
Explore our expert-made templates & start with the right one for you.
Protecting PII & Sensitive Data on S3 with Tokenization
-
 Eran Levy
Eran Levy
- Use Cases
- February 24, 2020
The following article is an excerpt from our new guide: Compliant and Secure Cloud Data Lakes: 3 Practical Solutions (available now for FREE).
Data security is more important than ever: During 2019, there was an increase in cyber-security crimes involving data breaches, with the global average cost of a single data breach reaching a staggering $3.92 million (according to a study by the Security Intelligence institute). These numbers are only expected to increase in coming years.
Further concerns are fuelled by an increasingly demanding regulatory environment. New data privacy mandates such as EU’s GDPR as well as the California Consumer Privacy Act (CCPA) which just took effect at the beginning of 2020, have increased the need to guard data, specifically personally identifiable information (PII).
Data Security in the Age of Data Lakes
The growth of cloud data lakes presents new challenges when it comes to protecting personal data. With databases, sensitive data can be protected by enforcing permissions on the table, row and column level – as long as we know where which tables contain sensitive information, it was relatively straightforward to create a data governance strategy that prevents this data from reaching unauthorized hands.
However, with data lakes things are a bit trickier since you are now responsible for raw data in files rather than tables with known metadata. When data stored in unstructured object stores such Amazon S3, Google Cloud Storage and Azure Blob Store, it is very difficult to pinpoint the location of sensitive data in order to create an effective permissions policy.
Let’s look at this problem through the prism of a hypothetical business challenge, and see how we can solve it using S3 partitioning and tokenization.
Business Scenario: Fine-grained Protection of Financial Data
Consider the following scenario: An ecommerce company stores a log of customer transactions. This contains sensitive data (credit card numbers) and PII (addresses, phone numbers) which should only be accessible for very specific cases, such as chargebacks. At the same time, analysts are querying this data to generate insights into purchasing trends, which are shared across the organization.
We want to ensure all the data is stored securely and encrypted in our data lake; in addition, we want an extra layer of security for the sensitive financial information, making it completely inaccessible by both the analysts and the people accessing their reports. At the same time, we want to ensure the non-sensitive data is accessible without forcing the analyst to jump through too many hoops.
Building the Solution using S3 Partitioning, Retention and Permissions
Our solution is built on tokenizing the sensitive fields in our data, while keeping the rest of the data as-is. We are using tokenization rather than masking (read about the differences here) since the original, sensitive data still needs to be accessible in some instances such as chargebacks, customer cancellations and fraud investigation.
In this approach, we replace each protected field with a single encrypted value based on the original value using an SHA-256 hash function. We will store the mapping between each tokenized field and the original value in an Upsolver Lookup Table, which is also stored in our data lake. We will also set a short retention policy for the raw data, deleting it every 24 hours, to further ensure that the non-tokenized data does not fall into the wrong hands.
Reference architecture (click to enlarge)
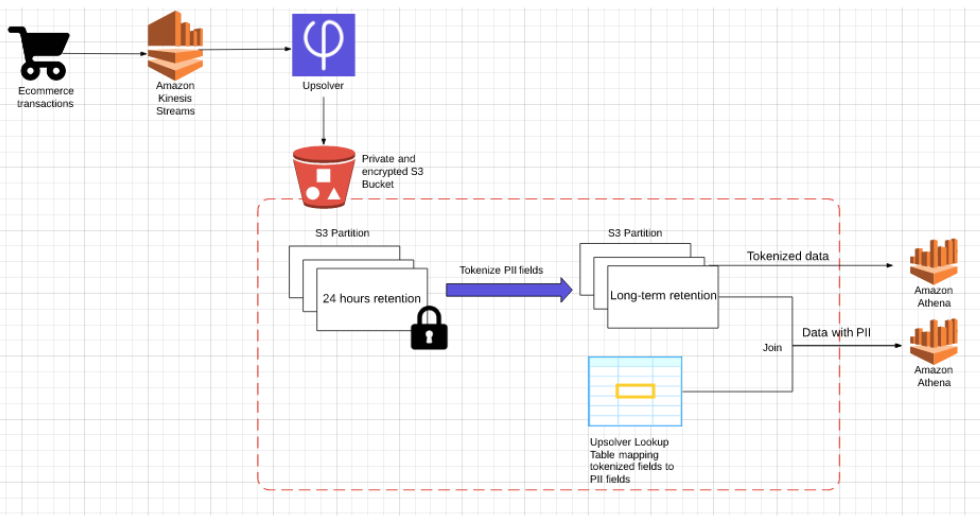
Raw data ingestion
Amazon Kinesis Streams processes the original data – the log of customer transactions that happen on our website. This stream contains sensitive information including PII and financial data.
Upsolver connects to the relevant Kinesis streams as a consumer and ingests the data into a private and encrypted S3 bucket. When configuring the data source in Upsolver, we will set a short retention policy, which means the partition where this data is stored will be deleted every 24 hours.
Tokenization
Using Upsolver’s SQL-based data transformations, we’ll proceed to create a tokenized version of the data by applying an SHA-1 hash function to every field that we want to protect – credit card, customer names and addresses, etc. This will create our anonymized, non-sensitive dataset which analysts can use to explore trends and build reports.
We will then create an Upsolver Athena output, in which all the sensitive fields will be added to the schema as Upsolver Calculated fields with an SHA-256 hash function applied to each. This data is ‘safe’ for analysts to use as all the sensitive information is tokenized. Since the risk associated with this data is much lower, we can set a longer retention policy. This output is partitioned by event time and files are compacted for optimized queries.
Finally, we configure an Upsolver Lookup Table, which allows us to index data by a set of keys and then retrieve the results from S3 in milliseconds. The Lookup Table stores key-value pairs that can be used to retrieve the non-tokenized version of the data. You can learn more about using Lookup Tables as a key-value store here.
Access control
After running our tokenization process, we can create relatively broad permissions for the tokenized datasets. Analytics and data science teams can use Amazon Athena to query this data for their purposes with no risk of data leakage.
In the instances where we do need access to the non-tokenized data, this can be achieved by joining the Lookup Table with the tokenized data by the SHA-256 key. This will create a view in Athena with the sensitive data. Using Upsolver, we can severely restrict access to this view to only a handful of authorized personnel.
Summary and Benefits Achieved
In this article we presented a solution architecture for protecting PII and sensitive data on an Amazon S3 data lake. We built the solution using Upsolver and Amazon Athena in a way that ensures broad access to data for analytics on the one hand, while also ensuring every sensitive field is tokenized and restricted. We also used a short retention period as another safeguard against data leakage by deleting the original sensitive data every 24 hours.
Want to learn more? Check out these related resources:
- Learn about data security in Upsolver
- Get our technical whitepaper
- Read our guide to custom partitioning in Athena
- Try SQLake for free (early access). SQLake is Upsolver’s newest offering. It lets you build and run reliable data pipelines on streaming and batch data via an all-SQL experience. Try it for free. No credit card required.
