Explore our expert-made templates & start with the right one for you.
Making Product Data Available for AI and Analytics with Upsolver and Snowflake
CUSTOMER STORY
INDUSTRY:
HR Tech
SOLUTION:
Handle high-volume, rapidly changing data without a dedicated data engineering team
TECHNICAL USE CASE:
Evolve from basic internal reporting to powering real-time, AI-driven features
1 BI team member
Maintains and operates all data pipelines
4TB
events processed every day
100+
engineering hours saved
Startups are facing increased competitive pressures and need to deliver faster and better software, while maintaining a laser focus on their key differentiators. This means automating and simplifying as much of the data infrastructure work as possible, in order to focus on the innovation that the company brings to the table.
How can this play out in practice? Let’s take a look at a real-life example of how one AI startup managed to build a scalable data platform supporting its ambitious data requirements, without a single data engineer. This article is based on a conversation with an Upsolver customer.
The Use Case: Product Analytics, Customer-Facing Analytics, and AI
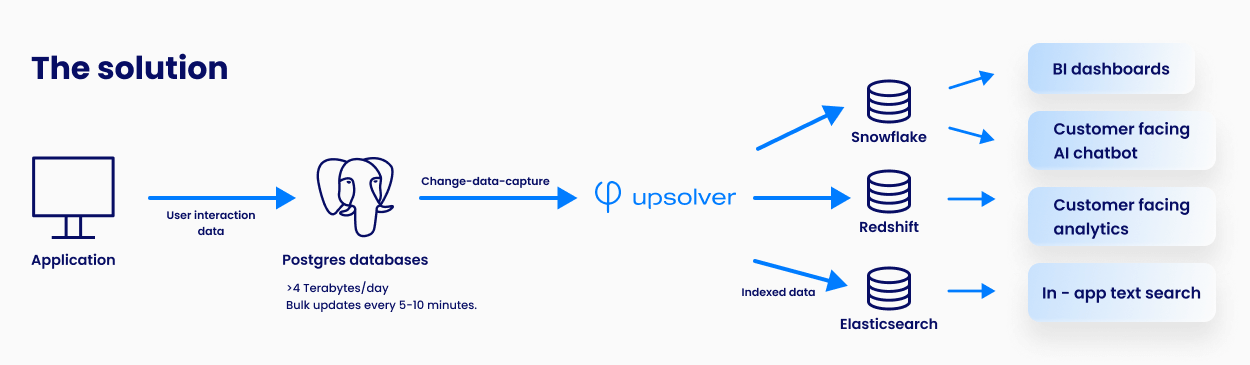
The startup, which is developing an AI powered SaaS tool in the human resources (HR) space, initially needed a simple data pipeline to support their internal product analytics, including the ability to report on key product metrics. As the first data and analytics hire, the Product Analytics Lead faced the challenge of centralizing data from various sources, including their primary PostgreSQL database, into the Snowflake data warehouse.
1 BI team member
Maintains and operates all data pipelines
4TB
events processed every day
100+
engineering hours saved

However, as we detail below, the use case quickly evolved beyond internal reporting. The startup recognized the potential of operationalizing their product data to create value-added features for their customers. This led to the development of customer-facing analytics tools and AI-powered features.
The Technical Challenge: How to Make Large Postgres Tables Available in Snowflake, in Near-Real Time
The startup faced a complex data engineering challenge typical of rapidly growing companies. Their primary data source was a PostgreSQL database handling multiple terabytes of data daily, with some tables experiencing high-velocity changes every 5-10 minutes. They wanted to ingest this data into Snowflake, their main analytics platform, in a way that accurately reflects the changes in the source data in a timely manner. This presented several technical hurdles:
High-volume, rapidly changing data: The PostgreSQL database was processing over four TB of data per day, with peak loads reaching 160 GB per hour. Some critical tables underwent bulk updates, deletes, and inserts within short 5-10 minute intervals, creating a challenging environment for traditional Change Data Capture (CDC) tools.
