
Explore our expert-made templates & start with the right one for you.
Upsolver May 2024 Feature Summary
-
 Rachel Horder
Rachel Horder
- Release Notes
- May 3, 2024
A very warm welcome to our Spring update. This last month, the Upsolver office has been alive with activity, as our engineers have made a tremendous effort to fix a ton of bugs and issues. I think this might be the longest fix list to date!
We were also super excited to announce our new ClickHouse Cloud connector. If you’re familiar with ClickHouse, it is a special OLAP database that utilizes special table engines to analyze billions of rows of data in real time. All of us here at Upsolver are very proud to be their product partners, as our robust data ingestion engine is uniquely positioned to be able to feed events into ClickHouse at pace.
Also released this month is our new data lineage diagrams. The product team has been prioritizing data observability of late, and this was the final piece in providing 360 degree views of your pipelines. Please check it out and let me know what you think!
A big shout out to the Upsolver engineering team for their sterling work to crush bugs and add new features this month. I hope you enjoy learning about the latest, exciting updates, and please don’t hesitate to book a demo if you have not yet given Upsolver a test drive.
This update includes the following releases:
Contents
- UI
- Jobs
- Data Retention Added for Iceberg Tables
- Snowflake Driver Upgraded
- Fixed Pausing of Ingestions Jobs to Snowflake
- Cast Strings to JSON When Writing to Iceberg Tables
- Iceberg Schema Evolution Issues Fixed
- Support Added for Updated Parquet List Structure
- Optimize Non-Partitioned External Iceberg Tables
- Bug When Reading from Columns System Tables Fixed
- CDC Jobs
- Fixed Bug in Single Entity Job Not Reading from Start of Table
- Replication Job Support for Column Transformations
