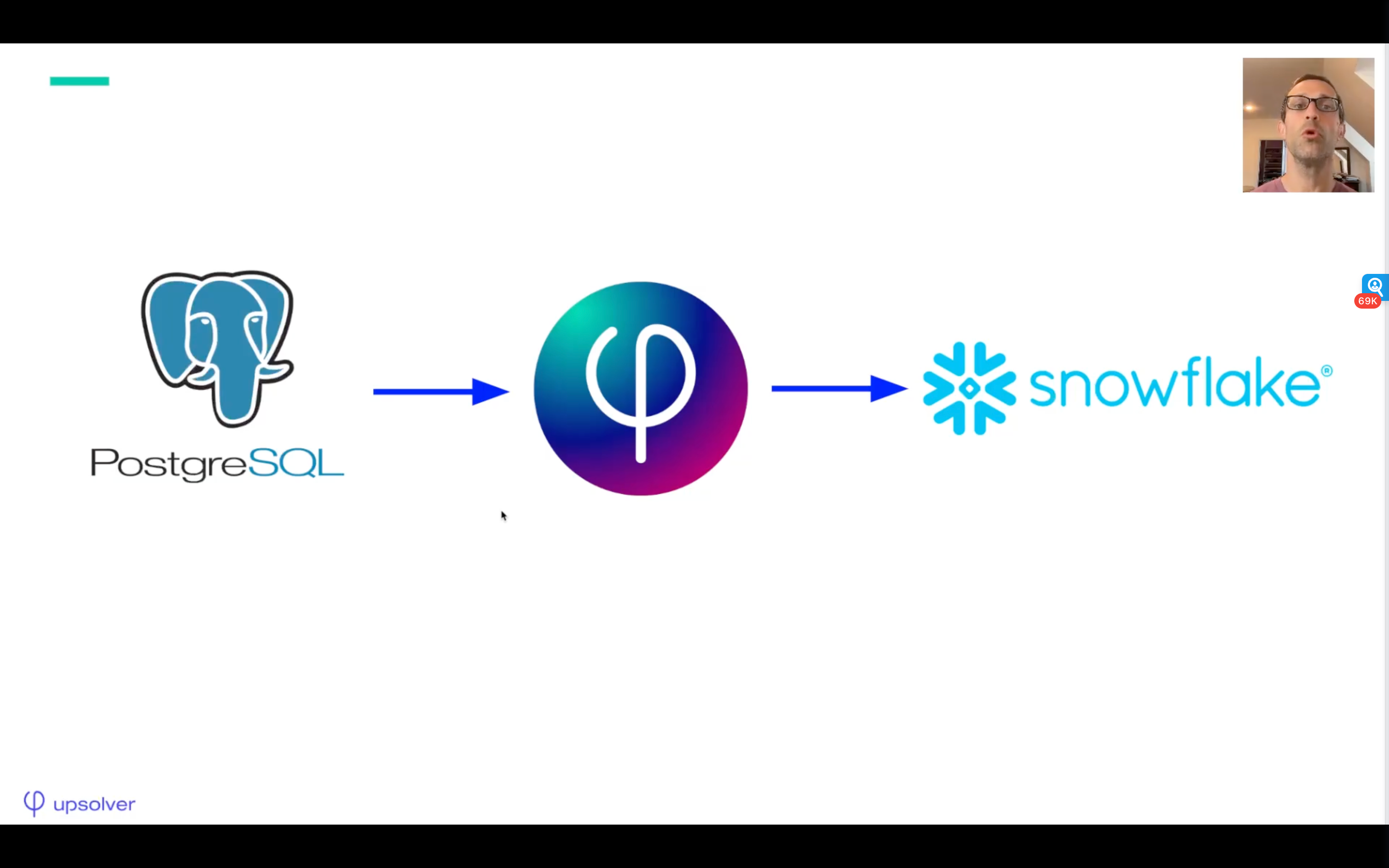
Production-grade Database Replication from PostgreSQL to Snowflake in Minutes with Upsolver
With Upsolver, you can build pipelines for to replicate production-grade PostgreSQL databases to Snowflake in 10 minutes or less. Upsolver guarantees your PostgreSQL data will always be on-time, exactly once and strongly ordered in Snowflake.

