
Explore our expert-made templates & start with the right one for you.
Upsolver Announces Support for Polaris Catalog
-
 Roy Hasson
Roy Hasson
- Upsolver News
- August 23, 2024
Upsolver is excited to announce its new integration with Polaris Catalog. The integration allows users to easily ingest, maintain and optimize data stored in Apache Iceberg format, enabling interoperability between Snowflake, Starburst, PuppyGraph, Apache Spark, Apache Flink, Apache Trino, Apache Presto, DuckDB and other popular analytics and AI tools.
Upsolver is an industry leading Lakehouse management solution used by customers to ingest, transform, maintain and optimize large scale Lakehouses leveraging the power of Apache Iceberg table format. With this new integration, organizations can deliver analytics and AI projects faster by enabling users to collaborate on high-quality data from their choice of tool, without exporting, duplicating or moving data around. Upsolver automatically catalogs Iceberg tables in Polaris Catalog and continuously optimizes them to accelerate queries, delivering performance on par with Snowflake native table format.
What is Polaris Catalog
Polaris Catalog is a technical metadata catalog based on the Apache Iceberg REST specification that allows engines to collaboratively and safely update and query Iceberg tables. It enables an open and secure lakehouse architecture with true read-and-write interoperability and cross-engine access controls. Polaris Catalog is open source under the Apache 2.0 license and available on GitHub. Snowflake’s managed service for Polaris Catalog is also available in public preview (as of July 30, 2024).
Today, Polaris Catalog offers 4 main capabilities:
1. Iceberg REST spec-compatible APIs that allow any compliant client, like Upsolver, to fully interact with catalog services to create, update, delete namespaces and tables, and read and write table data using transactions.
2. Simple to use Resource Based Access Controls (RBAC) that lets you control access to reading and writing both table data and metadata, as well as creating, updating and deleting catalog resources.
3. Object store credential vending which simplifies how you control and delegate access to the underlying storage across engines. Traditionally, you’d need to configure each engine with the appropriate role and credentials, like the IAM role in AWS, to give it read and write permissions to S3. This course grained access didn’t allow you to scope permissions to specific users or groups of users. With credential vending, Polaris Catalog maps the RBAC permissions you configure for a user or group to a scoped down set of object store (S3) permissions that are automatically given to the query engine on the user’s behalf. Engines use these permissions to read or write data.
4. Two deployment models, self-hosted and fully-managed, that provide flexibility and control. Polaris Catalog is available as open source and can be self-hosted on your local machine or on a Kubernetes cluster for production use. In addition, Snowflake offers a fully managed version of Polaris Catalog that can be used by Snowflake customers or new users that are not Snowflake customers today. This gives you the option to evaluate and use Polaris and when you need reliability and enterprise support, you can easily move to a fully managed offering.
How does this help you, the Snowflake user?
Snowflake makes it easy to process, share and analyze vast amounts of data. However, as organizations expand into more advanced analytics and AI projects they need to use a variety of tools, each often demanding its own copy of the data. Traditionally, users needed to export or copy data from Snowflake into an object store and then load that data into their tool of choice. This duplication of data results in high storage costs, difficulty providing a consistent, high quality view of the data to every tool and exposing organizations to data privacy risks.
With the new integration, Snowflake users can now store only one copy of their data in Amazon S3 using the Iceberg table format. Tables are registered and exposed in Polaris Catalog allowing users to query them from Snowflake, as well as other engines like Apache Spark, Dremio, PuppyGraph and DuckDB. With Upsolver, users configure their lake and define ingestion tasks in a single place. The platform continuously and automatically merges, optimizes and maintains Iceberg tables. This ensures consistent performance across engines, auditable retention and data cleanup, and lower storage costs.
Getting started with Upsolver and Polaris Catalog
Users can get started with Polaris Catalog by downloading and self hosting the open source version available in the Polaris-Catalog repository on Github, or by simply using the Snowflake service for Polaris Catalog. Users can get started with Upsolver by signing up for free, connecting to Polaris Catalog and with a few clicks begin to ingest data from popular sources into Iceberg tables.
