
Explore our expert-made templates & start with the right one for you.
Upsolver January 2024 Feature Summary
-
Rachel Horder
- Release Notes
- January 5, 2024
Happy New Year and welcome to the first feature summary of 2024. This year promises to bring some exciting new features in Upsolver, but in the meantime, let’s catch up on what our engineering team have been up to over the last month.
This update covers the following releases:
Contents
- UI
- Jobs
- CDC Jobs
- Enhancements
UI
Fixed Backlog Calculation in the Jobs List to Show More Accurate Times
The jobs page in the Upsolver UI displays all your jobs with a summary of metadata to give you insight into the job status and performance. We fixed an issue in the backlog calculation so it now shows more accurate times of the currently running jobs.
Fixed the Events Over Time Graph for Replication Jobs
Following on from the previous issue, we fixed another problem on the Jobs page whereby the Events Over Time graph for replication jobs was showing incorrectly. We have now capped its range by the job running times so it reflects the pipeline more accurately:
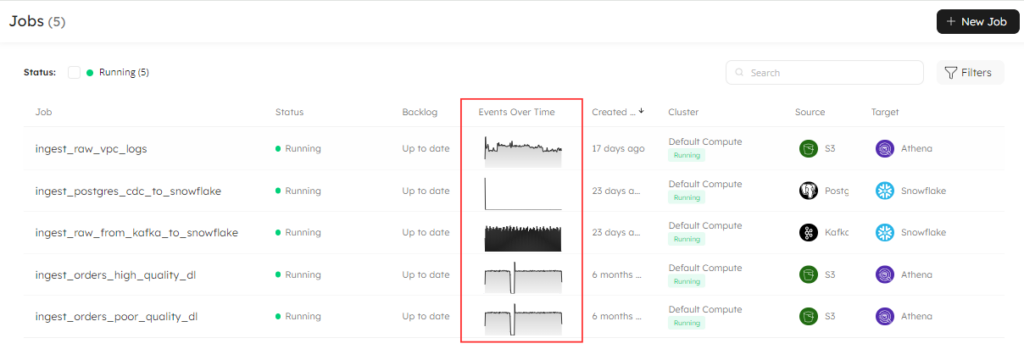
Jobs
Drop a Job Using the UI
Regardless of your data source and target platforms, you can now drop a job using the Upsolver UI, or execute a simple SQL statement. From the jobs page in the Upsolver UI, click the three-dots menu on the job you want to drop and select Drop Job:
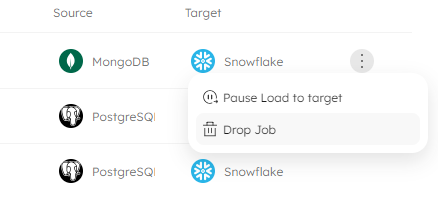
After clicking Drop Job from the menu, Upsolver asks you to confirm this action, so you have the opportunity to cancel it if you change your mind or want to check you have selected the correct job.
You can also drop a job using SQL code, as per the example below:
DROP JOB IF EXISTS "ingest_mongodb_sales_data_to_Snowflake";Keep in mind that there is no pre-check when dropping a job in code, and the statement will execute immediately with no ability to roll back. Check out the documentation for more information on how to drop a job.
Pause and Resume a Job via the UI and SQL
Using the same menu as for dropping a job, you now have the option to pause a job. This is super handy if you need to carry out any of the following operations:
- You may need to undertake maintenance or upgrade your source or target database.
- If errors occur during the processing of your pipeline, you can pause your job to investigate and correct issues. If you experience a data issue, temporarily pausing a job can help prevent errors – or further errors – from polluting your downstream target.
- Should you want to carry out testing, pausing your job is a great way to run a comparison between your source and target and verify your data is as expected.
- Pausing your job also enables you to temporarily reduce the load on the source or target system.
Furthermore, while your job is paused, you can make alterations to the job options or add expectations. However, you can only alter options that are mutable – please see the ALTER JOB documentation for further instructions.
