
Explore our expert-made templates & start with the right one for you.
Upsolver March 2024 Feature Summary
-
Rachel Horder
- Release Notes
- March 6, 2024
So much has happened here at Upsolver this last month, it’s a good job that February was a leap year and we had an extra day! I’m really excited to share the latest updates with you, and wow, what an exhilarating month it has been!
We hosted our first in-person event, the Chill Data Summit, in New York City, where our founders, Ori Rafael and Yoni Eini, announced Upsolver’s support for Apache Iceberg. Leading up to the event, our engineering team was working at full throttle, building in three big new features to help you with your Iceberg projects. Since then, they’ve added support for additional data platforms, alongside their continuous commitment to improvements and fixes. Read on to learn what we’ve been up to!
This update includes the following releases:
Contents
- Enhancements
- UI
- Jobs
- CDC Jobs
- SQL Queries
Enhancements
New: Ingest Data into Apache Iceberg Tables
Our first big announcement is that you can create and write into Iceberg tables over AWS Glue Data Catalog or Tabular catalogs using Upsolver. We support database, streaming, and file sources, and you can use the GUI or roll your own SQL to ingest and transform your data into Iceberg.
After creating a pipeline, Upsolver automatically takes care of the background maintenance work to compact the files and tune your tables. This ensures the best possible query performance so users don’t experience delays, while the compaction process reduces the size of your files, thereby reducing storage costs.
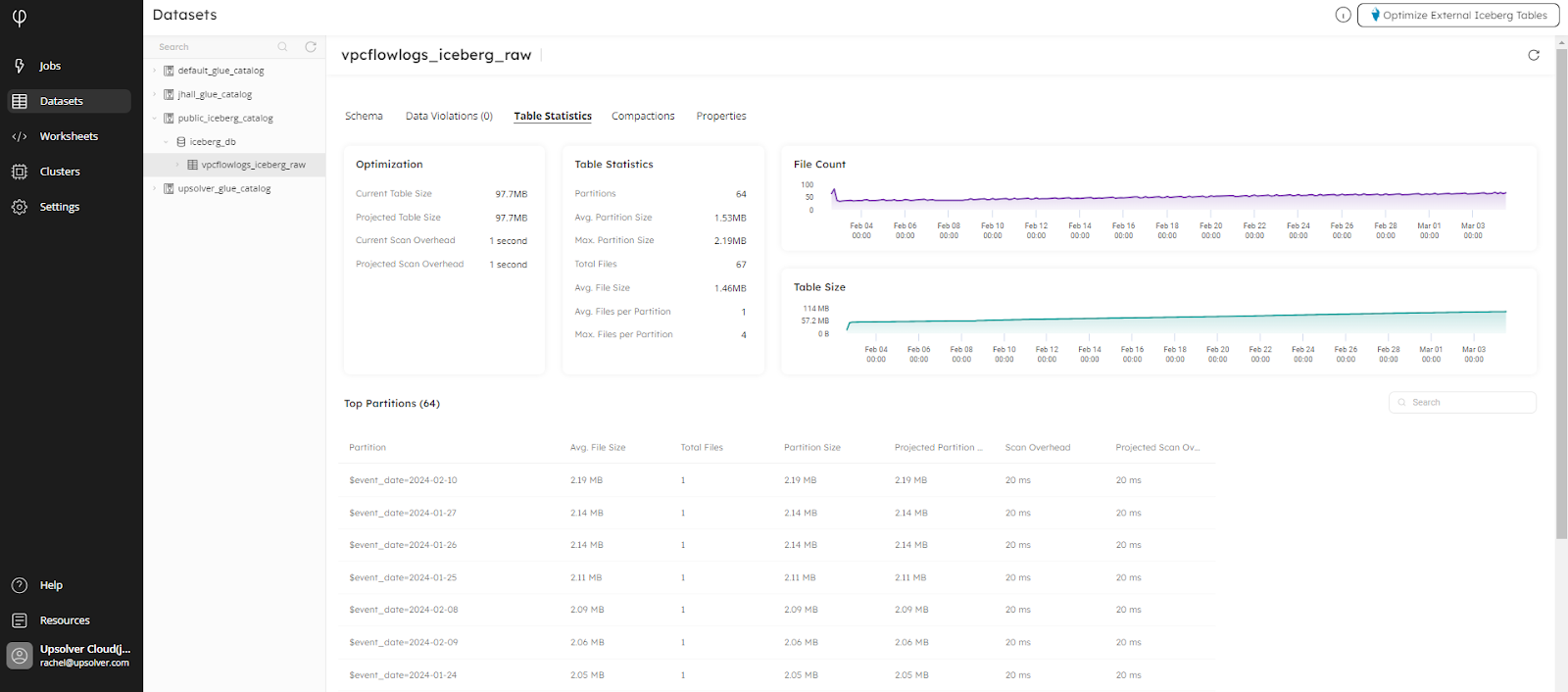
If you’re already familiar with Upsolver, you’re probably aware that we include built-in data observability as standard. Since adding support for Apache Iceberg, we have extended the Datasets feature to include insights into table statistics and compactions. You can discover where Uspolver has detected that performance gains can be made, and you don’t need to take action on your Upsolver-managed tables, as we do the work for you. This enables you to concentrate on more important business activities.
To learn more, explore the documentation on creating Iceberg tables and writing jobs to ingest to Iceberg. Also, I recommend you check out the blog post, Ingesting Operational Data into an Analytics Lakehouse on Iceberg, which walks you through the steps for creating a pipeline and monitoring table statistics and compaction.
New: Iceberg Table Optimizer
Do you already have Iceberg tables that Upsolver is not writing into? Then let me introduce you to our Iceberg Table Optimizer, our second big Iceberg feature! We can optimize your existing Iceberg tables – whether created by Upsolver or another tool – to manage the compaction process, and display statistics on your Iceberg tables.
By continuously monitoring the files that comprise your tables, Upsolver uses industry best-practise guidelines to calculate the best time to run compaction and tuning operations to accelerate queries and keep storage costs down.