Lets see how to ingest tables from PostgreSQL into an Iceberg Lakehouse, catalog them in Polaris Catalog and query using Snowflake:
1. Configure Polaris Catalog service: Follow the instructions in the Snowflake documentation to sign up for Polaris Catalog. This is the version managed by Snowflake and is easier to set up and get started. Snowflake also offers a trial experience for users who are not customers of Snowflake. Continue to configure the appropriate catalog roles and create the necessary S3 bucket and IAM permissions needed to read and write data in Amazon S3.
2. Deploy an Upsolver replication task: If not already, sign up for Upsolver, it’s completely free. Once logged in, choose “Ingest Data” from the welcome screen.
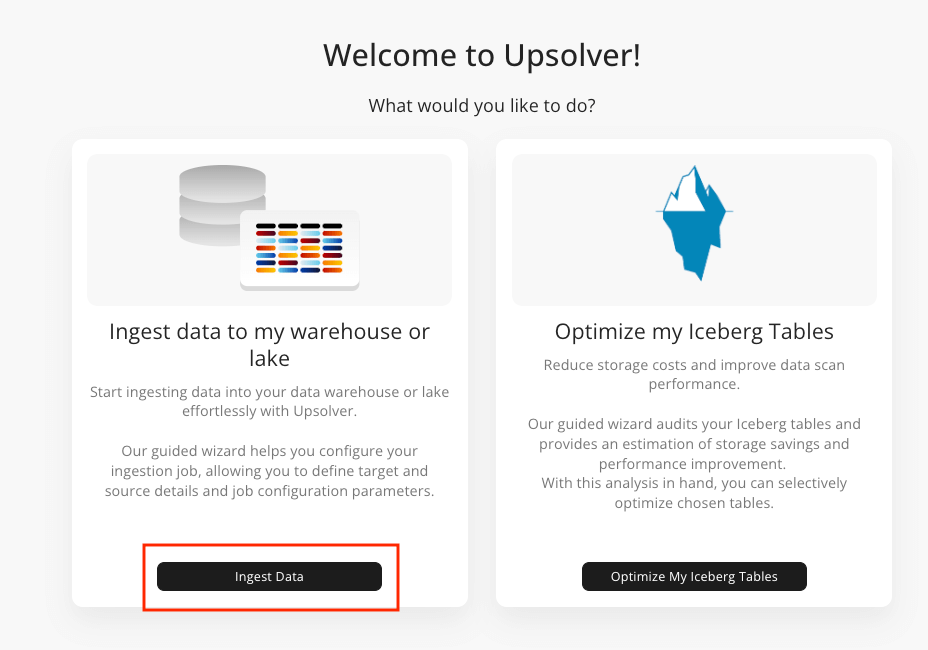
2a. Select source and target: From the wizard select PostgreSQL as your source and Polaris Catalog as your target. Follow the prompts to configure source and target credentials then verify the connection.
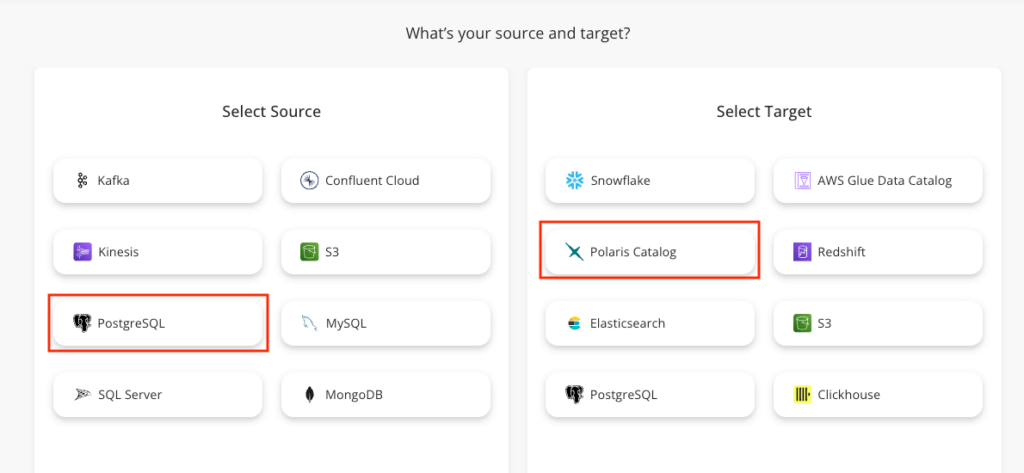
2b. Choose your tables: Choose the tables to replicate and follow the prompts to complete the configuration and finish by clicking Run to execute the replication job. It’s that simple.
