
Explore our expert-made templates & start with the right one for you.
Looking for Tabular alternatives? Compare lakehouse management tools
-
 Roy Hasson
Roy Hasson
- Cloud Architecture
- July 9, 2024
This article is an excerpt from our comprehensive technical comparison paper, Tabular vs. Upsolver: A Detailed Comparison of Lakehouse Management Tools. If you’re exploring alternatives to Tabular, we strongly recommend reviewing this paper to understand the underlying mechanisms and approaches of each solution.
Choose the right table optimization and maintenance service to ensure efficient and consistent performance for your analytics and ML users. Find out how Upsolver can fill the gap and become your Lakehouse engine of choice for ingesting into, transforming, maintaining and optimizing Iceberg tables.
What to look for in a Tabular alternative?
Tabular was founded by the original creators of Apache Iceberg, and has been the gold standard for implementing Lakehouse services using Iceberg tables. But with the company’s recent acquisition, many companies are looking for tools that can handle the full scope of lakehouse management. Upsolver is a leading choice for high scale workloads on AWS.
Compare Upsolver to Tabular based on:
- Data ingestion capabilities
- Iceberg table optimization
- Data movement and transformation
- Performance and results
Capability and feature comparison – Upsolver vs Tabular
The Basics
| Upsolver | Tabular |
| Upsolver is the only independent, mature Lakehouse management solution for Iceberg available on the market today. Learn more about Upsolver ↗ | Tabular has been acquired by Databricks and no longer offers an independent product.Learn more about Databricks acquiring Tabular ↗ |
1. Data Ingestion Capabilities
| Upsolver | Tabular | |
| Ingestion method | Continuous ingestion | Batch file loader |
| Additional infrastructure required | No additional infrastructure to set up or manage | Debezium and Spark needed to support CDC |
| Support for schema evolution | Built in | Separate engineering effort |
| Deduplication | Built in | Separate engineering effort |
| Observability and quality control | Built in | Separate engineering effort |
Detailed breakdown:
Upsolver: Continuous data ingestion
Upsolver provides full-featured, continuous data ingestion from popular file, stream and database sources into Iceberg using native, high-volume connectors. There is no additional infrastructure to set up or manage. Upsolver automatically detects and evolves schemas, deduplicates rows, validates data quality, merges updates/deletes using Iceberg transactions and continuously optimizes and maintains tables.
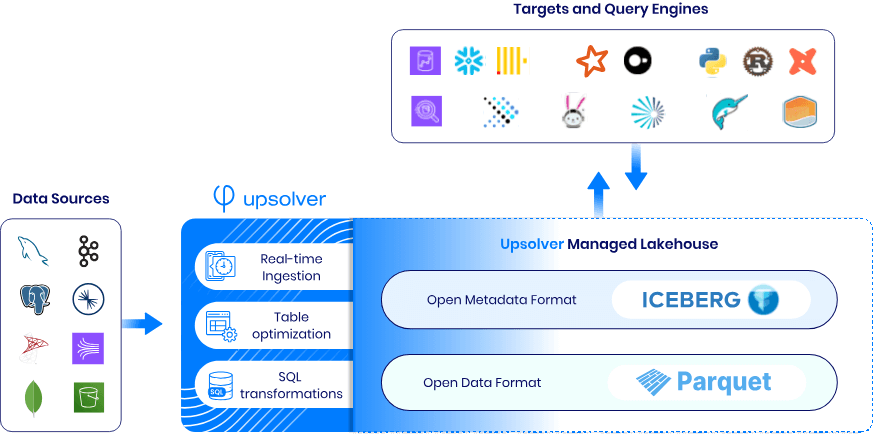
Tabular: Batch file loader
Tabular provides a barebones file-loader utility that allows you to ingest data from object stores into Iceberg tables. This is a batch operation that periodically loads new files as they arrive in your object store directory.
Tabular also supports replicating data from database sources using CDC. However this approach requires you to:
- Deploy and manage AWS DMS or Debezium to extract CDC events
- Run Kafka or Kinesis to stream CDC events to a collector
- Manage Kafka Connect (collector) to write events into staging Iceberg tables
- Develop and run Spark jobs to merge staged events into your final table
The file loader and database replication approaches lack robust schema evolution, deduplication, data quality and observability controls. They require lots of engineering, custom code and maintenance to keep all of the components operational leading to frequent downtime and potential corruption of data.
Learn more about data ingestion with Upsolver ↗
2. Table Optimization
| Upsolver | Tabular | |
| Optimization method | Adaptive optimization | Periodic compaction |
| Compaction and partitioning frequency | As needed based on continuous monitoring of data files | Predefined, typically every 2-3 hours |
| Performance benefit | Consistent improvement | Unpredictable periods of degraded performance during compaction cycles |
| Engineering effort required | None | Constant tuning |
Detailed breakdown:
Upsolver: adaptive optimization
Upsolver implements adaptive optimization techniques and algorithms that continuously monitor data files, partitions and access patterns and automatically optimize data files and layout to accelerate queries and reduce storage size. Adaptive optimization eliminates the need for engineers to constantly test and tune different configurations. It works automatically, adjusting to any workload, data volume and velocity.