Select your job from the Jobs page and, from the three-dots menu, select Pause Load to Target:
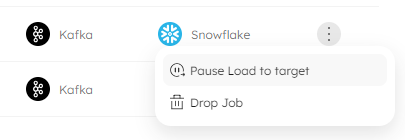
Upsolver displays a message to ask you to confirm the action. When this message shows, you will also see the SQL code that is run in the background:
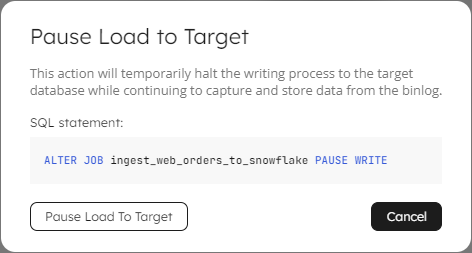
Alternatively, you can run this code manually in a Worksheet. Hold your mouse over the SQL statement to display the Copy icon, then paste the code into your Worksheet. Note that when you manually run an ALTER JOB command, there is no pre-check and the code will execute immediately:
ALTER JOB ingest_web_orders_to_snowflake PAUSE WRITE;
When you have performed the necessary operations and are ready to re-start your job, click on the three dots menu for the job in the UI, and select Resume Write. Or, run the ALTER JOB command:
ALTER JOB ingest_web_orders_to_snowflake RESUME WRITE;
Please be aware that pausing and resuming jobs is not supported for ingestion or transformation jobs writing to a data lake table as a target. Further details on pausing and resuming your jobs are available in the Upsolver documentation.
CDC Jobs
Incremental Snapshot is Default Behavior for Initial Snapshot
By default, when you create a job to ingest data from a CDC-enabled database, Upsolver performs an initial snapshot. We’ve updated this behavior so that the default is for Upsolver to perform an incremental snapshot of your database. This mechanism is a phased approach that runs in parallel to the streaming data capture, meaning you don’t need to wait for the full snapshot to complete before streaming can begin.
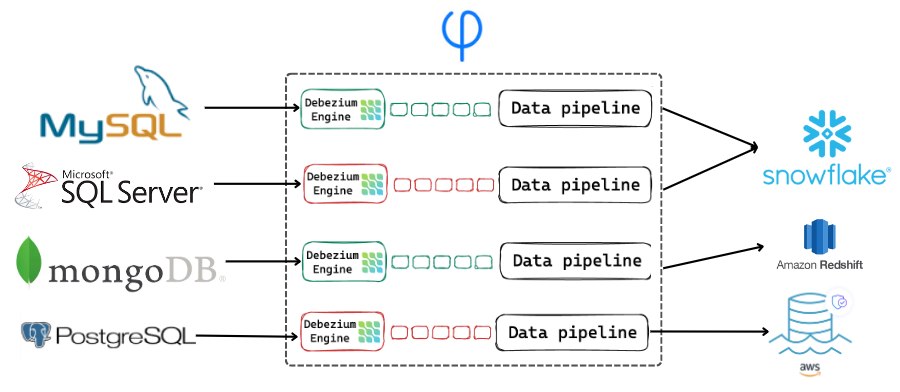
We currently offer support for ingesting data from Microsoft SQL Server, MongoDB, MySQL, and PostgreSQL. Learn more about Performing Snapshots in Upsolver.
Enhancements
Avro Schema Registry Supports Additional Content Types
When using the Avro Schema Registry content type with Debezium, we now support parsing JSON, timestamp, and date types.
That’s all for this month’s recap, I’ll be back next month with news of more features and enhancements to make building and maintaining your pipelines even better. In the meantime, if you have any questions, please reach out to our friendly support team, who are on hand to help you out.
If you’re new to Upsolver, why not start your free 14-day trial, or schedule your no-obligation demo with one of our in-house solutions architects who will be happy to show you around.
Published in:
Blog
,
Release Notes