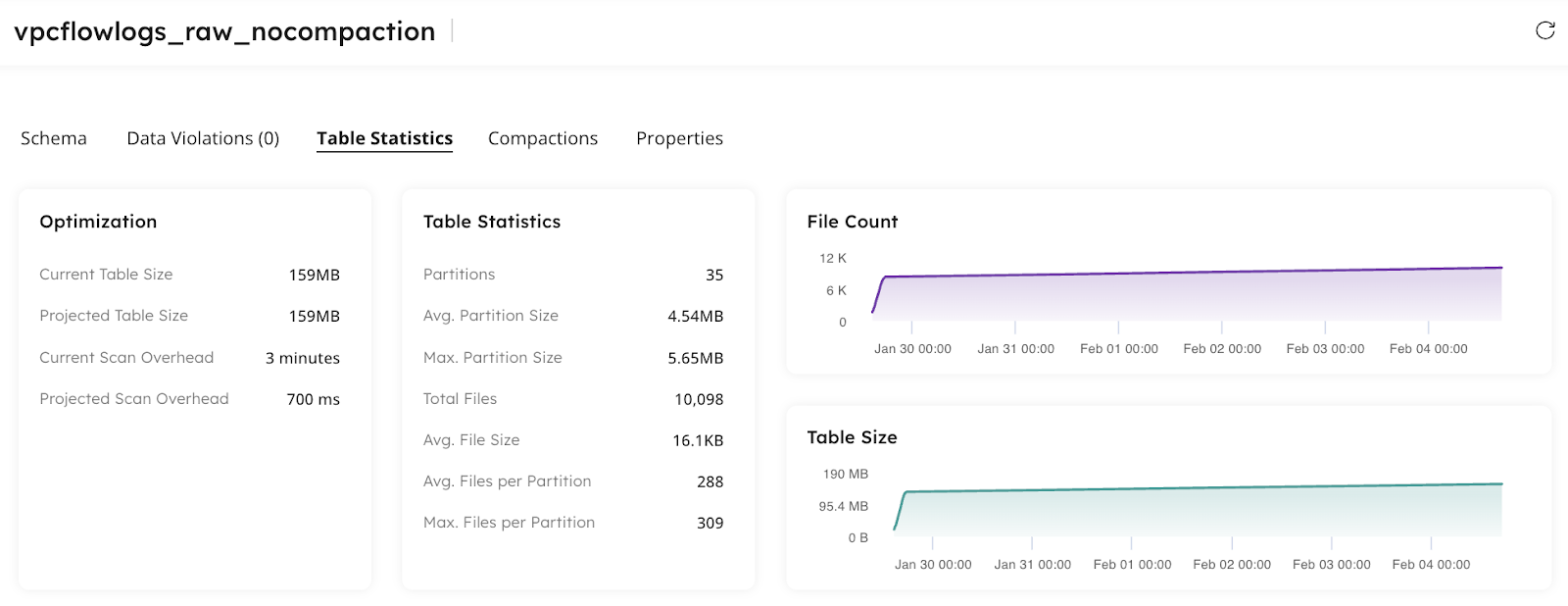
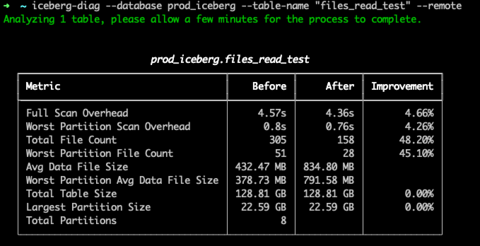
Select an Iceberg table for Upsolver to analyze, and you can see the improvements that can be made. The screenshot below displays the file count and table size before running the Iceberg Table Optimizer:
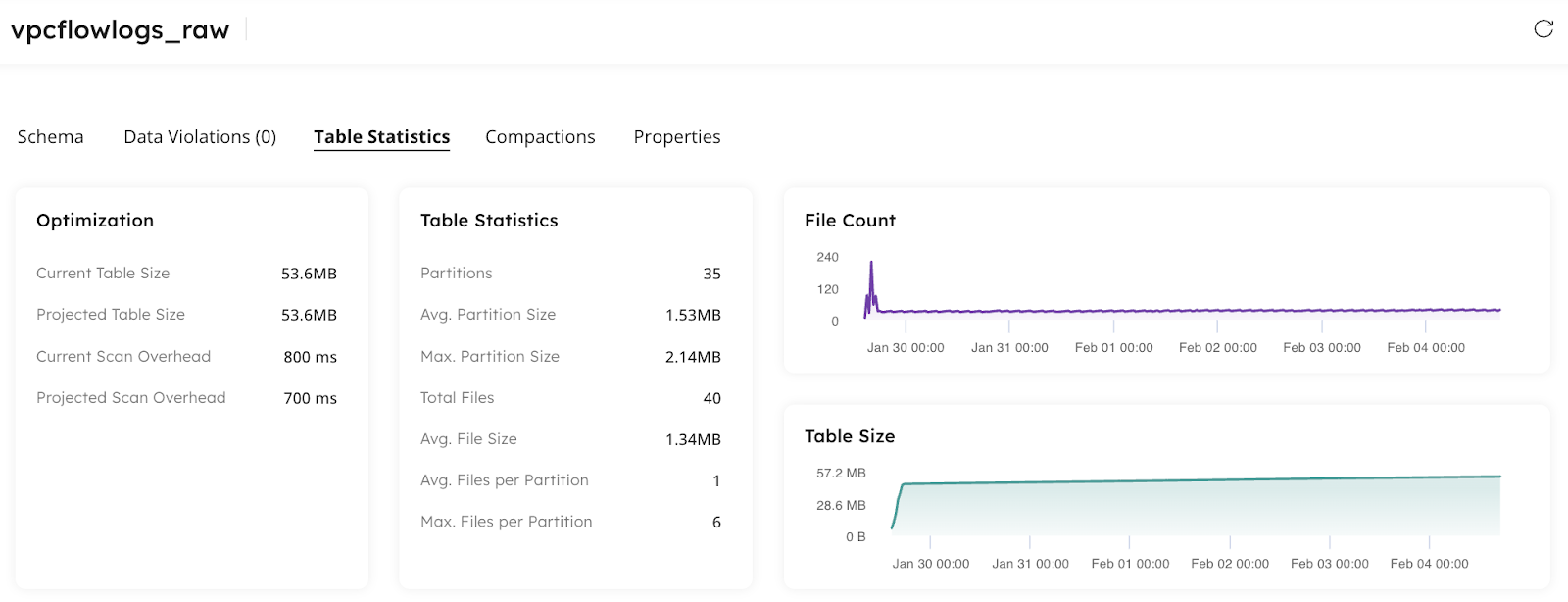
Then, after running the compaction and tuning process on the table, the file count and table size are reduced, leading to increased query performance and lower storage costs:
Learn how to save storage costs and increase query performance with Upsolver’s Iceberg Table Optimizer.
