Explore our expert-made templates & start with the right one for you.
TECHNICAL WHITEPAPER
Apache Kafka with and without a Data Lake
Apache Kafka is a cornerstone of many streaming data architectures – but what’s the next step? How do you build effective ETL flows, manage data and create scalable pipelines from Kafka to analytical tools?
GET THE WHITEPAPER
What will you learn from this whitepaper?
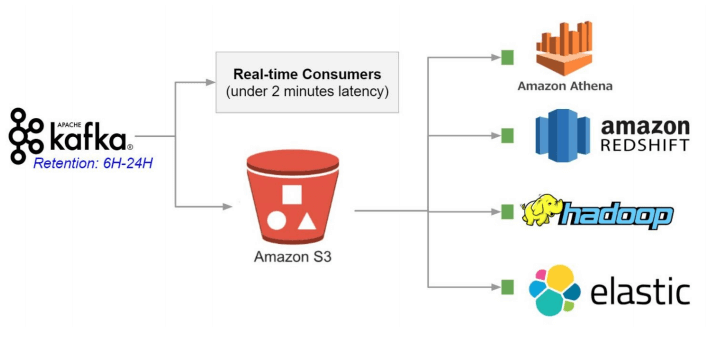
- Benefits of using a data lake such as Amazon S3 when working with Apache Kafka.
- Reading data directly from Kafka using SQL engines such as Presto or Amazon Athena, vs reading from a data lake.
- Kafka producer and consumer best practices.
- Use case and reference architectures.
- And more!
Powering data lakes for data-intensive companies
