
Explore our expert-made templates & start with the right one for you.
Upsolver August 2024 Feature Summary
-
 Rachel Horder
Rachel Horder
- Release Notes
- August 5, 2024
You’ll notice from the list of links below that our engineering team has well and truly smashed it out the park this month! While we continue adding new features to support emerging technologies and ensure we have your technical requirements taken care of, we are always looking for ways to improve the Upsolver UI, simplify data ingestion processes, and ensure your lakehouse operates at optimal performance. And of course the team is committed to crushing every bug as soon as they can.
Ok, I know I’m biased, but this month has been exceptional. We added support for the newly released Polaris Catalog from Snowflake, so you can now use Polaris as a target connection for your ingestion jobs. If, like the rest of us, you’re still trying to get your head around Iceberg and the multitude of catalogs now available, then we have some awesome resources to help. Our August webinar, Getting Started with Snowflake Polaris and Iceberg Tables, will build your knowledge and guide you through the first steps of working with these new technologies. Also, our Iceberg Academy continues to grow, and here you’ll find practical, in-depth training material that is delivered clearly and concisely.
Furthermore, we added the unified observability platform, Dynatrace, as an output for your monitoring jobs. We already offer built-in monitoring and observability in Upsolver, however, you can roll your own jobs to extract the exact stats you want from our system tables and send them to Dynatrace. Our system catalog exposes a wealth of metadata for you to query at will, and I highly recommend you take a look at the documentation and see what is available – even if you don’t use third-party monitoring, the metadata will help you detect and mitigate issues.
We have also made great strides to enhance jobs that ingest from database CDC sources. Replication jobs are a fantastic way for directing data from a single source into multiple destinations, and there are a few exciting (if you like that sort of thing as much as I do!!) developments to be discovered below.
Phew, after all this, even if our engineers don’t need a vacation, I know I do! But, before I pour myself a mojito, can I recommend you check out Chill Data Summit on Tour? CDS is about to head out on the road and is coming to a city near you. This time around, the format is a little different, with a morning of keynotes and talks, followed by hands-on training to build your first Apache Iceberg lakehouse.
The first stop is San Francisco Bay Area on August 15, and the afternoon training will be led by none other than Holden Karau! Tickets are going fast, so don’t hesitate to sign up because it’s going to be awesome!! In the meantime, have a great summer, and I’ll be back in September with another update. Now it’s mojito time! Cheers!
This update includes the following releases:
Contents
- UI
- Jobs
- NEW! Snowflake Polaris Catalog Now Supported
- NEW! Dynatrace Added as Monitoring Output
- Table Retention Column Types Updated for Apache Iceberg Tables
- Fixed a Bug Causing Redundant Columns in Schema Evolution
- Apache Iceberg Dangling Files Issue Fixed
- Number of Catalogs Requests Reduced to Prevent Errors
- Fixed Internal Files Being Deleted Before Being Used
- Bug Fixed to Exclude System Columns
- Fixed Issue When Using System Columns in Ingestion Jobs
- Bug Resolved for Primary Key Numeric Type
- Fixed Scheduling Bug when Compacting Partitions
- Fixed Issue When Ingesting Large CSV Files from S3 to Iceberg
- Compaction Preventing Reading from Hive Tables Fixed
- Bug Fixed Where Data Retention Failed in Old Partitions
- Fixed Issue with Incorrect Job Statistics When Writing to Iceberg
- Join Expressions Issue Affecting Job Monitoring is Fixed
- CDC Jobs
- SQL Queries
- Enhancements
- Table Refresh Interval Added to Apache Iceberg Mirror Tables
- Support Added for Iceberg REST Catalog Connections and Tables
- Performance Improvements Made to High-Load Clusters
- Partition Evolution Supported for Iceberg Tables
- Sorting Evolution is Now Supported for Iceberg Tables
- Create Cluster Using VPC Connection Property
- Support Credential Vending from Iceberg REST Catalogs
- Reduced Overhead of Task Discovery
- Support Added for Creating a Cluster with a Startup Script
UI
Job Monitoring Page Redesigned for Better Execution Tracking
The job monitoring page has been thoughtfully redesigned, allowing you to track job statuses by executions, representing each data interval being processed.
