Explore our expert-made templates & start with the right one for you.
The First Indexing Engine for Data Lakes
Query Amazon S3 by any set of keys at high-throughput and millisecond-latency using a REST API, without the overhead of managing any additional data stores.
Key Benefits
10-15x
More data in memory compared to NoSQL databases
50k
Reads per second, per server, at 1ms latency on average
100x
Faster time to production for real-time analytics and machine learning
What are Upsolver Lookup Tables?
Lookup Tables add indexing at high cardinality and performance to your data lake. They enable users to index data by a set of keys and then retrieve the results in milliseconds. Unlike NoSQL alternatives, Upsolver’s ETL platform stores indexed data on S3 rather than local servers, which turns IT-intensive cluster management into a non-issue. Lookup Tables leverage breakthrough compression technology and smart rollups that enable 10x-15x more data in-memory compared to alternatives.
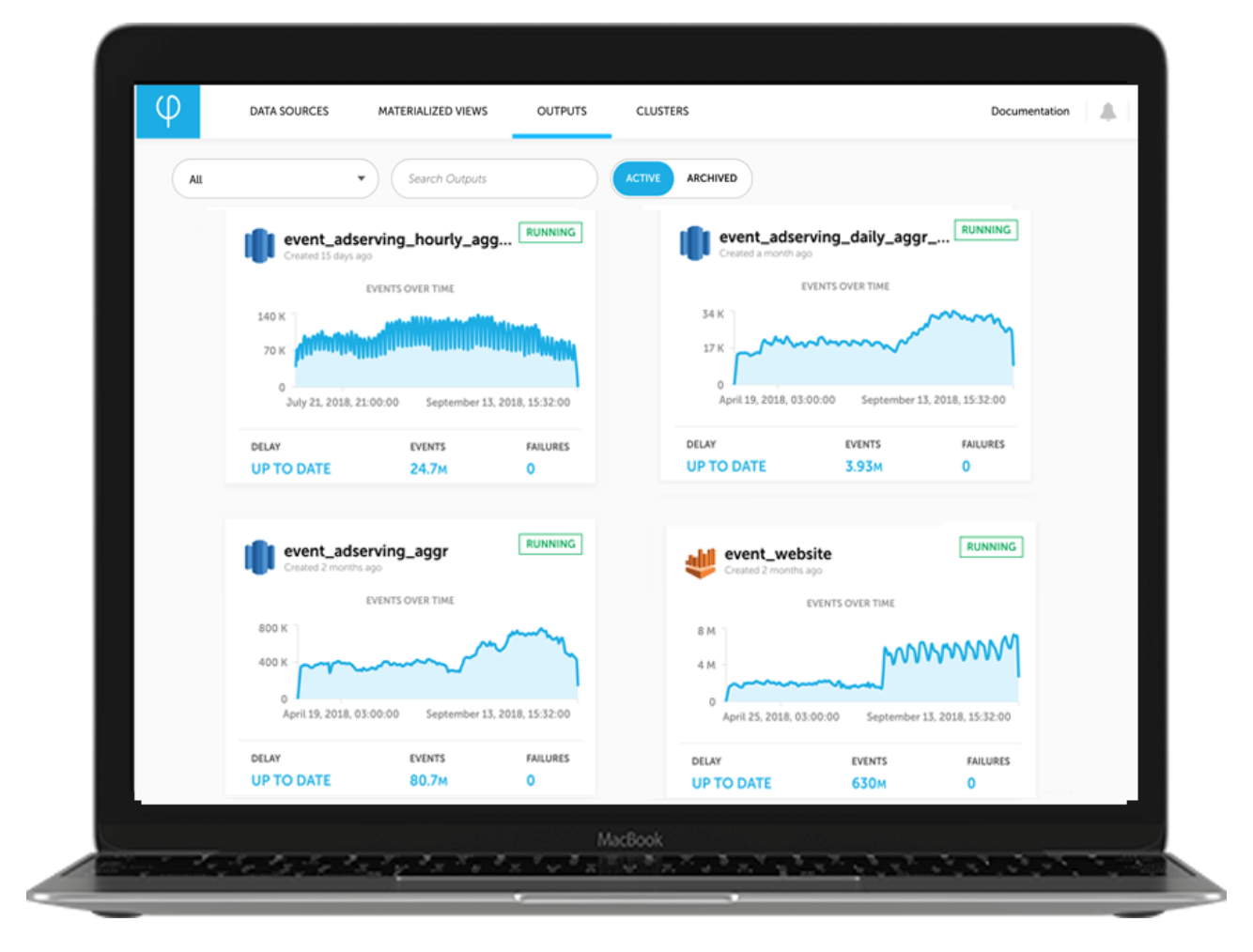
Key Benefits and Feature Highlights
Reduce 70-90% of infrastructure costs by storing more data in RAM
Decoupled compute and storage for easy healing, scaling, and disaster recovery
Easy to create without ETL coding or IT management using a self-service UI and UpSQ
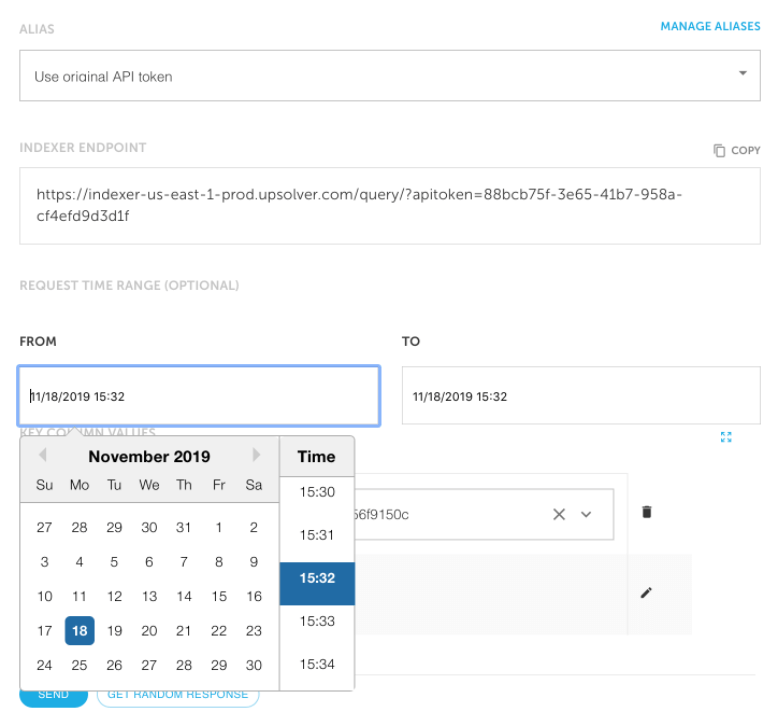
Query by any set of keys or time range.
Lookup Tables are stored on S3 as a time-series. Using smart rollups, Upsolver makes it possible to query any time range by any set of keys.
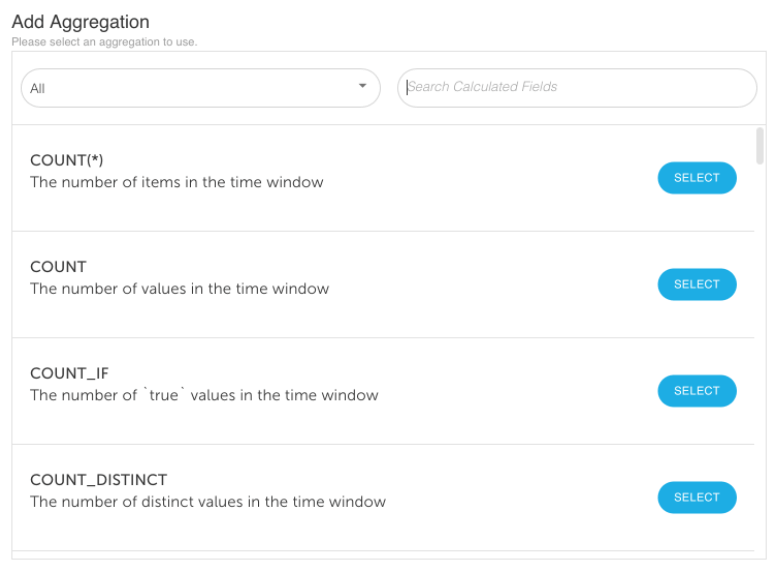
Rich library of out-of-the-box window aggregations
Capture real-time behavior for users and devices, using window aggregations, nested aggregations and time-series aggregations.
