Explore our expert-made templates & start with the right one for you.
Unblock Data Engineering with Declarative Pipelines and No Orchestration
In data-intensive organizations, data engineering often becomes a bottleneck. The variety of data sources keeps growing, as does the demand for pipelines – which often must be hand-coded – to utilize this data across a growing number of analytics systems. However, there is a shortage of data engineers that exceeds even the well-documented dearth of data science talent. This data engineering squeeze results in lengthy projects and delayed delivery of value.
Upsolver Eliminates Time-Consuming and Tedious Data Pipeline Tasks
Upsolver customers see a substantial productivity boost to their data engineering function and tremendous acceleration of their data pipeline projects. Upsolver’s use of SQL for transformations and automation for pipeline orchestration means they can go from inspiration to production in weeks, whereas hand-coded, manually-orchestrated data lake pipelines commonly take months or quarters.
Any Transformation using SQL instead of Code
Use familiar SQL to specify how you want to transform your data, with over 150 standard functions plus extensions for stateful operations on streaming data. A dual-mode synchronized IDE lets you smoothly switch between drag-and-drop fields and operations or writing SQL. And you can plug in your own custom Python when needed.
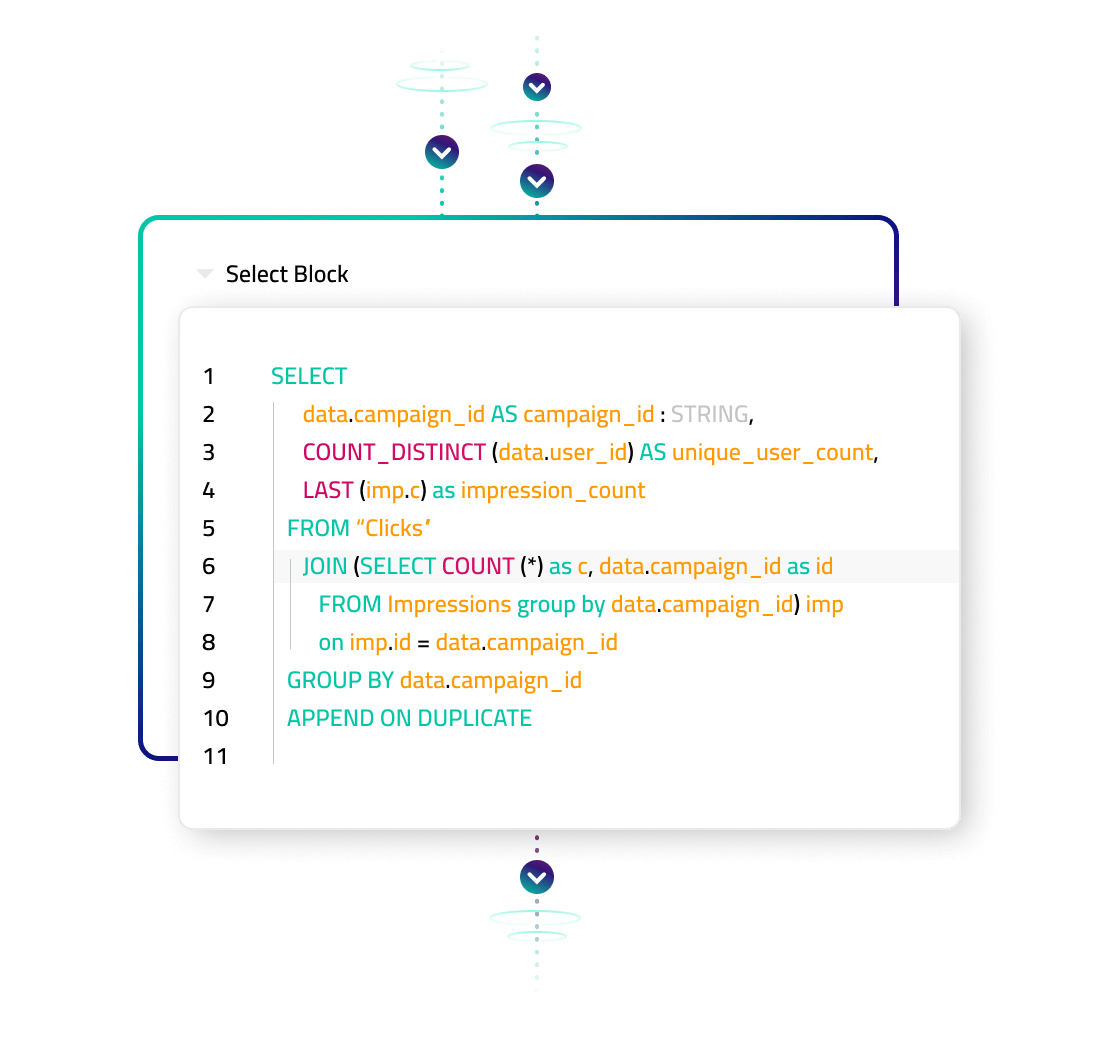
Automated Orchestration (no DAGs)
Traditional approaches to building data pipelines require stitching together a DAG of all the tasks required to execute the pipeline. Upsolver automates orchestration based on big data engineering best practices. You simply define your query visually or in SQL, and then we handle the rest, from the order of operations to the scheduling of the underlying file system optimization and maintenance operations in order to continually execute with performance.
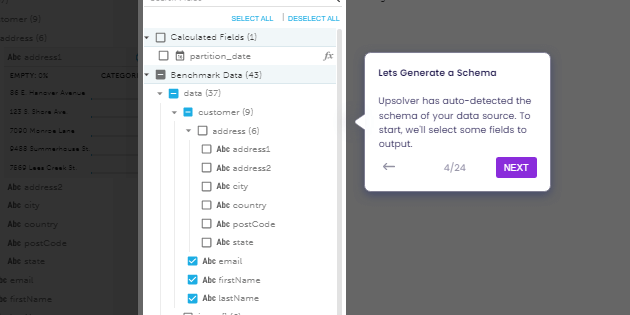
Automatic Schema Evolution and Data Profiling
Upsolver analyzes source data and infers the schema, including detecting changes such as new fields or changed data types. It visually displays the schema and provides profile statistics such as density and cardinality to ease modeling data and building transformations.
Automatic Table Optimization and Data Retention
Upsolver automates the management and optimization of output tables. Data engineers don’t need to build the “ugly data plumbing” needed to get to production, such as:
- Partition data
- Convert to column-based format
- Optimize file size (compaction)
- Upserts and deletes
- Vacuum stale and temporary files
Fully-managed Infrastructure and Auto-scaling
Upsolver is cloud-native fully managed data infrastructure. It deploys to your VPC, so your data stays in your control while Upsolver manages service availability and quality. Upsolver instances scale automatically, up to 1000s of nodes, based on your workload.








Explore Upsolver your way
Try SQLake for Free
SQLake is Upsolver’s newest offering. It lets you build and run reliable data pipelines on streaming and batch data via an all-SQL experience.
Talk to a Solutions Architect
Schedule a quick, no-strings-attached with one of our cloud architecture gurus.
Customer Stories
See how the world’s most data-intensive companies use Upsolver to analyze petabytes of data.
Integrations and Connectors
See which data sources and outputs Upsolver supports natively.