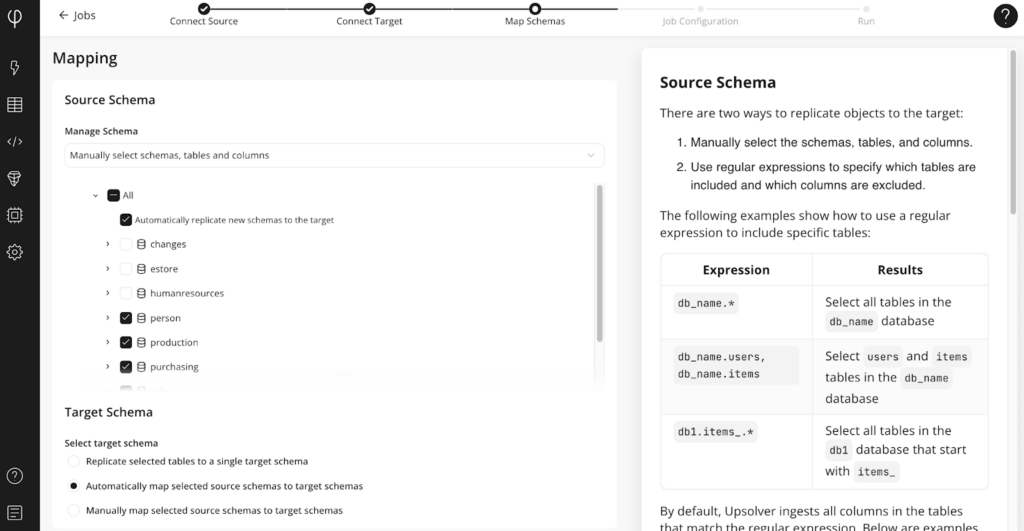
NOTE that currently, Snowflake doesn’t support Iceberg deletes and therefore requires Upsolver to write rows in append-only or soft-delete mode. In the Job Settings screen select the Append Only or Soft Deletion replication mode as shown below:
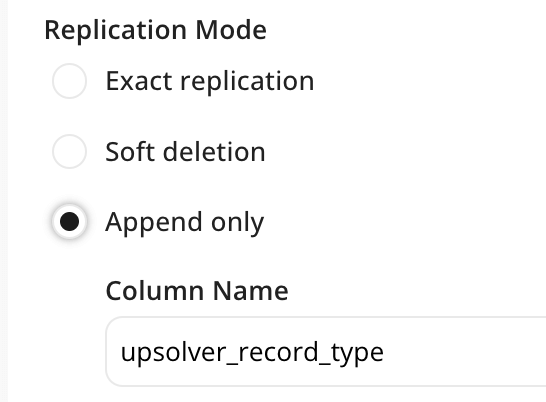
After data has been replicated, you can merge rows using Dynamic Tables or SQL transformations that would delete rows accordingly. In the future, when Snowflake adds support for deletes, you can switch your pipeline to Exact Replication which will perform deletes automatically without additional code.