New: Iceberg Table Analyzer Tool
Have you already built your lakehouse using Apache Iceberg? Do you need to discover which tables need compaction and optimization? The Iceberg Table Analysis CLI Tool – our third big Iceberg feature – evaluates your Apache Iceberg tables to identify how Upsolver optimizations can enhance efficiency by reducing costs and query time.
This is a free, open-source tool, and you don’t need to be an existing Upsolver customer to use it. The tool analyzes your Iceberg tables, and shows you where gains can be made.
When you have generated your table reports, you can optionally use the Upsolver Iceberg Table Optimizer to compact and tune your tables. We’d love to know how you get on with the Iceberg Table Analyzer – please share the results of your report and show us how badly your tables need compaction. Drop us a line or tag us on social media with your results!
Learn how to install and run the Iceberg Analyzer Tool and discover where you can improve performance.
UI
New: Monitoring Page for Tracking CDC Jobs
Whether you create a CDC job with the Data Ingestion Wizard or write your own SQL code, you will notice that the monitoring page for tracking your job has been extensively improved. As soon as you create your job, you can watch the ingestion progress, while Upsolver connects to your source, lists the tables for snapshot, snapshots each table, and then continuously ingests the changed data.
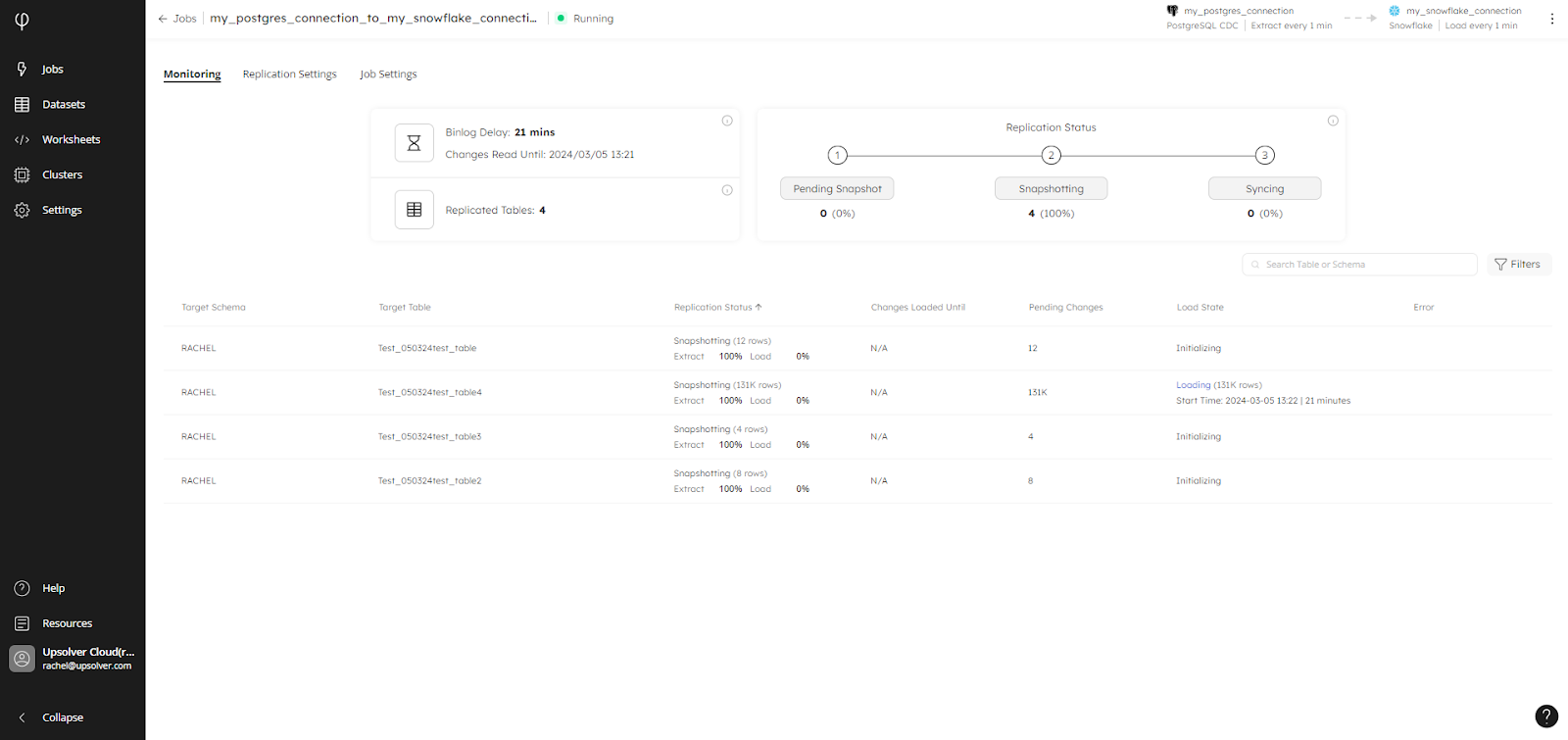