Getting Production-grade Data from Kafka to Snowflake in Minutes with Upsolver
With Upsolver, you can build pipelines for production-grade Kafka data to Snowflake in 10 minutes or less. Upsolver guarantees your Kafka data will always be on-time, exactly once and strongly ordered in Snowflake.
Introducing Automated Ingestion for dbt Core with Upsolver
Data and analytics engineers can easily build and deploy extract and load tasks in dbt Core using Upsolver. Upsolver is a simple to use data ingestion solution that continuously loads fresh and high-quality data from object stores, operational databases and streams into your warehouse and lake.
Simplifying Reliable Data Ingestion for Snowflake
Upsolver's data ingestion platform enables high quality, observable data ingestion from streams, files, and operational databases for the Snowflake Data Cloud. Roy Hasson, head of product at Upsolver, shows how you can now easily build dbt Core models that deploy data movement tasks on Upsolver, bringing software engineering best practices to data ingestion for the first time.

Stream of Consciousness | Disaster Recovery
Learn how Upsolver has adapted best practices for disaster recovery to streaming data from sources such as Kafka and Kinesis so your data architecture is always resilient.

Stream of Consciousness | Streaming Joins and Aggregations
Learn how Upsolver performs joins and aggregations efficiently on massive data in motion.

Stream of Consciousness | Incremental Models with dbt
Upsolver CTO and Co-Founder Yoni Eini and Head of Data Santona Tuli break down incremental models — why we need them and why they’re difficult to write.

Stream of Consciousness | Strong Ordering of Data
Data ordering is a prerequisite for exactly once processing. Watch to find out how Upsolver solves this difficult problem.

Stream of Consciousness | Exactly Once Processing
Yoni and Santona explain how Upsolver has implemented effective exactly once processing by leveraging idempotency — the concept that a repeated process should always produce the same result — and at least once processing.

Stream of Consciousness | Types of Streaming
Upsolver CTO and Co-Founder Yoni Eini and Head of Data Santona Tuli explore the most common types of streaming data organizations encounter.

Stream of Consciousness | Realtime
Upsolver CTO and Co-Founder Yoni Eini and Head of Data Santona Tuli dive into the definitions of realtime and how they relate to data ingestion and analytics.
Upsolver SQLake Demo | Change Data Capture
See how easy it is to continuously stream change logs for database replication from relational databases.

Designing and Implementing Data Mesh
Learn practical approaches you can implement today to help your company start benefiting from Data Mesh.

Introducing Upsolver SQLake. Build Pipelines. Not DAGs.
Upsolver SQLake unifies batch and streaming pipelines in a single data pipeline platform with no manual orchestration.

CTO Lunch and Learn | Pipeline Synchronization
Join Upsolver CTO Yoni Eini to learn how we automate synchronizing pipeline tasks to guarantee strong consistency.

CTO Lunch and Learn | Time Consistency in Stream Processing
Join Upsolver CTO Yoni Eini to learn how to ensure events are properly ordered in Upsolver's stream processing engine.

CTO Lunch and Learn | State Store Management
Join Upsolver CTO Yoni Eini to learn how we automate state score management at scale.

CTO Lunch and Learn | Orchestration
Learn from Upsolver CTO Yoni Eini about automating orchestration of pipeline tasks as data velocity increases fro daily to minutes.