3. Inspect progress and data health: To replicate data into Iceberg, Upsolver first copies a current snapshot of the table and once complete begins to replicate on-going changes (CDC). Upsolver will automatically insert, update or delete rows by matching on the primary key column. The Upsolver Adaptive Optimizer continuously monitors and optimizes data and delete files to keep table size to a minimum and accelerate queries on live (current partition) and historical (all partitions) data.
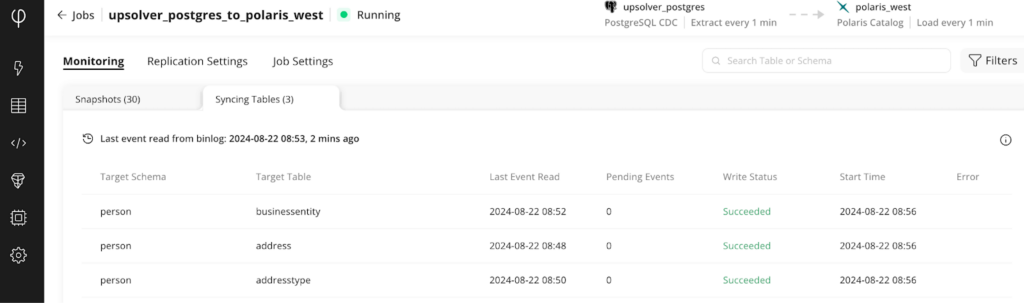
4. Configure Snowflake to query via external Polaris Catalog: Follow the steps in Query a table in Polaris using Snowflake to connect Snowflake to an external catalog. We’re choosing to configure Snowflake with an external catalog which allows Upsolver to manage the Iceberg table on your behalf. It also allows other engines, not just Snowflake, to query the same table.
5. Query table with Snowflake: Now that your Iceberg tables are created, loaded with data and optimized, switch to the Snowflake console and query your Iceberg table.
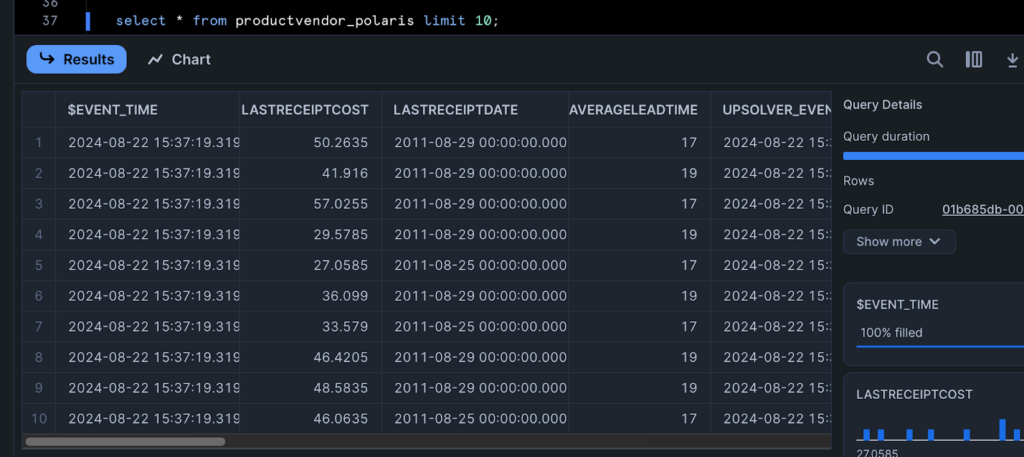
Upsolver + Polaris Catalog = Open Lakehouse
Upsolver’s Lakehouse management platform makes it easy for teams to build, maintain, optimize and scale their Iceberg lakes with little to no engineering effort. Users can now continuously ingest from databases, streams and files directly into Iceberg tables cataloged and secured by Polaris Catalog. Together, Upsolver and Polaris Catalog allow companies to create a unified lakehouse that provides governed access to all of their data from popular analytics and AI engines enabling collaboration and accelerating innovation.
Get started with Upsolver today by signing up for free, or schedule a demo with data engineer.
Published in:
Blog
,
Upsolver News