The Monitoring tab includes the replication status, such as Pending Snapshot, Snapshotting, or Syncing, and provides contextual information for each table depending on its status. For example, during the snapshotting process, you can see how many rows are in a table and the percentage that have been extracted and loaded:
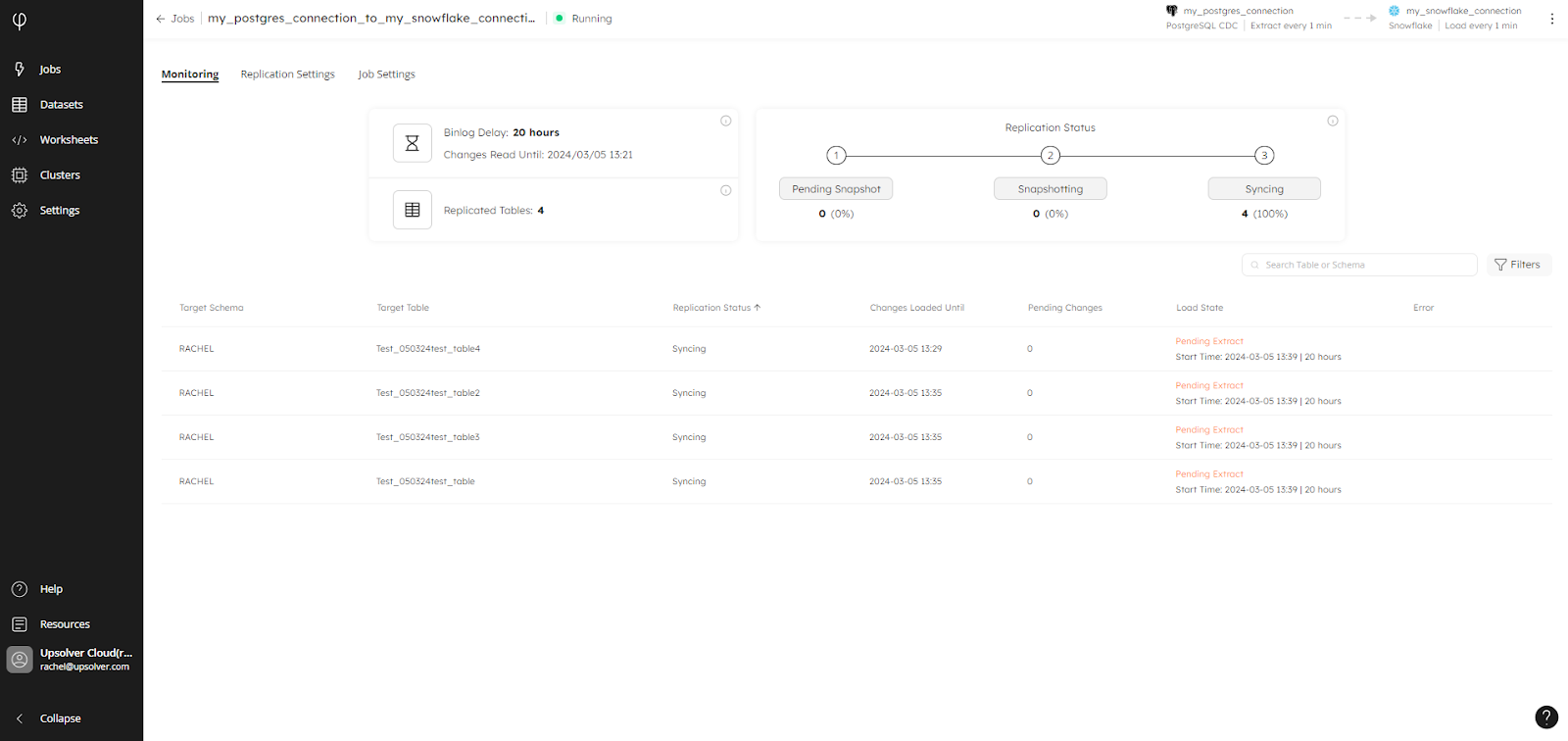
After the database snapshot has completed, you can monitor the flow of data from source to target, with full visibility into the synchronization process:
Enhanced Monitoring for Ingestion and Transformation Jobs
We have also given the job monitoring page for stream and file sources an overhaul to make it easier to understand the metrics around each job. The Monitoring tab has been reorganized to ensure you find the right metrics when you need them. Metrics remain in groups to categorize them for easy discovery, and the summary shows the most relevant metrics for your job type.
The Graphs tab, shown in the screenshot below, highlights any delays in reading from the source, parsing the data. writing to storage, and writing to the target:
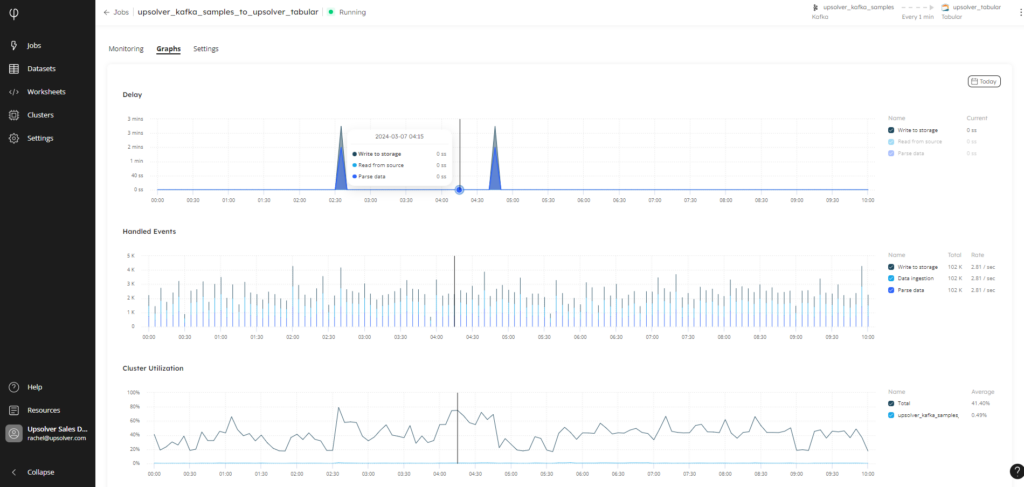
You also have visibility into the number of events handled across the selected time span – change this using the time filter – so you can monitor the volume of data traveling through the pipeline at any given moment. This will enable you to discover spikes or drops in the flow of data that need to be investigated.
The Settings tab remains the same, and displays the SQL code used to create your job, job option settings, and information about the user who created and last modified the job.