Upsolver’s adaptive optimization results in consistent query performance
Tabular: periodic compaction
Tabular and similar batch-based Lakehouse engines, relies on periodic compaction, typically occurring every 2-3 hours. While this method eventually optimizes tables, it introduces periods of suboptimal performance, particularly for continuous workloads like Change Data Capture (CDC). The timing and duration of compaction cycles can significantly impact query performance and storage efficiency, making it less reliable for real-time analytics. In addition, Tabular requires engineers to constantly configure, test and tune optimization parameters and technique to maintain a performant and cost-effective Lakehouse as workloads, data volume and velocity change.
Learn more about optimization techniques for the Iceberg lakehouse ↗
3. Data movement and transformation (ETL)
| Upsolver | Tabular | |
| Transformation capabilities | Upsolver Live Tables | Unavailable |
| Syntax | Declarative (GUI) or SQL | Managed separately, typically in Spark (Java / Scala) |
| Complex transformations | Built in streaming joins,, aggregations, enrichment, stateful and stateless transformations | Unavailable |
| Pipeline management | Automatic orchestration, state management, task and job syncing, failure recovery and scaling | Unavailable |
| Compatibility with multiple readers and writers | Available with built in snapshot isolation and conflict resolution | Unavailable |
Detailed breakdown:
Upsolver: Iceberg Live Tables
Upsolver’s Iceberg Live Tables is a declarative ETL framework that makes it easy for engineers and analytics users to build batch and streaming pipelines using only SQL. Users simply define the set of transformations to perform and Upsolver automatically and continuously materializes rows into your target Iceberg table – fresh, fully optimized and ready to query.
Users can build arbitrarily complex transformations, link multiple jobs together, enrich events using external sources, implement stateful and stateless transformations and much more. Upsolver automatically manages task orchestration, state management, task and job syncing, failure recovery, data type conflict resolution and cluster scaling.
Upsolver leverages Iceberg transactions to enforce snapshot isolation and conflict resolution. This allows other engines, not just Upsolver, to read and write to the Iceberg Live Tables without breaking the pipelines or corrupting data.

Upsolver Iceberg Live Tables makes streaming to Iceberg tables simple.
Tabular: No ETL or ELT available
Tabular does not provide any ETL capability, in effect providing partial Extract (E) and minimal Load (L) functionality requiring users to implement their own Transformation (T) using alternative tools. Even for simple tasks like merging CDC events into a target table (part of CDC ingestion) or implementing quality controls or hashing and masking sensitive data requires implementing and managing another tool, like Spark. This makes it far more difficult for software and data teams to build, load and work with data in their Iceberg Lakehouse.
See Upsolver transforms in action with a free trial of Iceberg Live Tables ↗
4. Performance and Results
Switching to Upsolver gains you 25% faster queries and 32% less storage compared to Tabular. More in this benchmark. Here is how Amazon Athena (managed Apache Trino) fared between Upsolver and Tabular managed Iceberg tables.

Watch the video: Comparing Iceberg Performance – Upsolver, AWS Glue, Tabular and Snowflake
Try the ultimate Tabular alternative – free
Using Tabular today? Want to continue delivering best query performance for analytics and ML users, while saving money and remaining agile to support new use cases?
→ Use Upsolver’s Adaptive Optimizer for existing Iceberg tables. Start free
→ Try Upsolver’s Iceberg Live Tables to ingest, prepare and optimize your data in real time. Start free→ Find out how Upsolver can fit with your specific needs by booking 30 minutes with our solution architect today – no sales, just tech. Chat with our team
Published in:
Blog
,
Cloud Architecture