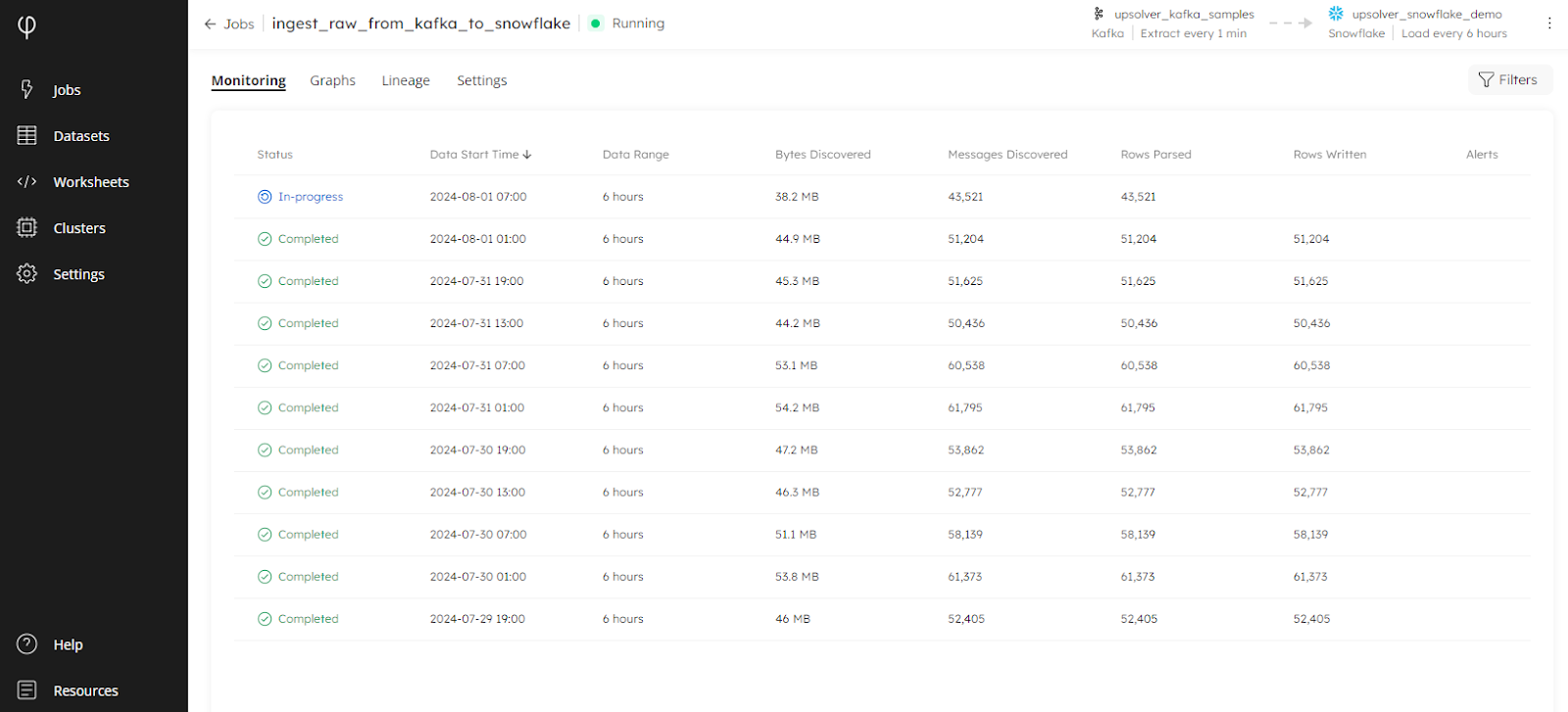
In the example below, the job extracts data from Apache kafka every minute, but writes to the target Snowflake database every six hours:
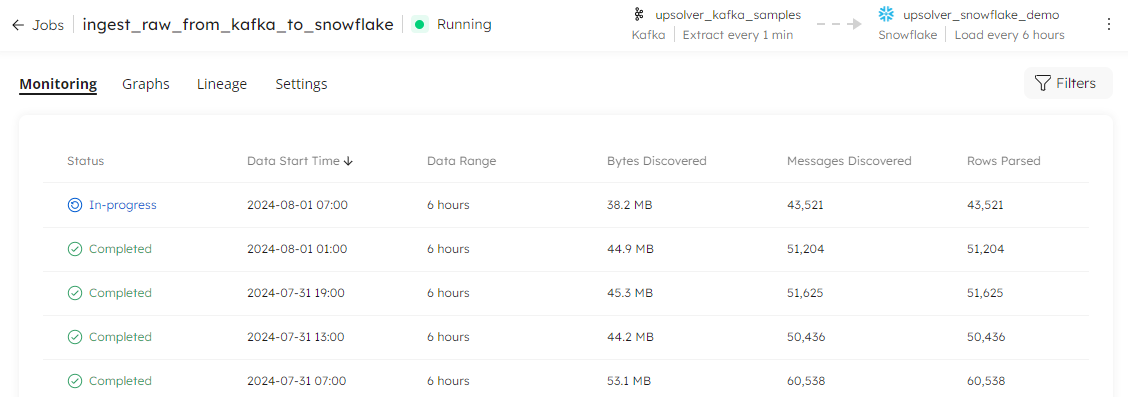
By splitting out each write operation into an individual, trackable row in the reporting table, you can now view the metrics for each job execution with finer granularity. It is much easier to monitor the volume of data discovered at each execution interval, and check that the number of messages discovered matches the number of rows parsed. Alerts are