- Introduced PARSE_DEBEZIUM_JSON_TYPE Property to Avro Schema Registry
- Fixed Bug That Skipped Data in CDC Source
- CDC Event Log Deleted After Parsing
- Fixed Bug That Allowed Drop of Target Table
- Fixed a Bug That Prevented Creating Tables
- SQL Queries
- Enhancements
UI
NEW! Data Lineage Diagrams for Visualizing Data History
Being able to track data from its destination back through the journey and transformations since it was ingested from the source, is one of the five pillars of data observability.
Our Datasets feature already provides rich insights into the freshness, quality, volume, and schema of your data, so adding dala lineage was the final step to complete the full data picture.
You can use the data lineage diagrams in Upsolver to see a visual representation of your pipelines, as drill into each step along the way:
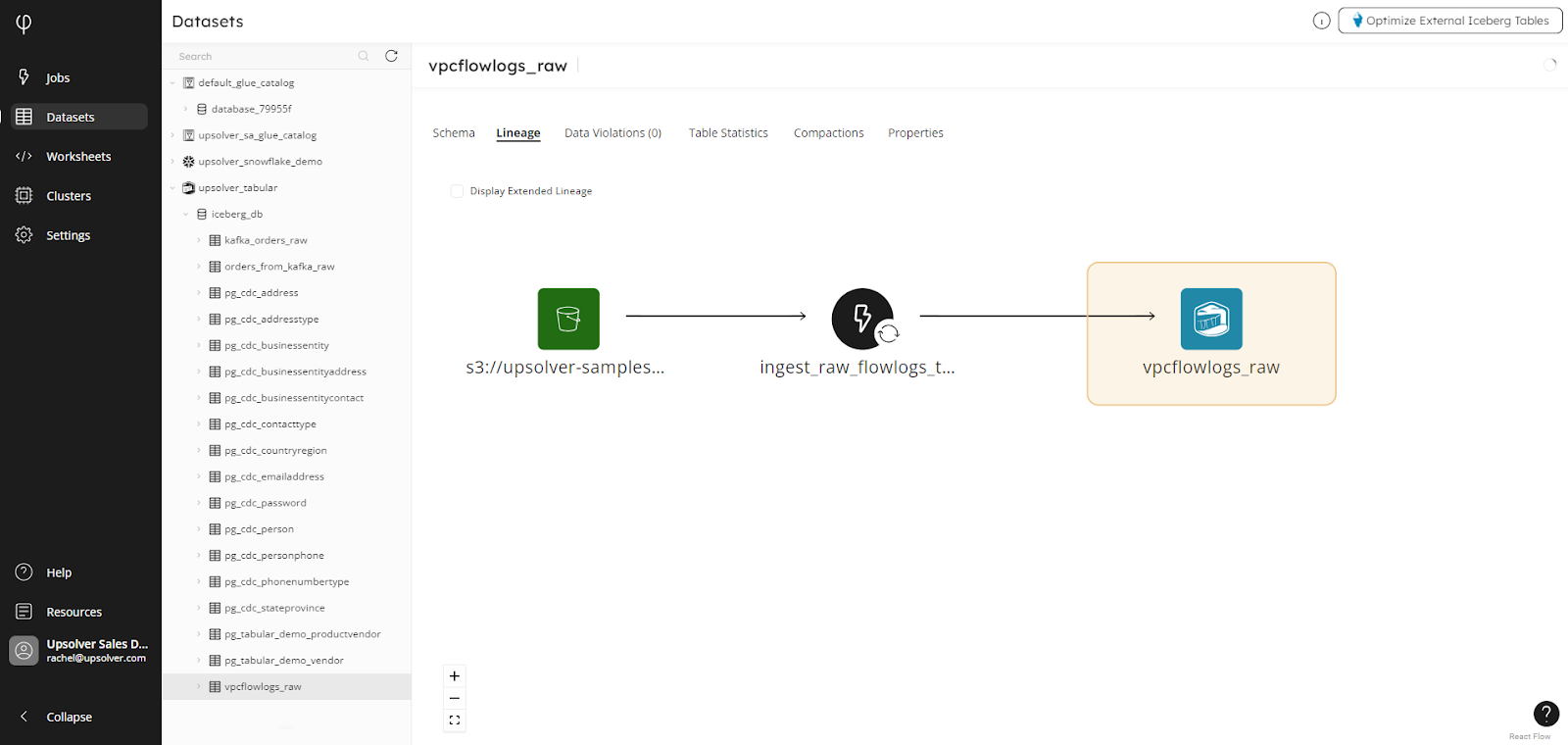
