
Explore our expert-made templates & start with the right one for you.
Achieving Upserts with Snowpipe in Snowflake: Strategies and Alternatives
-
 Upsolver Team
Upsolver Team
- Building Data Pipelines
- May 2, 2023
Working or considering working with Snowpipe? Explore the depths of Snowpipe’s data loading service with our comprehensive cheatsheet. Discover how to create stages, pipes, and load data efficiently. Gain insights on handling semi-structured data, optimizing performance, managing costs, and effectively troubleshooting errors [Download here].
Snowpipe is a powerful tool for low-latency, frequent data loading into Snowflake from small files in supported external or internal stages. However, it doesn’t support upsert logic directly, which can leave users searching for alternative methods to achieve upsert functionality. In this article, we’ll explore different approaches to perform upserts when using Snowpipe in Snowflake. (For a similar topic, see our article on Snowpipe Streaming)
Understanding Snowpipe Limitations
Snowpipe is designed for minimal data transformation during the loading process, utilizing the COPY statement. As a result, it doesn’t support the execution of a sequence of commands or MERGE INTO operations at ingestion time. Instead, once data is loaded into a Snowflake table, you can leverage Tasks and Streams to manipulate the data further.
Alternatives for Upserts with Snowpipe
Tasks and Streams
While Snowpipe does not directly support upserts, you can leverage Tasks and Streams to manipulate data after it has been loaded. By using Snowflake’s Change Data Capture (CDC) functionality known as Streams, you can ingest new data as it arrives. Tasks can be scheduled on top of Streams, allowing you to run multiple tasks on a single table, share, or view.
To perform upserts using Tasks and Streams, you’ll need to:
a. Create a Task that uses the MERGE INTO statement for upserts.
b. Schedule the Task to run at a desired frequency.
c. Use Streams to identify new data and apply the Task accordingly.
External Tables and Materialized Views
If using Snowpipe is not a strict requirement, consider using external tables. Snowflake supports multiple file formats, such as Parquet, CSV, JSON, Avro, and ORC, which may offer improved performance. Once you’ve set up an external table, you can create a Stream or Materialized View on top of it to enable upsert functionality.
Snowflake Data Pipelines
Another alternative is Snowflake Data Pipelines, which also utilize the Stream concept. Data Pipelines can help you process and transform data after it has been loaded into Snowflake tables. You can create multiple Data Pipelines on a single table, allowing for more granular control over data manipulation.
When designing a solution for upserts with Snowpipe, be aware of Snowflake’s micro-partition management. Since micro-partitions are immutable, MERGE INTO operations result in the creation of new micro-partitions while committing the previous ones to the Time-Travel period. This can lead to an increased number of Time-Travel and Fail-Safe micro-partitions, affecting costs and performance. To manage this effectively, consult Snowflake’s documentation on managing costs for large, high-churn tables.
Upsolver’s Big Data Ingestion Tool
Another powerful option is Upsolver, a data ingestion platform that provides advanced capabilities for ingesting, processing, and preparing data for analytics. Upsolver can be an excellent choice for users who require advanced data pipeline features that Snowpipe does not provide, such as upserts and schema evolution.
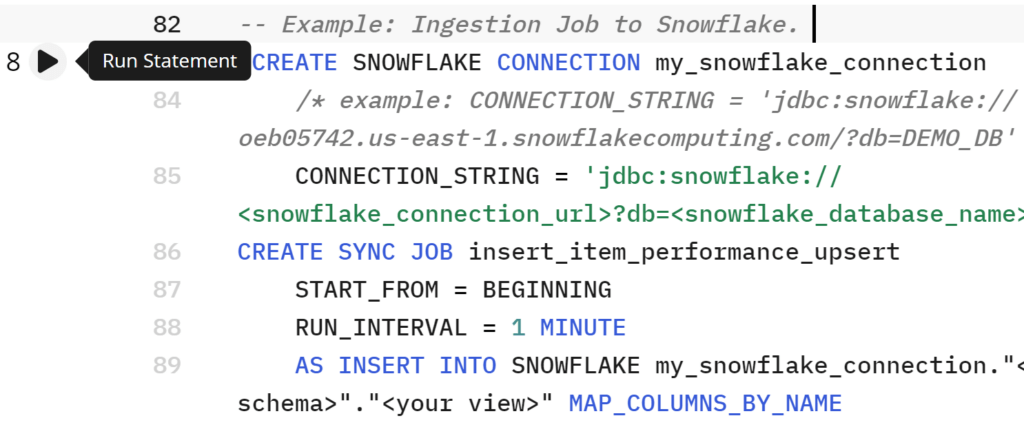
Upsolver’s Advantages
Upsolver offers several benefits as an alternative to Snowpipe:
- Versatility: Upsolver supports both streaming and batch data pipelines, making it a flexible solution for various data processing needs.
- Scalability: Upsolver efficiently handles a high volume of small files and large files, ensuring optimal performance for different data sizes with auto-scaling.
- Data accuracy: Upsolver ensures precise, on-time, exactly-once, and strongly ordered data, reducing the risk of data inconsistencies and errors.
- Advanced features: The platform detects drift, supports schema evolution, and enables upserts and replay, offering a more comprehensive solution for data processing and transformation.
- Monitoring and observability: Upsolver includes a monitoring and observability suite with inspection, profiling, and alerting capabilities, which helps you track and optimize your data pipelines effectively.
- Competitive pricing: Upsolver offers competitive pricing for high-scale ingestion, making it a cost-effective solution for organizations dealing with large volumes of data.
To explore Upsolver as an alternative to Snowpipe for upserts and other advanced data pipeline features, you can schedule a quick, no-strings-attached demo with a solution architect. This will allow you to learn more about Upsolver’s capabilities and understand how it can address your specific data processing and transformation requirements.
Conclusion
In conclusion, Upsolver is a powerful alternative to Snowpipe for users who require advanced data pipeline features like upserts and schema evolution. By evaluating different solutions like Tasks and Streams, external tables, Snowflake Data Pipelines, and Upsolver, you can identify the most suitable option for your data ingestion and processing needs, while considering factors such as performance, costs, and scalability.
Published in:
Blog
,
Building Data Pipelines