also displayed at the interval level, enabling you to troubleshoot problems much quicker than before.
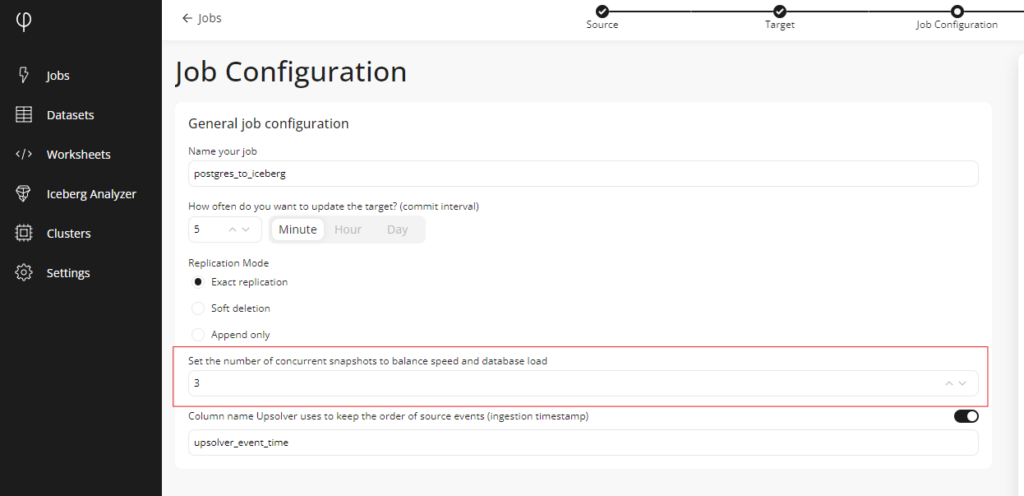
Configure Snapshot Parallelism for CDC Jobs from Wizard
Our zero-ETL ingestion tool makes it quick and simple to ingest data from source to target. When it comes to CDC sources, we facilitate ingesting data from SQL Server, MongoDB, MySQL, and PostgreSQL in just a few easy to follow steps. Prior to this update, you would need to manually code an ingestion job to configure snapshot parallelism outside of the default settings.