New: Cluster Monitoring Page for Private VPC Integration Users
We have also improved and enhanced the cluster monitoring pages to provide more information in a format that’s easier to understand. If you organization is integrated with your private VPC, you will see better visibility into the performance of your clusters:
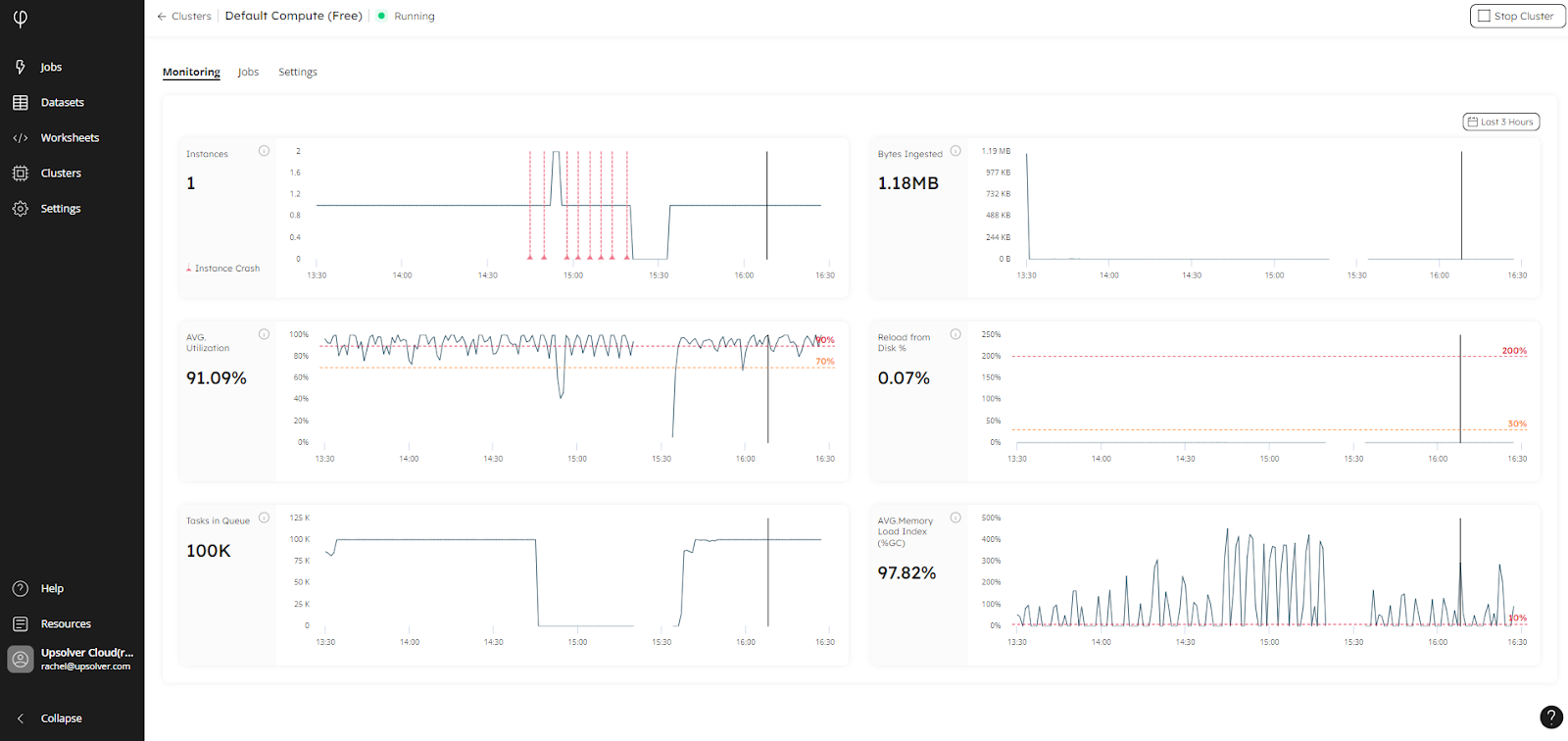
You will now get a much easier to understand, visual representation of the work your cluster is currently undertaking, and you can view these statistics over a specific period using the time filter.
The Jobs tab provides a chart that breaks down the cluster usage by job:
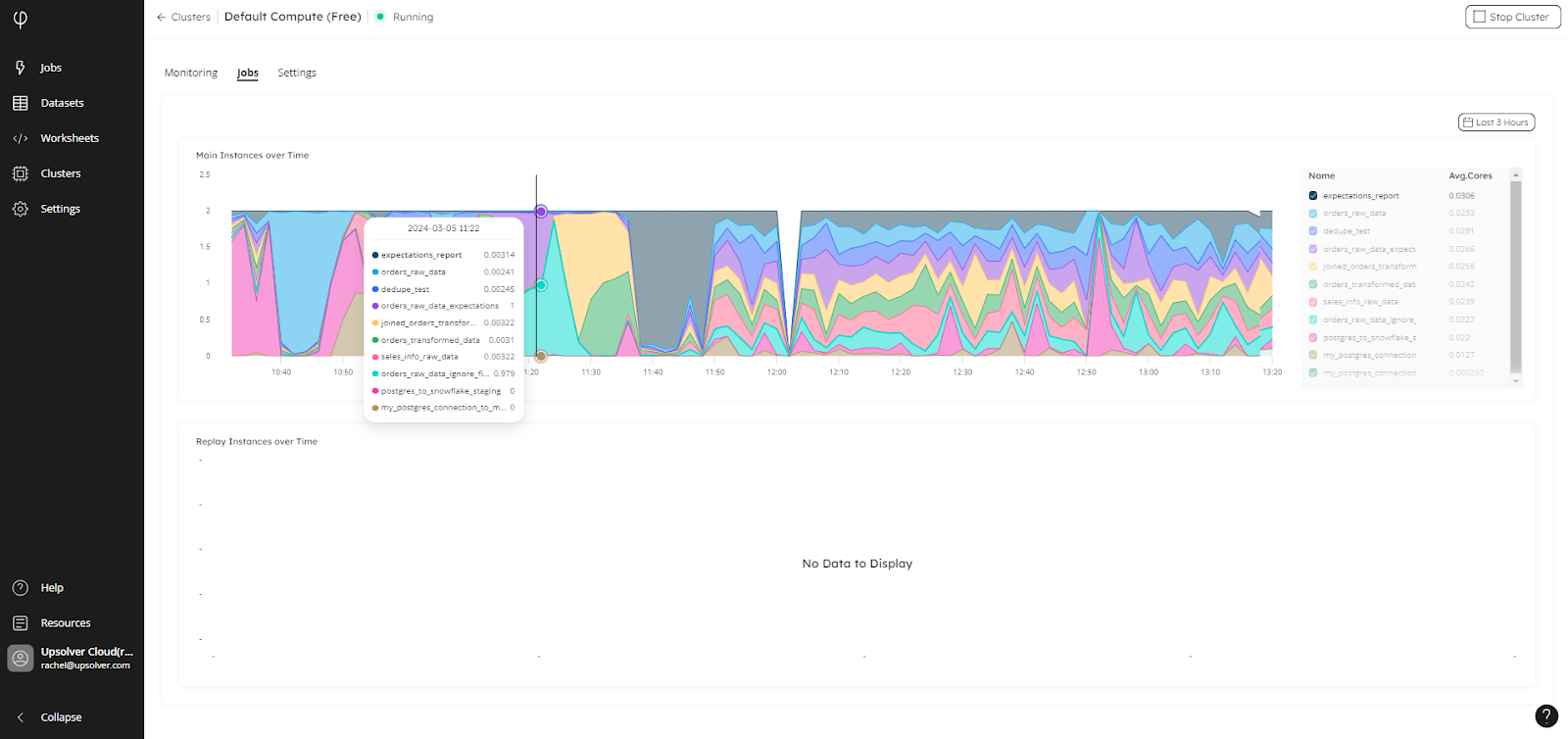
Again, you can filter by time and job to understand your cluster usage.