The Display Extended Lineage checkbox shows all dependencies on the data source, which is vital for determining the location of a dataset within the wider ecosystem of your organization:
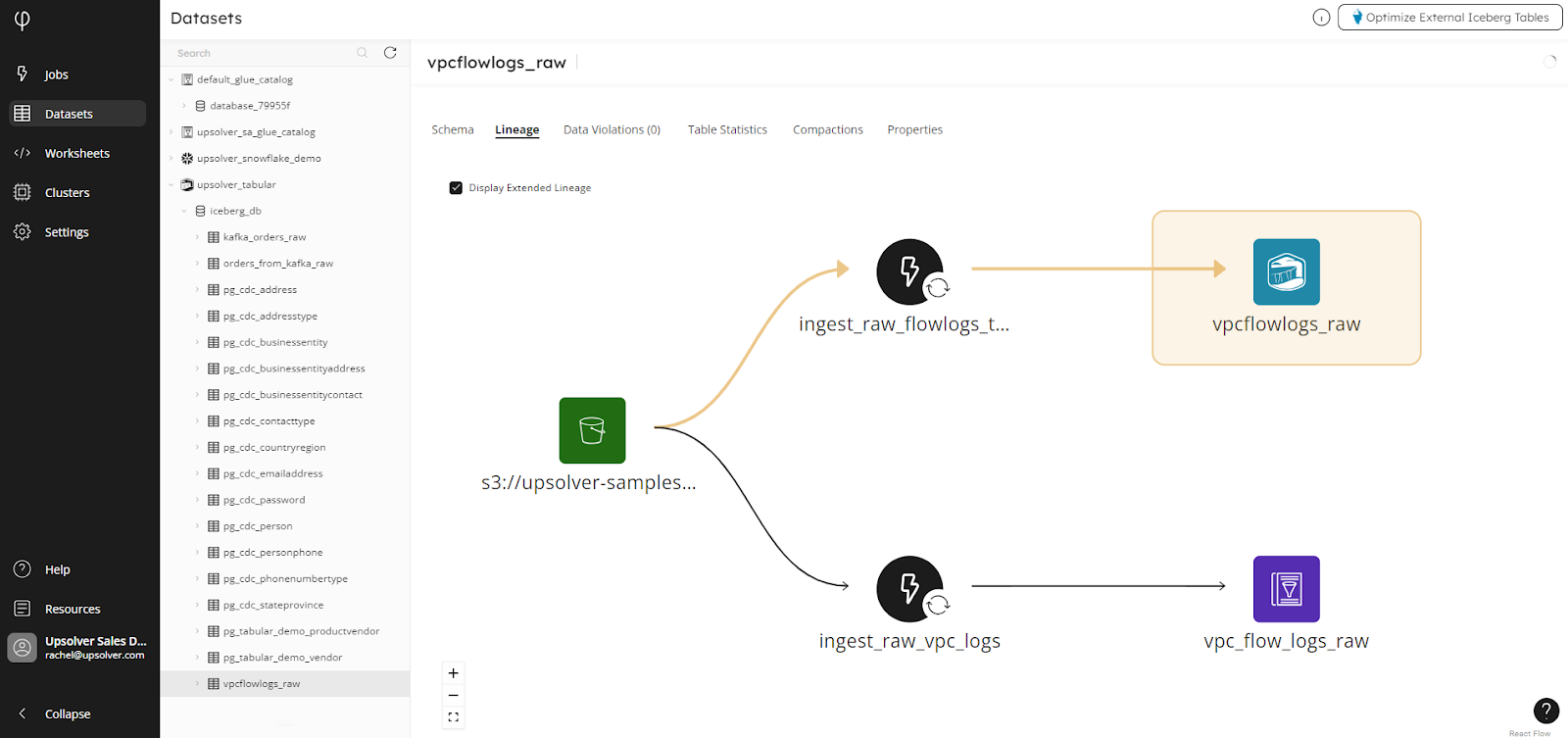
This is essential for performing change impact analysis to know that, if changes are made in the source, what downstream systems are affected. Data lineage diagrams are accessible from the Job Status, Datasets, and materialized view pages, to easily view real-time job status and dependencies.
Discover more about the importance of data lineage and how to use it in Upsolver.
NEW! Ingest to ClickHouse Cloud
We are super excited to announce support for ClickHouse Cloud as a target for your pipelines.
ClickHouse is a special OLAP database that uses highly tuned table engines to perform analysis on billions of events in real time.
Our connector sends only the changed events to the target table in ClickHouse, making it 50-100x faster than other ETL solutions and – here’s