Now, with this release, you can configure snapshot parallelism from within our data ingestion wizard, helping you to experience the best possible performance without needing to write a line of code.
Jobs
NEW! Snowflake Polaris Catalog Now Supported
Snowflake’s Polaris Catalog enables open, secure, lakehouse architectures with broad read-and-write interoperability and cross-engine access controls. Polaris Catalog is open source under the Apache 2.0 license and now available on GitHub, while Snowflake’s managed service for Polaris Catalog is now available in public preview.
I’m delighted to announce that you can now configure Polaris Catalog as your default Iceberg Lakehouse catalog, and ingest data from databases, streams, and files into your Iceberg lake with only a few clicks. You can of course take advantage of our Adaptive Optimizer to maximize Lakehouse query performance and cost savings.
Learn more about configuring Polaris Catalog with Upsolver.
NEW! Dynatrace Added as Monitoring Output
I’m excited to announce that we now support Dynatrace as a monitoring output, along with Amazon CloudWatch, and Datadog.
This means you can create jobs in Upsolver that send metrics to your chosen reporting tool to monitor your Upsolver pipelines from a centralized dashboard.
In the example below, we create a job named send_monitoring_data_to_dynatrace that sends metrics from the Upsolver system.monitoring.jobs table to Dynatrace.
CREATE JOB send_monitoring_data_to_dynatrace
START_FROM = NOW
AS INSERT INTO my_dynatrace_connection
MAP_COLUMNS_BY_NAME
SELECT job_id AS tags.id,
job_name AS tags.job_name,
discovered_files_lifetime AS files,
avg_file_size_today AS avg_file_size,
avg_rows_scanned_per_execution_today AS avg_rows_scanned,
cluster_id AS tags.cluster_id,
cluster_name AS tags.cluster_name,
RUN_START_TIME() AS time
FROM system.monitoring.jobs;Learn how to connect to your Dynatrace account, and create a job to continuously send metrics.
Table Retention Column Types Updated for Apache Iceberg Tables
When creating an Upsolver-managed Iceberg table – Upsolver manages the compaction and tuning of the data and metadata files for you – you can include table options to specify the column that should be used for determining the retention, alongside the number of days to retain the data for.
Since we initially released this feature, we have expanded the table option to enable you to set the data retention based on any column of types date, timestamp, timestampz, long, or integer.
If you have already implemented data retention in your Iceberg tables, please note that we have also changed the configuration syntax. Please see the update below, which includes a code example. Alternatively, learn how easy it is to create an Iceberg table with a defined data retention.
Fixed a Bug Causing Redundant Columns in Schema Evolution
We have fixed a bug occurring in jobs writing to Amazon Redshift and Snowflake targets, that created redundant columns when the schema evolved. If the job syntax was using SELECT * in the query, when mapping fields to different types, such as mapping a field of type timestamp to a column of type timestamptz, a redundant column would be produced. Customers should no longer experience this unwanted addition.
Apache Iceberg Dangling Files Issue Fixed
During Iceberg operations, files may become unreferenced or what is known as “dangling”. If these files are left to accumulate, it can lead to increased storage costs. Upsolver performs a daily clean-up of any dangling files to help maintain a tidy and cost-effective storage environment.
A problem was recently discovered with these dangling files, which has now been fixed by moving the backup folder location into the table root directory.
Read more about Optimization Processes for Iceberg Tables in Upsolver.
Number of Catalogs Requests Reduced to Prevent Errors
We have reduced the number of requests to the catalog to prevent rate-exceeded errors when managing a large number of tables.
Fixed Internal Files Being Deleted Before Being Used
We fixed the bug that caused internal files to be deleted before their usage, resulting in the job stalling.
Bug Fixed to Exclude System Columns
The bug that prevented system columns from being referenced in the EXCLUDE_COLUMNS property in ingestion jobs has been fixed.