Ending DAG Distress
Building Self-Orchestrating Pipelines for Presto
Upsolver Workshop
Learn to deliver analytics-ready data from batch & streaming sources with no manual orchestration
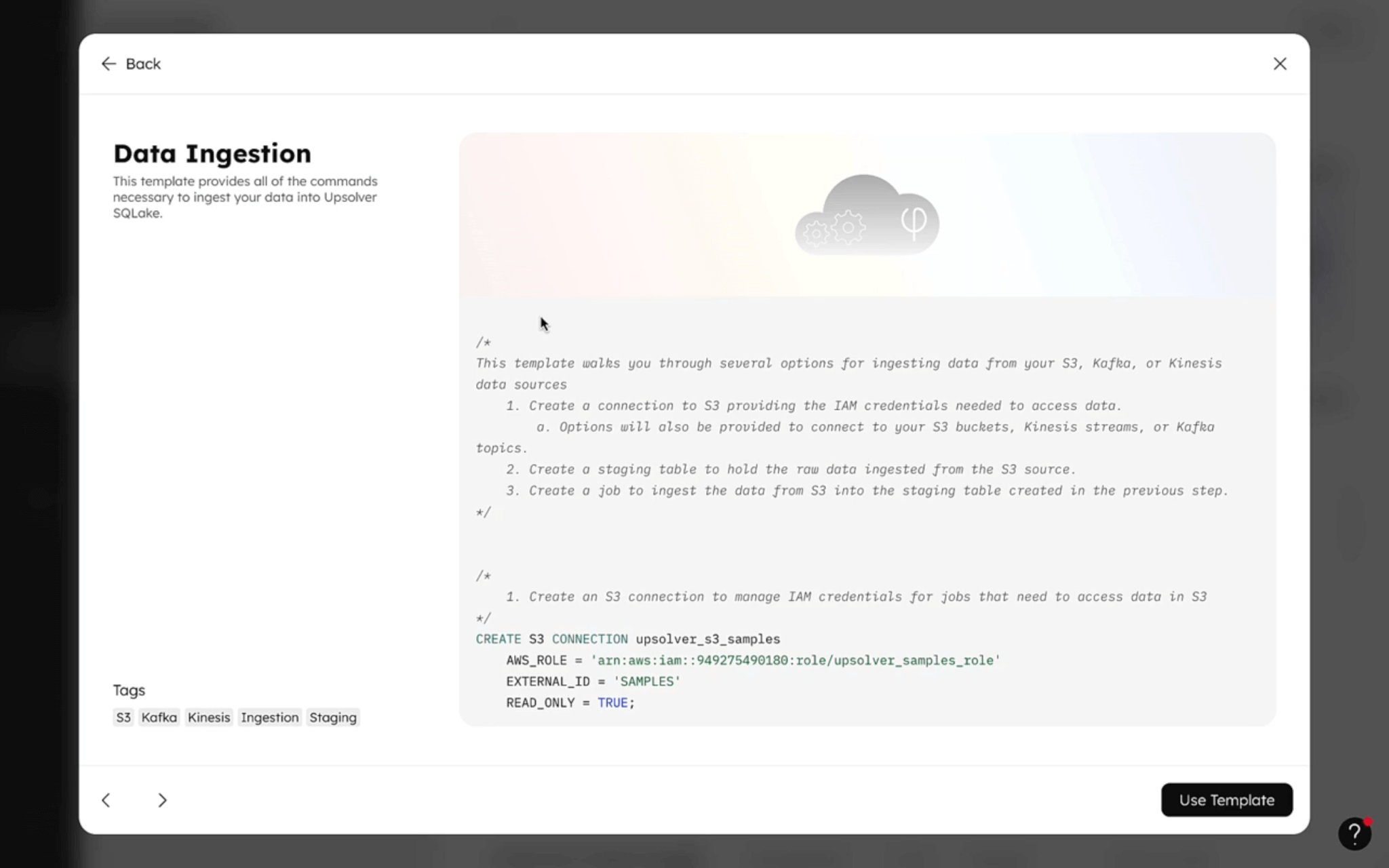
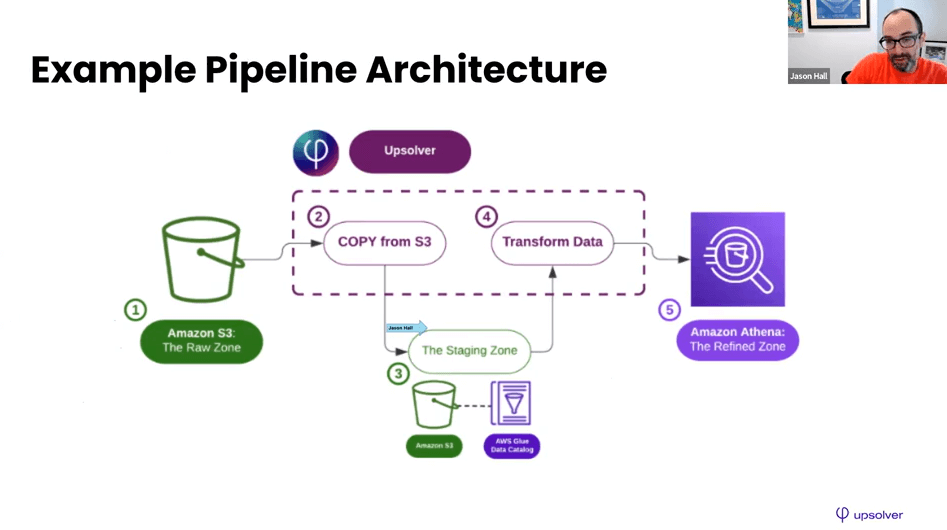
Upsolver SQLake Tutorial | Data Ingestion
This brief demonstration walks through the first part of building a declarative data pipeline: Ingesting data into SQLake.
Upsolver SQLake | Interface Walkthrough
Watch this guided product tour to see how SQLake connects, transforms and delivers analytics-ready data.
ironSource Built a Streaming Data Lake for Ad Data
ironSource managed to transform 500K events per second, using only a visual interface and SQL, saving thousands of engineering hours.