the really juicy part – 1000x cheaper! In a recent article, ClickHouse shared how they ingested 45B rows in under two hours using Upsolver, and it only cost $100. Wow!
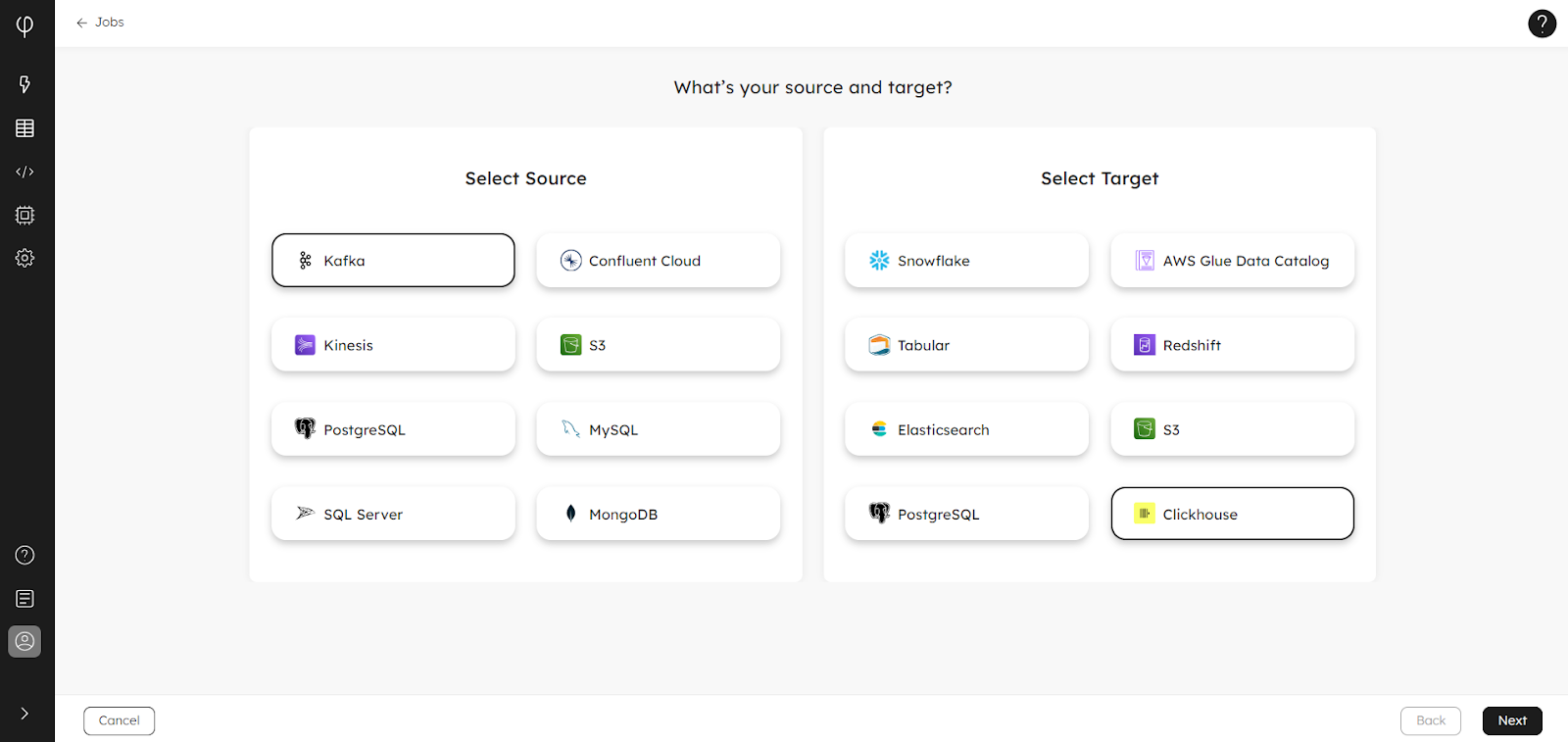
Create a pipeline to ingest your data to ClickHouse using our Data Ingestion Wizard, or learn how to write your own jobs in SQL with the following hands-on guides to get you started:
- Real-time Data Ingestion — Amazon Kinesis to ClickHouse
- Build a Data Lakehouse with Upsolver and ClickHouse
- Enriching Data – Amazon S3 to ClickHouse
Please note that CDC sources are not supported at this point, but will be coming soon, so please watch the space.
Cluster Monitoring Page Aligned with System Table
The cluster system table, system.monitoring.clusters, has been fixed so it now shows data that is aligned with the Cluster monitoring page in the Upsolver UI.
You can query the clusters system table in Upsolver by opening a worksheet and running the following code:
SELECT *
FROM system.information_schema.clusters;Then, to view the monitoring page, click Clusters on the main menu to open the Clusters page, then click on the name of the cluster you want to monitor to open the following screen:
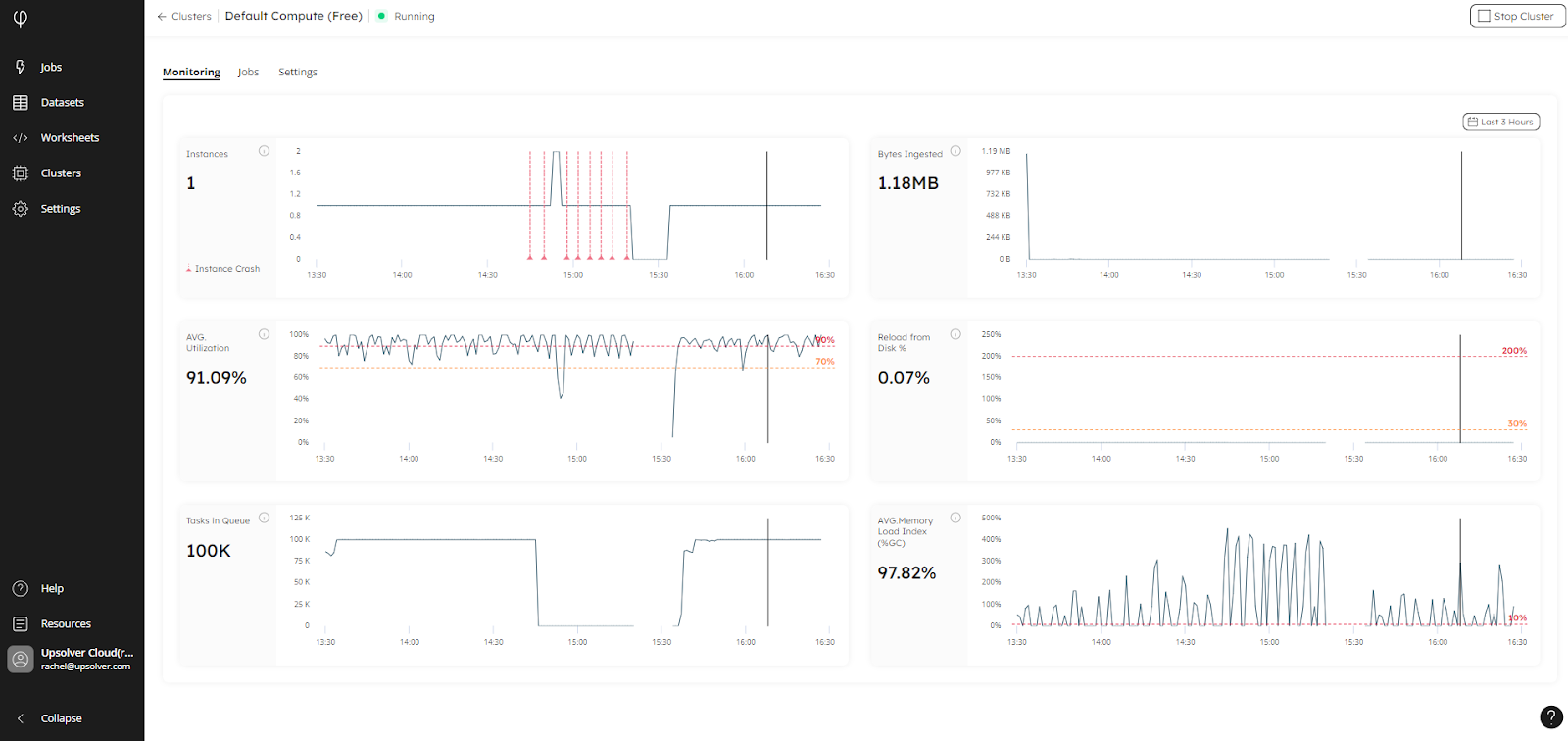
The results from the system table will now be aligned with the above monitoring page.
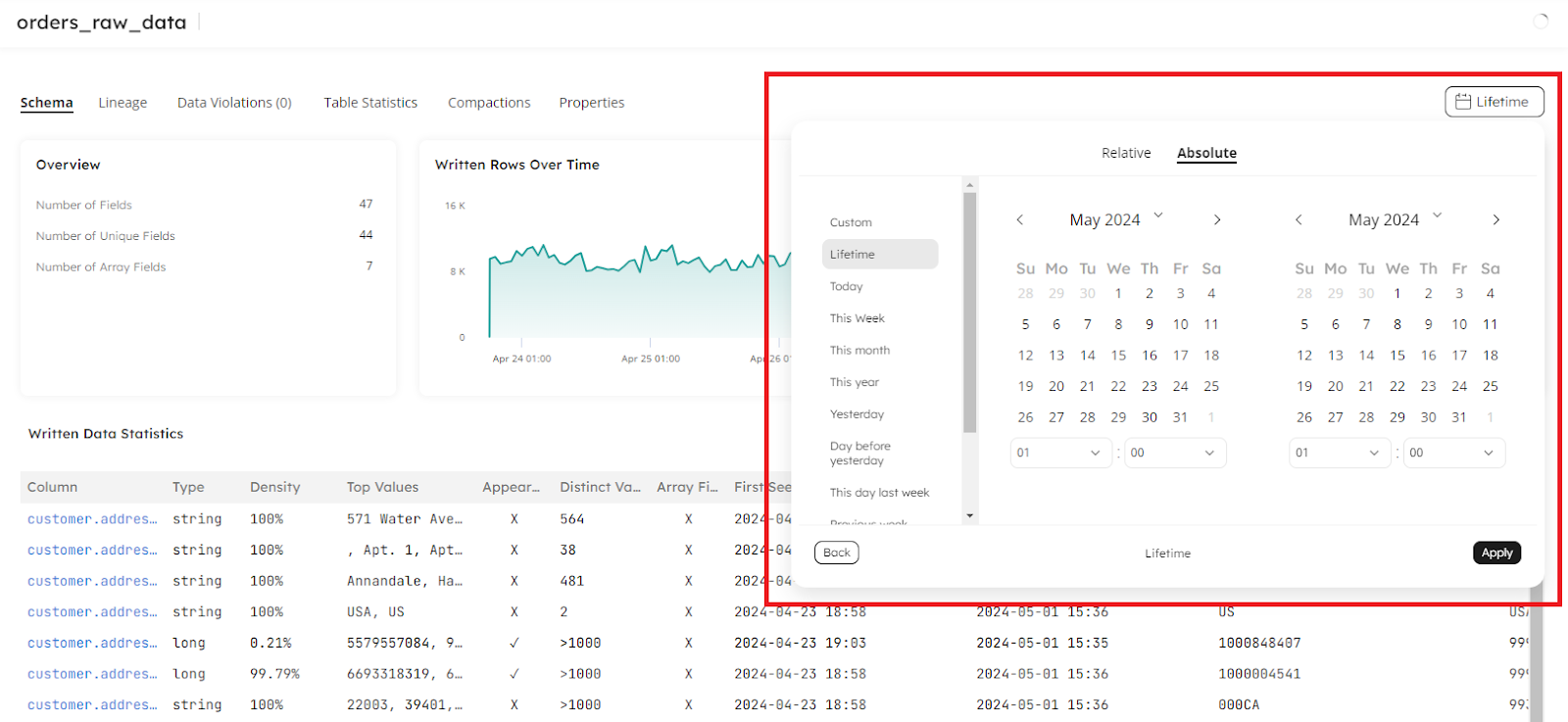
Lifetime Statistics in Datasets Fixed
We fixed an occasional bug where trying to show the Lifetime statistics in the Schema tab on the Datasets page wouldn’t appear for the currently selected dataset:
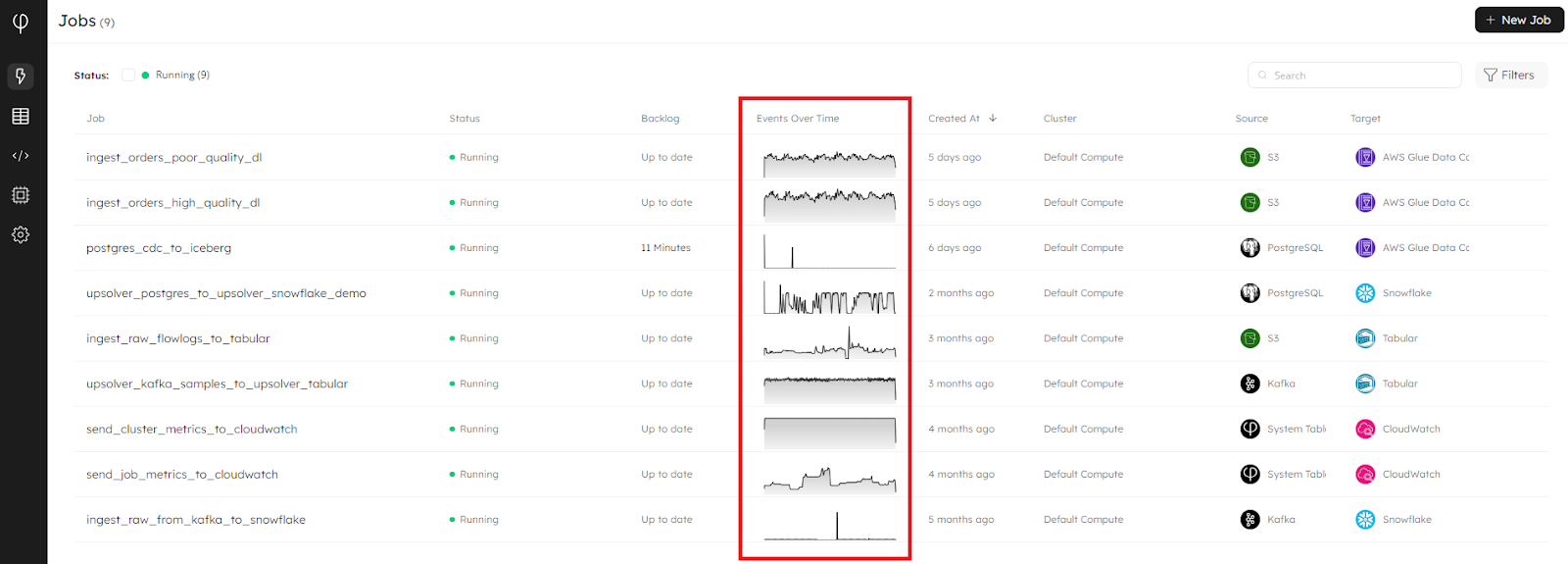
Events Written Graph Fixed for Single Entity Jobs (CDC)
There was a bug on the Jobs page, where the Events Over Time graph wouldn’t show for single entity jobs that contained a high number of sub jobs, or where the job list page contains a high number of jobs. This is now fixed.