New: Support Ingesting Data to AWS Glue Data Catalog
Our Data Ingestion Wizard now supports AWS Glue Data Catalog as a target. Previously, this was only supported only via SQL. You can choose from database, file, and streaming sources and use the Wizard to create your job to ingest to AWS Glue Data Catalog:
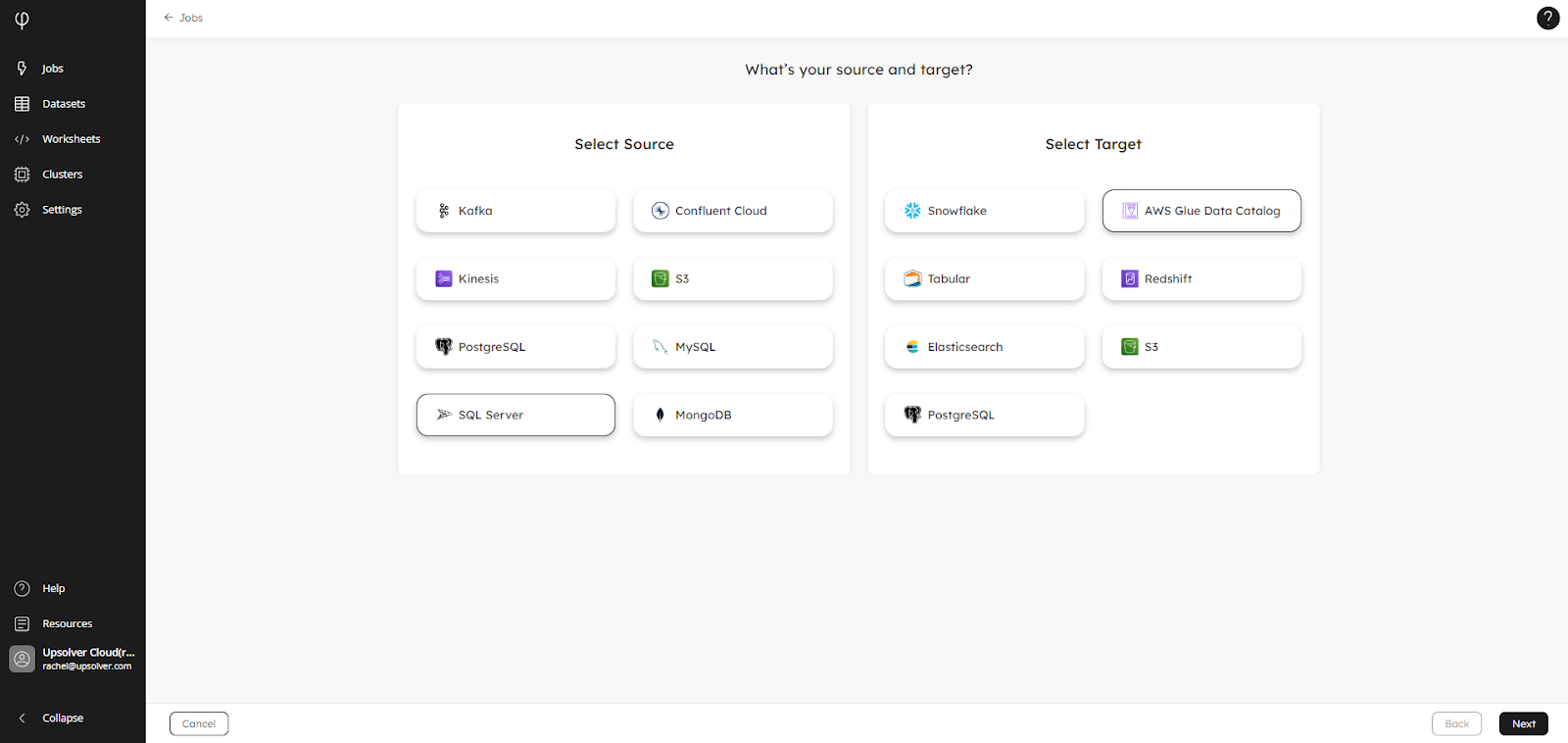
Alternatively, use the Wizard to create the SQL outline of your job, and edit the code in a worksheet to customize the job with transformations or expectations, for example.