Create and Curate a Simple Data Pipeline
In this brief video, we demonstrate in real-time how easy it can be to build, enrich, preview, and go live with a complete streaming data pipeline
Go From Nested Data Arrays to Flat Tables for Athena
Discover how Upsolver helps you take streaming nested data containing arrays and prepare it for Amazon Athena.
Create a Streaming Data Pipeline for Product Analytics
Watch this video to see how quickly you can build a data pipeline and begin analyzing data from your data lake

Upsolver product demo: data lake engineering made easy
See how you can combine data lake economics with database simplicity and speed, and simplify your cloud analytics initiatives

Ingest & analyze Salesforce data with Upsolver on S3
We walk you through the architecture and detailed steps to ingest data from Salesforce to an Upsolver-enabled Amazon S3 bucket.
Upsolver: Make your data lake analytics-ready
Take this quick tour of Upsolver's capabilities and see how you can combine data lake economics with database simplicity and speed.
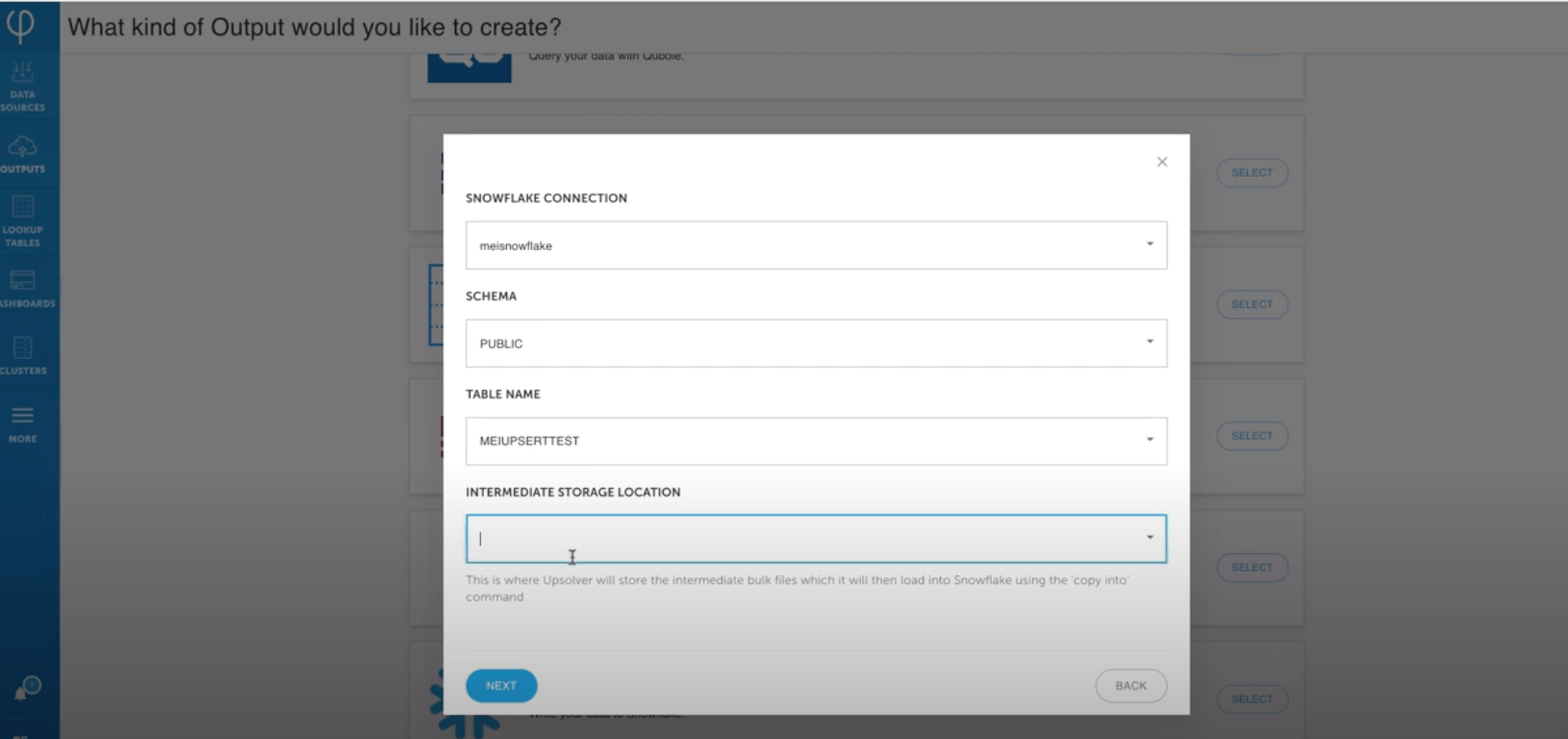
Load CDC data to Snowflake database
Upsolver can load data into many databases including Snowflake. This video guide shows you how to create a Snowflake data output.
Using Upsolver to index less data into Splunk
Many users are looking for ways to reduce their Splunk cost. This video provides an example of how to index less data into Splunk.