Real-time requirements: The company needed to perform analytics on this high-velocity data and use it to power real-time, customer-facing products. This necessitated a solution that could capture and propagate changes with minimal latency.
Resource constraints: Operating with a lean team, the startup lacked dedicated data engineering resources. The ideal solution needed to be manageable by analytics professionals without extensive data engineering expertise.
Building High-Scale CDC Pipelines Without a Data Engineer
The team initially explored several well-known data ingestion solutions including Fivetran and Airbyte. These solutions fell short primarily due to their CDC implementations, which couldn’t keep pace with the rapid changes and high volume of data in the PostgreSQL database of this AI-as-a-service product. Some of the ingestion tools struggled to create the initial snapshot of the Postgres tables, while others failed to continue streaming changes once the snapshot was created.
The team needed a more robust solution that could handle both the initial data load and ongoing high-velocity changes, without compromising data integrity or introducing significant latency. This led them to Upsolver.
Why they chose Upsolver:
- Upsolver successfully ingested the initial data snapshot from PostgreSQL and, crucially, kept pace with the frequent updates – a feat that had eluded other solutions.
- The Product Analytics Lead, coming from a BI background rather than data engineering, found Upsolver remarkably user-friendly. With minimal assistance from the engineering team, they were able to set up and manage reliable data pipelines. This ease of use was pivotal for the lean team looking to maximize their resources.
- Upsolver’s ability to handle the company’s unique data scenarios, including high-volume tables with frequent updates, proved to be a game-changer. The platform enabled real-time data streaming for multiple use cases, opening up new possibilities for product development.
- In the rare event of issues, Upsolver made it easy to troubleshoot and recover quickly. This reliability was crucial for maintaining data integrity and minimizing downtime, especially as the company began to rely more heavily on their data infrastructure for both internal and customer-facing applications.
From Dashboards to AI Applications: Evolving the Data Architecture
As the startup’s data needs evolved, their architecture expanded to support more complex use cases beyond internal reporting. The same data pipeline, initially built for BI purposes, could then be used to support customer-facing analytics and AI-driven features.
Additional Analytics Targets
The core of the architecture remained the Upsolver pipeline, which continued to stream data from PostgreSQL into Snowflake. However, the team expanded their use of Upsolver to route data to multiple destinations, each serving a specific purpose:
- Snowflake: Remained the primary data warehouse for internal analytics and reporting. The team used dbt for transformations within Snowflake, creating models that powered their BI tools and dashboards.
- Redshift: Introduced to support a customer-facing analytics module. This feature allowed users to analyze metrics on team performance and application processes. Upsolver streams data into Redshift, where real-time computations are performed to serve user queries.
- Elasticsearch: Upsolver was used to build indices in Elasticsearch in order to support fast, full-text search capabilities in their application, greatly speeding up time to insight from their document-heavy product data.
Powering AI Features
The team also implemented an AI-driven candidate-sourcing feature on the same pipeline architecture, starting with Upsolver streaming relevant data from PostgreSQL into Snowflake. dbt models in Snowflake are used to create a consolidated table optimized for the AI sourcing bot, which recruiters can access via a chat interface. These end users describe their hiring needs in natural language, which the AI model translates into SQL queries to execute against Snowflake to find matching candidates.
Key Takeaways
Today, the startup is able to offer real-time, data-driven features to its customers while maintaining a lean engineering team. The data pipelines managed by Upsolver support over 100 employees and multiple data-intensive products, despite having only a single person managing the data and BI infrastructure.
This case study demonstrates the power of a well-designed data architecture in enabling rapid product innovation. By choosing the right tools and approaches, the startup was able to:
- Handle high-volume, rapidly changing data without a dedicated data engineering team.
- Evolve from basic internal reporting to powering real-time, AI-driven features.
- Support over 100 employees and multiple data-intensive products with minimal data personnel.
As data volumes continue to grow, the company is exploring ways to optimize their pipeline further, including moving some transformation workloads upstream to reduce costs.