When you connect to your existing AWS Glue Data Catalog or create a new one, you have the option to use the Upsolver managed Iceberg table format, or Upsolver managed Hive tables (compatibility mode). Iceberg tables are the default setting:
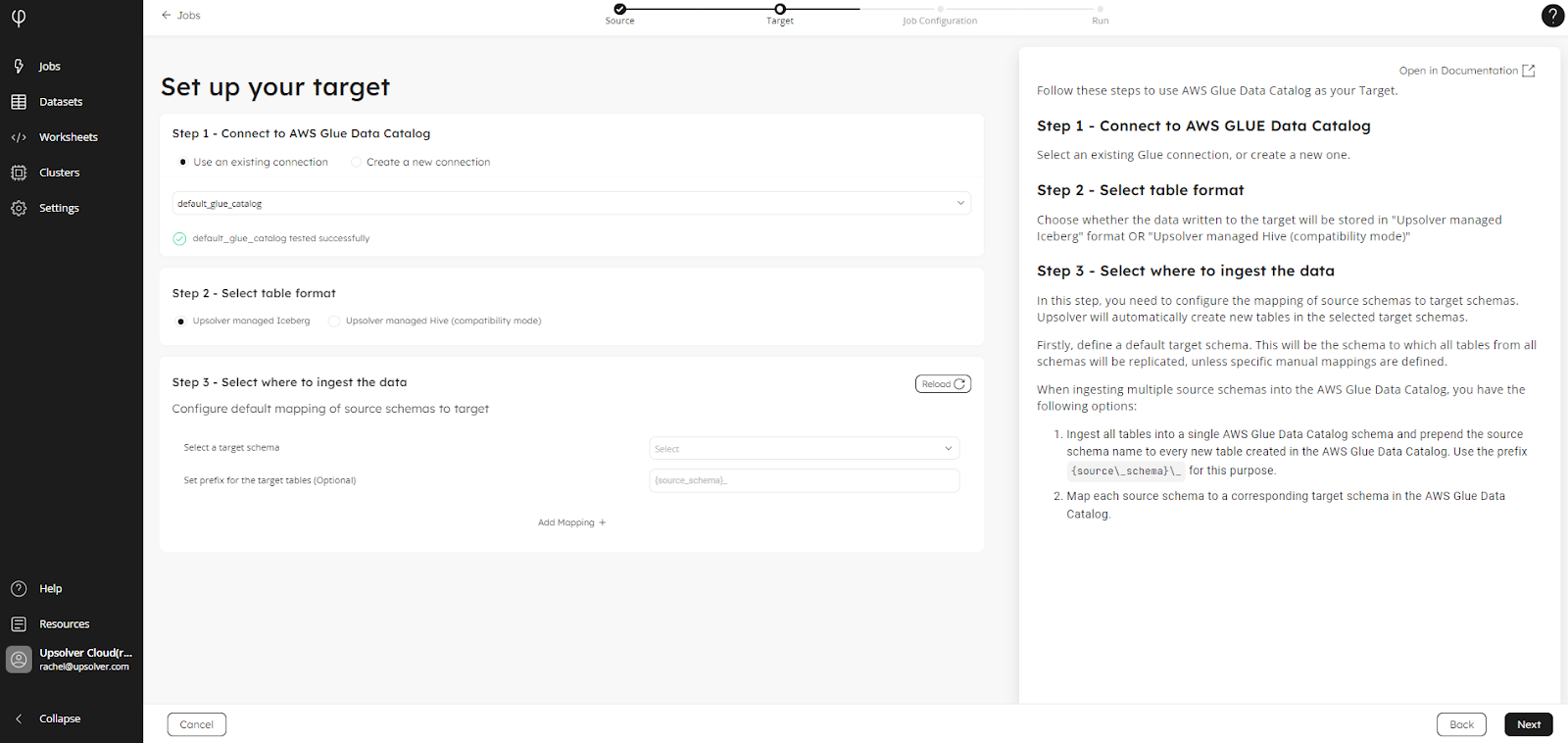
New: Edit CDC Jobs via the GUI
If you’re ingesting CDC data, I’m sure you’ll be happy to hear that you can now edit your job directly from the GUI – as well as via SQL. From the Jobs page in Upsolver, you simply click on the job you want to edit and open the Replication Settings tab where you can add or remove columns, tables, and schemas:
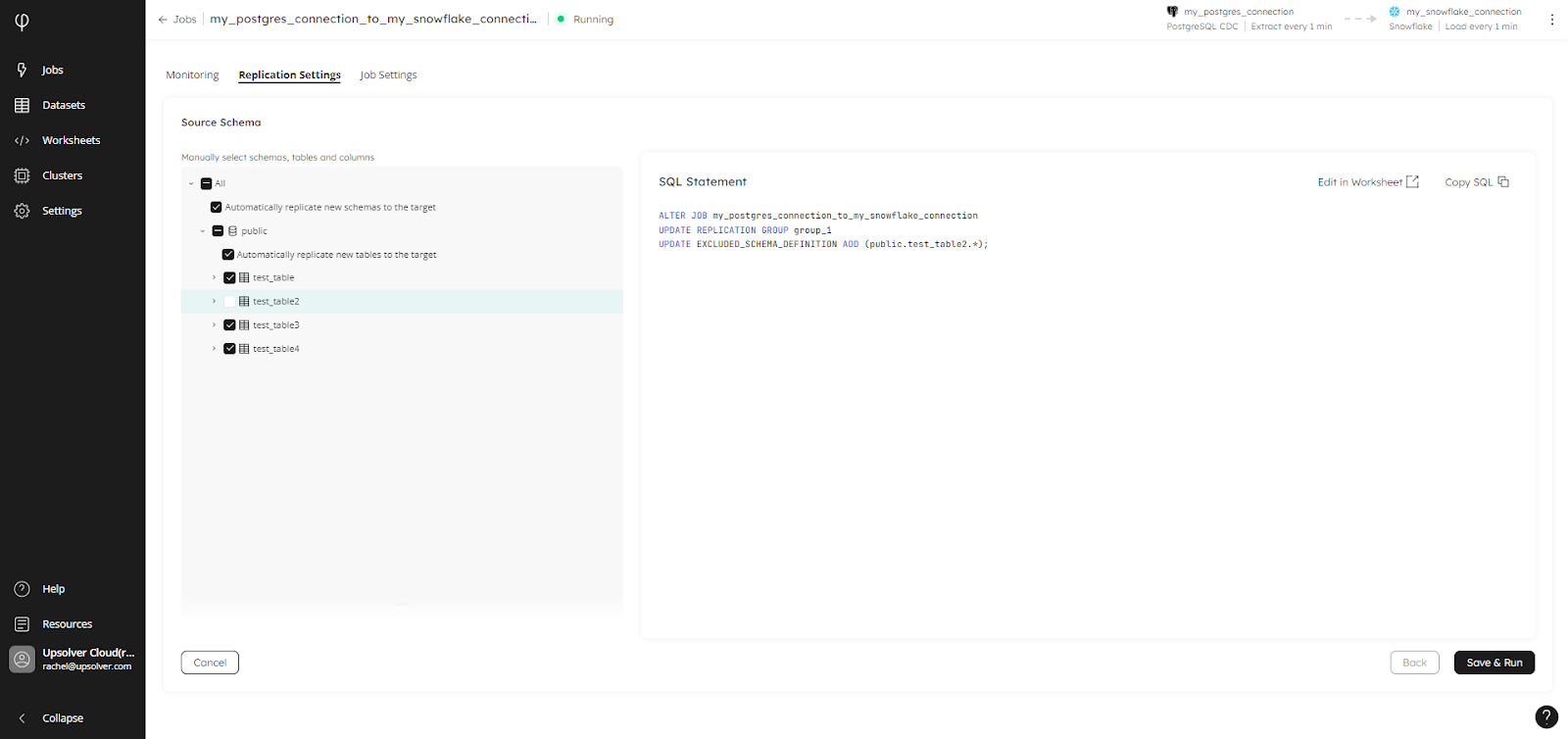
As you can see from the screenshot above, when you select objects to remove from the job – this would also apply if you are adding objects – the Wizard provides the SQL code so you can optionally edit this in a worksheet.