Finding the Needle in the Data Lake Haystack without Code
Learn how to set up & operate a data lake using Upsolver, query it from Athena, & visualize anomalies with Looker - with no code.
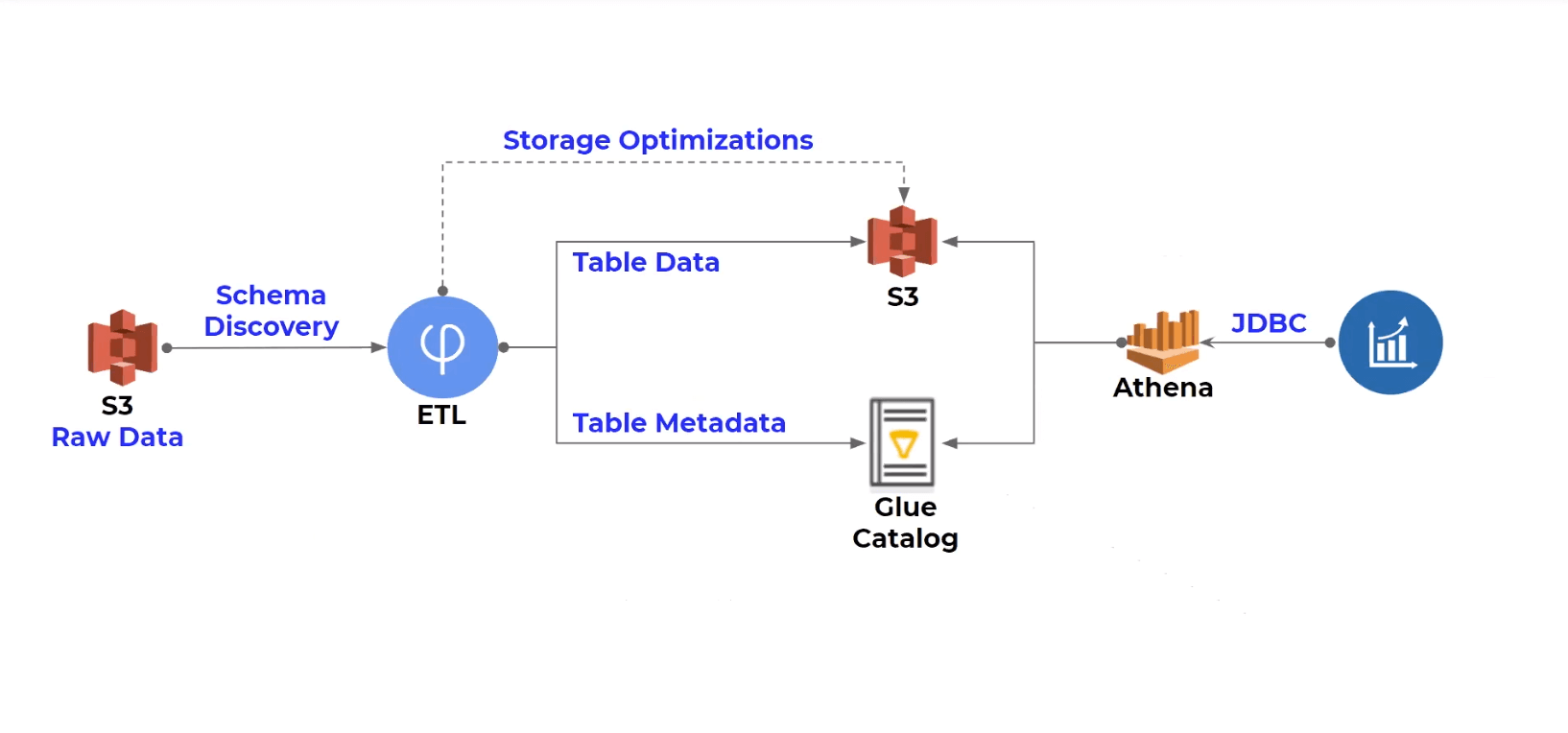
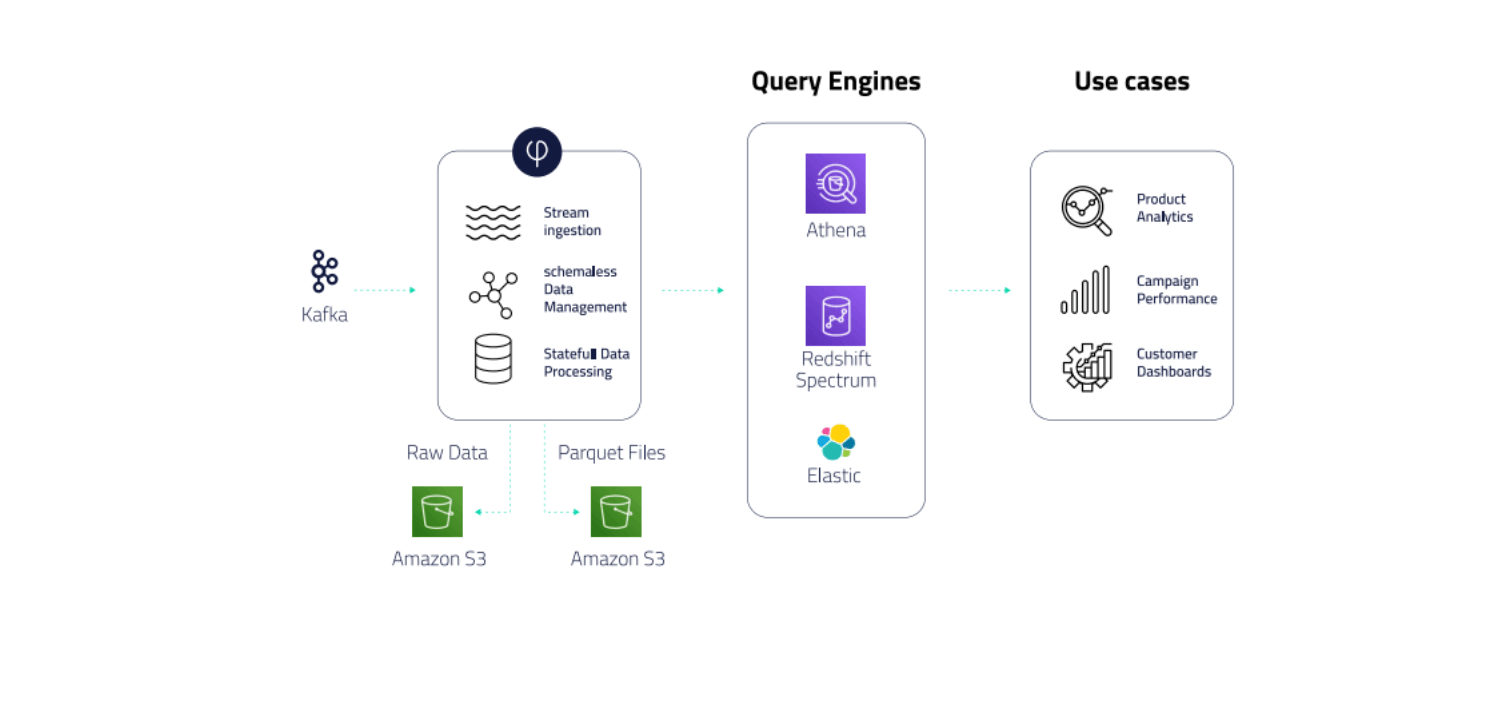
ETL for Amazon Athena: 6 Things You Must Know
Amazon Athena is a powerful tool, but the way you build your ETL pipeline can have a major impact on the costs.
Frictionless Data Lake ETL for Petabyte-Scale Streaming
Transform 500K events per second, using only a visual interface and SQL, saving thousands of engineering hours.