Learn how to monitor your jobs in Upsolver.
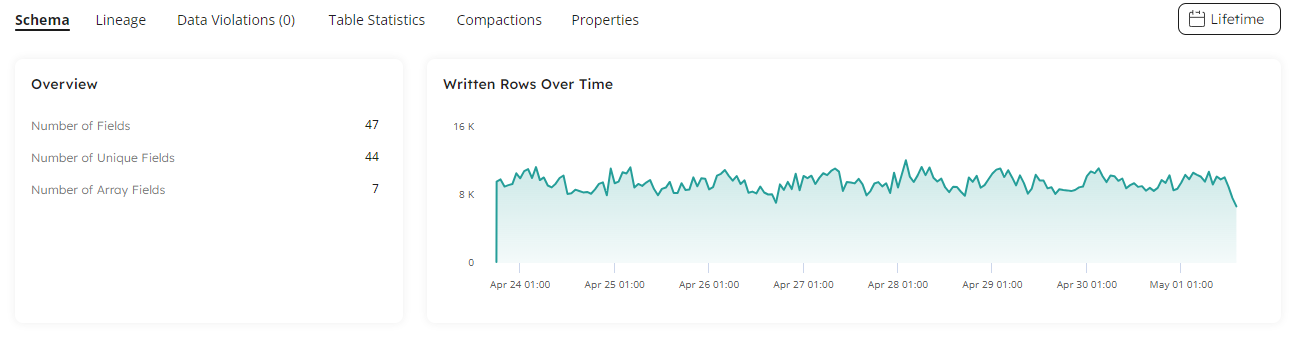
Fixed Datasets Graph Showing Incorrect Job Start Time
Another bug which was fixed this month, was where the first point in the Written Rows Over Time graph in the Schema tab on the Datasets page, would have a timestamp that was before the start time of the first job that writes to a table:
Jobs
Data Retention Added for Iceberg Tables
If you have jobs writing data to Iceberg tables, you can now use the TABLE_DATA_RETENTION property, to configure how long to keep the data in Iceberg. For example, to create a table named my_iceberg_table, with a data retention of 7 days, run the following:
CREATE ICEBERG TABLE default_glue_catalog.my_database.my_iceberg_table()
TABLE_DATA_RETENTION = 7 DAYS
PARTITIONED BY $event_date;Alternatively, you can alter an existing table to add or amend the data retention time, e.g. to set it to 14 days:
ALTER ICEBERG TABLE default_glue_catalog.my_database.my_iceberg_table
SET TABLE_DATA_RETENTION = 14 DAYS;Please read the documentation to understand how this mechanism works before applying it to your tables.
Snowflake Driver Upgraded
This month, we upgraded the Snowflake driver to 3.15.0. Check out the Snowflake documentation to learn more about this release.
Fixed Pausing of Ingestions Jobs to Snowflake
There was a bug that prevented the pausing of ingestion jobs to Snowflake, which has now been fixed. You can pause jobs in a couple of ways. On the Jobs page, use the three-dots icon to open the menu and select Pause Load to target:
Alternatively, you can pause the job using code:
ALTER JOB ingest_web_orders_to_snowflake PAUSE WRITE;Check out the documentation to learn more about pausing and resuming your jobs.
Cast Strings to JSON When Writing to Iceberg Tables
We now support casting strings to JSON in jobs writing to Iceberg tables.
Iceberg Schema Evolution Issues Fixed
Some jobs were experiencing issues with schema evolution when ingesting to Iceberg tables. Firstly, nested fields were added without the field documentation, which is later used to understand which field evolved from. This means that affected tables may need to be recreated if jobs writing to them are causing errors.
Second, jobs were not handling cases where a field can have multiple types e.g. a field can be a record and also an array of strings. Both issues are now fixed.
Support Added for Updated Parquet List Structure
For new entities, you can now use the updated Parquet list structure (parquet.avro.write-old-list-structure = false) when writing Parquet files to S3 and Upsolver tables.
Optimize External Non-Partitioned Iceberg Tables
We have extended the OPTIMIZE option for external Iceberg tables to support optimizing tables that are not partitioned. For example, to create a new table in Iceberg that is optimized by Upsolver but is not partitioned, run the following code:
CREATE EXTERNAL ICEBERG TABLE
default_glue_catalog.my_database.my_external_iceberg_table
OPTIMIZE = TRUE;Please refer to the documentation to learn about creating external Iceberg tables.
