Explore our expert-made templates & start with the right one for you.
The Only AWS-recommended Partner for Amazon Athena
Make AWS Athena faster, easier and better with Upsolver’s no-code data lake engineering tools.
- 95% reduction in ETL development time
- 100x faster queries
- 10-20x cost reduction
Why Upsolver + Amazon Athena
Amazon Athena is powerful alone; with Upsolver, it’s a beast. Use a visual and SQL-based interface to easily create Athena tables directly from streaming data stored on S3, and watch your queries run faster than you ever thought possible thanks to Upsolver’s groundbreaking ETL technology and deep integration with the AWS data lake ecosystem.

Reference Architecture
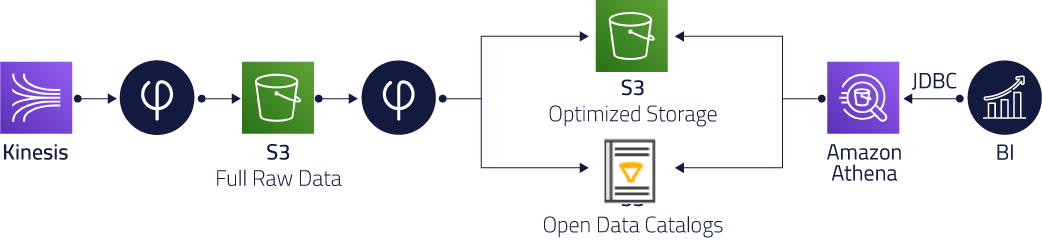
Improve Query Performance
Read optimized Parquet instead of raw JSON.
Upsolver ingests streaming and batch data and stores it on S3 in an optimized file system based on Apache Parquet. Small files are compacted under the hood with zero coding required.
Simplify File Management on your Data Lake
Self-service custom partitioning. No coding required.
Using nothing but Upsolver’s visual UI, you can choose to partition data by actual event time as well as by custom field within an event stream.
Model and Re-model your Data
Easily edit tables in Athena with SQL or drag-and-drop.
Add or remove columns from any Athena tables and apply these changes retroactively without missing a beat, and with every change instantly reflected in the Glue Data Catalog.
Query Data in Near Real-time
Make the leap from batch to streaming ETL.
Upsolver lets you skip the latencies generated by batch processing using Spark platforms, and enables you to query streams directly in Athena in real-time.
Time Travel on S3
Instant backfill to reflect historical data stored on your data lake.
Create tables using raw historical data stored on S3 in one click for instant historical replay. If the data is there, you can see it in Athena.
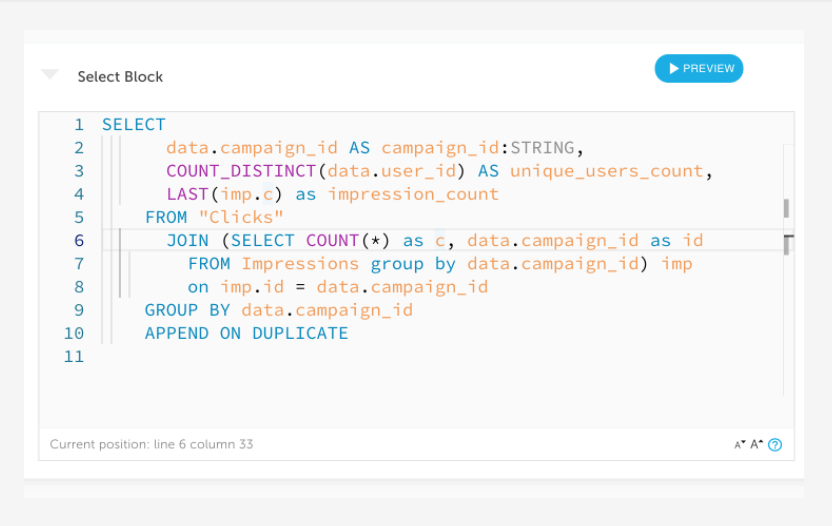
Combine Data In-flight
Join multiple streaming sources and big tables
Familiar SQL editor allows you to create custom tables on the fly, from two or more disparate event streams, as well as perform joins between streams and large tables – without sacrificing performance.
Learn More about Upsolver and Amazon Athena.
Live Workshop
Learn how to build a working Lake House architecture with Upsolver, Kinesis and Athena.
Save your seat
Start for free - No credit card required
Batch and streaming pipelines.
Accelerate data lake queries
Real-time ETL for cloud data warehouse
Build real-time data products