Fixed Issue When Using System Columns in Ingestion Jobs
Sometimes it is necessary to transform data before it lands in your target, perhaps because data should be masked for privacy purposes, or requires shaping before it lands in the destination. The COLUMN_TANSFORMATIONS job option provides a flexible solution for transforming your in-flight data, but we recently encountered a bug that prevented system columns from being used with this option. I’m delighted to say that we have now fixed this issue.
Bug Resolved for Primary Key Numeric Type
A bug was occurring when the primary key was a numeric type and the table was large enough to require chunk splitting.
Fixed Scheduling Bug when Compacting Partitions
We fixed a bug where it was possible to schedule compactions for partitions in tables without a primary key, even after the retention period, leading to errors.
Fixed Issue When Ingesting Large CSV Files from S3 to Iceberg
An issue occurred when creating jobs ingesting from Amazon S3 with large CSV files, to Iceberg tables.
Compaction Preventing Reading from Hive Tables Fixed
An issue arose in jobs reading data from Hive tables, where data loss occurred due to committing compacted files in the source table with the wrong timing.
Bug Fixed Where Data Retention Failed in Old Partitions
In rare conditions in tables with a data retention policy, background jobs failed to delete some of the files in old partitions. This is now fixed.
Fixed Issue with Incorrect Job Statistics When Writing to Iceberg
In jobs writing to Iceberg with an interval longer than 1 minute, job statistics were not being displayed in the monitoring page. This issue has been addressed and the statistics are now visible.
Join Expressions Issue Affecting Job Monitoring is Fixed
The job monitoring page was also affected by a bug in jobs writing to Iceberg tables that included a JOIN expression. This is now resolved.
CDC Jobs
Support Added to Re-Snapshot MongoDB Collections
If you have replication jobs reading changes (CDC) from a MongoDB database, you’ll be pleased to hear we now support the ability to re-snapshot a collection.
Replication jobs are a powerful solution for ingesting data from a CDC source to multiple targets. Each target, defined in a replication group, functions independently of the other groups within the job, despite sharing a dataset.
If you want to ingest your sales data from an operational, CDC-enabled database, you can send one set of data to your production target to be used by stakeholders for reporting, and the other set can be copied to a development target, to be used in a raw format by your data engineers.
Let’s look at an example of how this works. In the example below, we create a replication job named replicate_mongodb_to_snowflake, that outputs to two targets, each defined within its own replication group: replicate_to_snowflake_prod and replicate_to_snowflake_dev. Each group is configured to support a different use case, but both read from the orders schema.
CREATE REPLICATION JOB replicate_mongodb_to_snowflake
COMMENT = 'Replicate MongoDB CDC data to Snowflake groups'
COMPUTE_CLUSTER = "Default Compute (Free)"
INTERMEDIATE_STORAGE_CONNECTION = s3_connection
INTERMEDIATE_STORAGE_LOCATION = 's3://upsolver-integration-tests/test/'
FROM my_mongodb_connection
WITH REPLICATION GROUP replicate_to_snowflake_prod
INCLUDED_TABLES_REGEX = ('orders\..*')
EXCLUDED_COLUMNS_REGEX = ('.*\.creditcard') -- exclude creditcard columns
COMMIT_INTERVAL = 5 MINUTES
LOGICAL_DELETE_COLUMN = "is_deleted"
REPLICATION_TARGET = my_snowflake_connection
TARGET_SCHEMA_NAME_EXPRESSION = 'ORDERS'
TARGET_TABLE_NAME_EXPRESSION = $table_name
WRITE_MODE = MERGE
WITH REPLICATION GROUP replicate_to_snowflake_dev
INCLUDED_TABLES_REGEX = ('orders\..*')
COMMIT_INTERVAL = 1 HOUR
REPLICATION_TARGET = my_snowflake_connection
TARGET_TABLE_NAME_EXPRESSION = 'history_' || $table_name
TARGET_SCHEMA_NAME_EXPRESSION = 'ORDERS_DEV'
WRITE_MODE = APPEND;You can then use the RESNAPSHOT COLLECTION command to re-take a snapshot of the orders_collection that is used by the replicate_mongodb_to_snowflake job.