Bug When Reading from Columns System Tables Fixed
We fixed the bug where jobs that read data from the system.information_schema.columns system table would timeout when there were tables with a large number of columns.
CDC Jobs
Fixed Bug in Single Entity Job Not Reading from Start of Table
Another bug that was captured was where a single entity job that read data from a table partitioned by time, wouldn’t read from the start of the table. This is now fixed and all jobs should be working correctly.
Replication Job Support for Column Transformations
Our column transformations feature was added to enable you to perform in-flight modifications to your data. The superpower of a feature is now supported by replication jobs. Simply use the COLUMN_TRANSFORMATIONS replication group option in your scripts to take advantage:
CREATE REPLICATION JOB mssql_replication_to_snowflake
COMMENT = 'Replicate SQL Server CDC data to Snowflake groups'
COMPUTE_CLUSTER = "Default Compute (Free)"
INTERMEDIATE_STORAGE_CONNECTION = s3_connection
INTERMEDIATE_STORAGE_LOCATION = 's3://upsolver-integration-tests/test/'
FROM MSSQL my_mssql_connection
WITH REPLICATION GROUP replicate_to_snowflake_prod
INCLUDED_TABLES_REGEX = ('orders\..*')
EXCLUDED_COLUMNS_REGEX = ('.*\.creditcard') -- exclude creditcard columns
COLUMN_TRANSFORMATIONS = (hashed_email = MD5(customer.email))
COMMIT_INTERVAL = 5 MINUTES
LOGICAL_DELETE_COLUMN = "is_deleted"
REPLICATION_TARGET = my_snowflake_connection
TARGET_SCHEMA_NAME_EXPRESSION = 'ORDERS'
TARGET_TABLE_NAME_EXPRESSION = $table_name
WRITE_MODE = MERGE
WITH REPLICATION GROUP replicate_to_snowflake_dev
INCLUDED_TABLES_REGEX = ('orders\..*')
COMMIT_INTERVAL = 1 HOUR
REPLICATION_TARGET = my_snowflake_connection
TARGET_TABLE_NAME_EXPRESSION = 'history_' || $table_name
TARGET_SCHEMA_NAME_EXPRESSION = 'ORDERS_DEV'
WRITE_MODE = APPEND;This example uses SQL Server, but equally applies to MongoDB, MySQL, and PostgreSQL.
Introduced PARSE_DEBEZIUM_JSON_TYPE Property to Avro Schema Registry
This month, we introduced the PARSE_DEBEZIUM_JSON_TYPE property to the Avro Schema Registry content format for the dynamic parsing of JSON columns from Debezium sources into Upsolver records, or keeping as JSON strings. For Snowflake outputs with schema evolution, fields are written to variant type columns.
Fixed Bug That Skipped Data in CDC Source
We are very happy to announce that our engineering team fixed a bug that could skip data when reading from supported CDC sources, including SQL Server, MongoDB, MySQL, and PostgreSQL.
CDC Event Log Deleted After Parsing
Please be aware that the CDC event log is now deleted right after parsing the log events.
Fixed Bug That Allowed Drop of Target Table
We also fixed a bug where it was possible to drop a table that a replication or single entity job was writing into. The new behavior now requires that the job is dropped first. For example, in the following code, we drop the ingest_sales_data job, and then drop the sales_orders table:
DROP JOB IF EXISTS "ingest_sales_data";
DROP TABLE IF EXISTS "sales_orders" DELETE_DATA = TRUE;Fixed a Bug That Prevented Creating Tables
The engineers fixed a bug where replication or single entity jobs wouldn’t work when trying to create a table with a name that previously existed.
SQL Queries
Added Ability to Preview Classic Data Sources
If you have been using Upsolver Classic, we now support previewing Classic data sources:
SELECT *
FROM "classic_data_source_name";Enhancements
VPC Integration Experience Improved
We have increased the performance of your VPC integration, so this should now be a much better, and faster, experience.
Reduced Amazon S3 API Costs For Selected Storage
Last, but by no means least, we have reduced the Amazon S3 API costs of replication and single entity jobs, Iceberg tables, and Hive tables. And that’s a great note to end this month’s release on!
Published in:
Blog
,
Release Notes