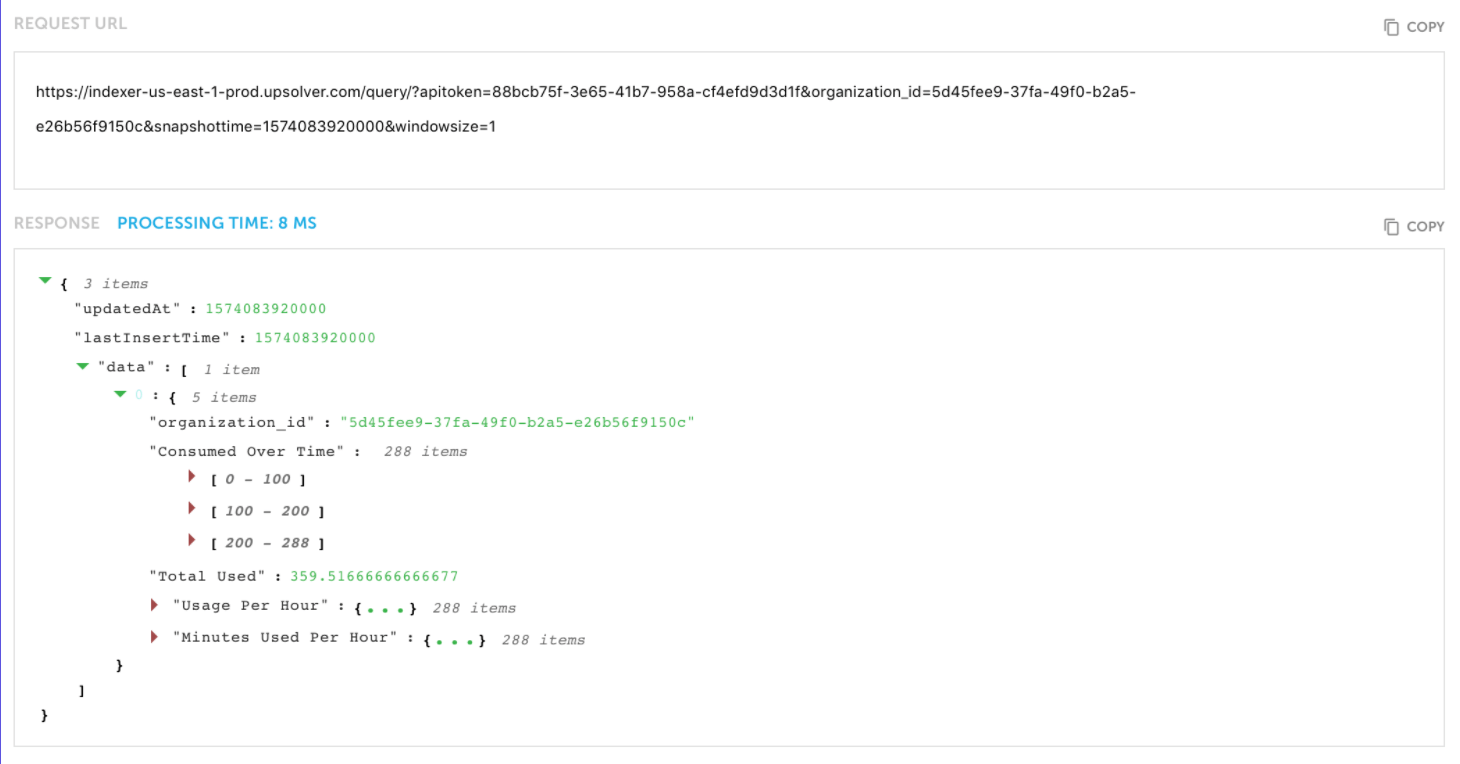
Simple REST API
Embed granular user or device data in your applications using a simple REST API and avoid the overhead of additional data stores.
Learn more:

ironSource built a multi-purpose data lake with Upsolver
Read this case study to learn how Upsolver helped ironSource save thousands of engineering hours and cut costs.

Partitioning Data on S3 to Improve Performance in Athena/Presto
Discover best practices you need to know in order to optimize your analytics infrastructure for performance.

AWS Athena Challenges & Best Practices
Learn how to avoid common pitfalls, reduce costs and ensure high performance for Amazon Athena.
Webinar: Improving Athena + Looker Performance
Instantly improve performance and get fresher, more up-to-date data in dashboards built on AWS Athena – all while reducing querying costs