ALTER JOB replicate_mongodb_to_snowflake
RESNAPSHOT COLLECTION orders_collectionFor more information, please read the article Performing Snapshots, which explains how the process works in Upsolver. This article is also applicable if you are replicating data from SQL Server, MySQL, or PostgreSQL.
Configure Primary Key Column in Replication Groups
As mentioned above, replication jobs utilize special replication groups to copy a single dataset to multiple locations, each using its own set of configurations. We added a new property PRIMARY_KEY_COLUMN to replication groups to enable you to configure the primary key column within each replication group.
Fixed a Bug in CDC to Redshift Jobs Creating Columns of Incorrect Type
We fixed a bug occurring in jobs ingesting CDC data to Amazon Redshift, which caused the creation of columns with incorrect types.
Fixed the Bug Creating Additional Column in Redshift Target
We also fixed the bug that caused an additional column to be created when writing a field of type timestamp to a column of type timestampTZ in Amazon Redshift.
SQL Queries
Data Retention Syntax Properties Changed for Iceberg Tables
If you are using the retention options in your Upsolver-managed Apache Iceberg tables, please be aware that we have changed the configuration properties. As you may have read above in the Jobs section, since we first released the retention option, we have expanded the supported column types to include date, timestamp, timestampz, long, or integer. To enable this expansion, we have updated the property TABLE_DATA_RETENTION to RETENTION_DURATION, and RETENTION_DATE_PARTITION to RETENTION_COLUMN.
For example, to create a table named orders_data in Apache Iceberg, with a retention of 7 DAYS, based on the order_date column, use the properties as follows:
CREATE ICEBERG TABLE default_glue_catalog.my_database.orders_data
(
order_id string,
order_date date,
customer_email string,
net_total bigint,
num_items bigint,
customer_address string,
customer_city string,
customer_state string,
customer_zipcode bigint
)
PARTITIONED BY order_date
RETENTION_COLUMN = order_date
RETENTION_DURATION = 7 DAYS
PRIMARY KEY order_id
ORDER BY net_total DESC, order_date ASC
STORAGE_CONNECTION = s3_connection
STORAGE_LOCATION = 's3://bucket/storage_location'
COMPUTE_CLUSTER = "my cluster"
DISABLE_COMPACTION = false
iceberg."read.split.planning-lookback" = '10'
COMMENT = 'Orders table';[Link to Jobs Item]
Learn how to create Apache Iceberg tables with Upsolver.
START_FROM Syntax Update to Jobs Ingesting from Amazon S3
The START_FROM job option instructs Upsolver as to the point in time to begin ingesting data. You can use NOW, BEGINNING, or a timestamp for a specific date and time.
We have updated the syntax for jobs ingesting from Amazon S3, so you cannot include the START_FROM option, unless the DATE_PATTERN option is also specified.
Please read the documentation for in-depth help on using DATE_PATTERN.
Fixed Casing Issue in Mapped Columns for MERGE Jobs
Fixed a bug in MERGE jobs where the ON condition had a different case than the mapped column in the SELECT clause
Fixing Bug in JOIN Expression Returning NULLs
Fixed a bug in jobs writing to a table where a JOIN expression with an uppercase alias caused the joined row to return NULLs in all fields
Fixed Multi Fields Issue in Column Transformations to Iceberg
We fixed a problem in jobs writing to Iceberg that included the COLUMN_TRANSFORMATIONS option. When the column transformation overrode a field, which appeared with a different case in the data, this resulted in multiple fields of different types.
Enhancements
Table Refresh Interval Added to Apache Iceberg Mirror Tables
We recently announced support for Iceberg Table Mirroring to Snowflake, a new feature that ensures data engineers view the freshest data when querying their Iceberg tables from Snowflake. We automated a manual process that would otherwise demand on-going effort to update the snapshot in Snowflake every time a change is made in Iceberg.