ALTER JOB my_postgres_connection_to_my_snowflake_connection
UPDATE REPLICATION GROUP group_1
UPDATE EXCLUDED_SCHEMA_DEFINITION ADD (public.test_table2.*);This is super helpful if you want to use a regular expression to amend the definition.
Jobs
New: Support Tabular Data Catalog as a Target
As part of our support for Apache Iceberg, we now enable the Tabular data catalog as a target, and you can create ingestion, transformation, and replication jobs writing into Tabular. When you create your connection in Upsolver, it will be available to everyone in your organization and is always on, so you can create as many jobs as you like using the same connection.
The example below demonstrates how to create a connection named my_tabular_connection, that uses the Orders Warehouse:
CREATE TABULAR CONNECTION my_tabular_connection
TOKEN = 'my_credentials'
WAREHOUSE = 'Orders Warehouse'
DEFAULT_STORAGE_CONNECTION = my_s3_storage_connection
DEFAULT_STORAGE_LOCATION = 's3://upsolver-demo/my_tabular_catalog_table_files/';Please see the Upsolver documentation for connection options and examples, and refer to the Tabular job reference to learn about supported options.
New: Ingest Data into a Target ClickHouse Data Warehouse
If you have a ClickHouse data warehouse, then I’m excited to tell you that we now support creating transformation jobs that write your source data into ClickHouse MergeTree tables. Create a ClickHouse connection as per the example below:
CREATE CLICKHOUSE CONNECTION my_clickhouse_connection
CONNECTION_STRING = 'http://<host_name>:8123/<db_name>'
USER_NAME = 'my_username'
PASSWORD = 'my_password';ClickHouse is currently supported when using SQL to create your data connections and jobs, and will be added to the Data Ingestion Wizard in the near future. I’ll keep you posted! In the meantime, please check out the ClickHouse connection reference page in our docs for more information.
Fixed Snowflake Placeholder In Custom Update Expression
We fixed the bug in jobs writing to Snowflake that were using {current_value} as a placeholder in CUSTOM_UPDATE_EXPRESSION. If you continue to experience this issue, please contact our support team.
Update to How We Parse Decimal Values
We adjusted the parsing of Decimal values to fix an issue where the value would be typed incorrectly. Previously, when the underlying value was a whole number and the decimal scale was positive, the field was incorrectly typed as Long instead of Double.
CDC Jobs
New: Support for Data Lakehouse Tables and Catalogs
Building on our support for Apache Iceberg, you can now ingest your change data capture (CDC) data to Iceberg and Hive table formats. Currently, you can select from AWS Glue Data Catalog or Tabular for your data catalog. Upsolver handles any schema evolution that arises from your source database, and manages the compaction and optimization of your target Iceberg tables.
The following example creates a replication job named ingest_web_orders_to_tabular to ingest the CDC data from a PostgreSQL database, using the connection my_postgres_connection. All tables in the publication are ingested to the weborders schema in the Tabular target, specified in my_tabular_connection.
CREATE REPLICATION JOB ingest_web_orders_to_tabular
FROM my_postgres_connection
PUBLICATION_NAME = 'web_orders_publication'
WITH REPLICATION GROUP web_orders_replication_group
INCLUDED_SCHEMA_DEFINITION = (*)
WRITE_MODE = MERGE
UPSOLVER_EVENT_TIME_COLUMN = UPSOLVER_EVENT_TIME
TARGET_SCHEMA_NAME_EXPRESSION = 'weborders'
TARGET_TABLE_NAME_EXPRESSION = $table_name::STRING
REPLICATION_TARGET = my_tabular_connection;Upsolver currently supports ingesting your data from Microsoft SQL Server, MongoDB, MySQL, and PostgreSQL, using ingestion, transformation, and replication jobs, to give you the flexibility to build pipelines that suit your business requirements.
SQL Queries
Fixed Commit Time Data Type Issue in RECORD_TO_FUNCTION
We corrected the data type of $commit_time from Long- * to Timestamp. This change impacts use cases involving the $commit_time field within the RECORD_TO_JSON function.
Have you implemented Apache Iceberg in your data ecosystem yet? If you would like to know more about our Iceberg tooling, or have any questions about an upcoming Iceberg project, we’d love to help you out. Please book a call with one of our Solutions Architects, who would be happy to chat through your use case. If you’re new to Upsolver, why not start your free 14-day trial,
In the meantime, I hope you’ve enjoyed learning about this month’s features, and are as excited as we are about the benefits they can offer. See you next month for another update.
Published in:
Blog
,
Release Notes