Our table mirroring feature mirrors data in Iceberg to a table in Snowflake, so that users work with the newest data, engineers no longer need to orchestrate tasks to update the snapshot in Snowflake, and the refresh operation is only performed when changes are made, thereby eliminating unnecessary costs.
We have added a new table option that defines or alters the mirror table refresh interval. Using MIRROR_INTERVAL, you can specify how frequently Upsolver refreshes the data.
The default mirror interval value is one minute, but you can set this according to your requirements. For example, we can create a table in Snowflake that is updated hourly:
CREATE MIRROR FOR default_glue_catalog.demo.my_iceberg_table
IN my_snowflake_connection.mirror_demo_schema.mirror_iceberg_tbl
CATALOG_INTEGRATION = my_catalog_int
EXTERNAL_VOLUME = iceberg_volume
MIRROR_INTERVAL = 1 HOUR;Follow this guide for an end-to-end walkthrough on how to Query Upsolver Iceberg Tables from Snowflake.
Support Added for Iceberg REST Catalog Connections and Tables
Users can now create Iceberg REST catalog connections and add tables.
Performance Improvements Made to High-Load Clusters
We have implemented several performance improvements to high-load clusters to ensure your experience is optimal.
Partition Evolution Supported for Iceberg Tables
We now support the ability to dynamically change or disable the partition columns of your Iceberg tables. When changing the partition, this does not rebuild the existing data according to the new partitioning but will apply the new partitioning to data moving forward.
In the example below, to change the partition column of the web_orders table to order_date, simply use the following command:
ALTER TABLE web_orders PARTITION BY order_date;To stop partitioning the web_orders table, use the following syntax:
ALTER TABLE web_orders PARTITION BY ();Sorting Evolution is Now Supported for Iceberg Tables
We also support the ability to change or disable the sort order of data in your Iceberg tables. This enables you to dynamically change the sorting columns of an existing table, and affects future data that is written, and new compactions will write data using the new sorting.
To change the sort column of the web_orders table from shipped_date to order_date, simply use the following command:
ALTER TABLE web_orders ORDER BY order_date;Optionally, you can re-sort the existing data that was sorted by shipped_date, to be sorted by order_date, using the OPTIMIZE function:
OPTIMIZE TABLE web_orders REWRITE DATA;To remove all sorting from the web_orders table, run the following:
ALTER TABLE web_orders ORDER BY();Learn more about altering your Iceberg tables.
Create Cluster Using VPC Connection Property
If you have multiple VPC connections in your organization, you can now use the VPC_CONNECTION property with the CREATE CLUSTER syntax to specify which VPC to use. Running this command without the option will generate an error if you have multiple VPC connections.
Support Credential Vending from Iceberg REST Catalogs
Credential vending is a mechanism that provides dynamic and secure access to data storage systems, such as cloud object stores, e.g., AWS S3. This process is crucial in environments where security and data access control are of paramount importance. Rather than using static credentials that are hard-coded into the application or configuration files, credential vending involves dynamically generating or retrieving credentials when needed. This reduces the risk of credential leakage and ensures that access can be controlled and audited more effectively.
In Apache Iceberg, credential vending might be used to securely access data stored in external storage systems. For example, when a user or application interacts with Iceberg tables stored in a cloud object store, the Iceberg system can use credential vending to obtain the necessary credentials at runtime. This allows Iceberg to manage data securely without embedding sensitive information in the application code or configuration.
Reduced Overhead of Task Discovery
We have reduced the overhead of task discovery, especially in compute clusters with a lot of assigned entities, or a large number of shards
Support Added for Creating a Cluster with a Startup Script
You can now create a cluster that uses a startup script. We added the STARTUP_SCRIPT option, which can be used with both CREATE CLUSTER and ALTER CLUSTER.
Thanks for making it through this very long list of updates, I hope you found them useful. If you have any questions, please reach out to our friendly support team, who will be happy to help.
I’ll be back in the Fall, but in the meantime, please follow Upsolver on LinkedIn for the latest news, or book a demo if you fancy a test drive.
Published in:
Blog
,
Release Notes
