
Explore our expert-made templates & start with the right one for you.
Optimizing Your Data Lakehouse for Cost Efficiency
-
 Upsolver Team
Upsolver Team
- Data Lakes
- July 16, 2024
As data engineers, we’re all too aware that data volumes are increasing, sources are numerous and varied, and the importance of timely, accurate data is ever more critical for supporting rapid business decision-making. Our challenges are further complicated by the diverse array of applications and tools accessing the data for reporting, analysis, machine learning, and AI. Data lakes risk not only becoming unmanageable swamps but also financially burdensome ones, potentially hindering rather than enabling business objectives.
Alongside growing data volumes, other forces are driving up costs. In this article, you’ll learn the reasons behind the mounting costs that businesses face, and the solutions for not only lowering costs, but also reducing human resource overhead and creating a well-architected ecosystem that is manageable and easy to scale.
This blog is a recap of the webinar presented by Upsolver’s VP of Product, Roy Hasson.
The Top 3 Drivers of Rising Data Platform Costs
Moving data from on-premise to a cloud architecture comes with expectations of reduced costs and less infrastructure to manage. However, this isn’t always the case and certainly not guaranteed. From our conversations with customers and the wider community about their experiences, we have discovered top three drivers behind the rise in data platform costs that many businesses are currently experiencing.
1. Increasing Volumes of Data
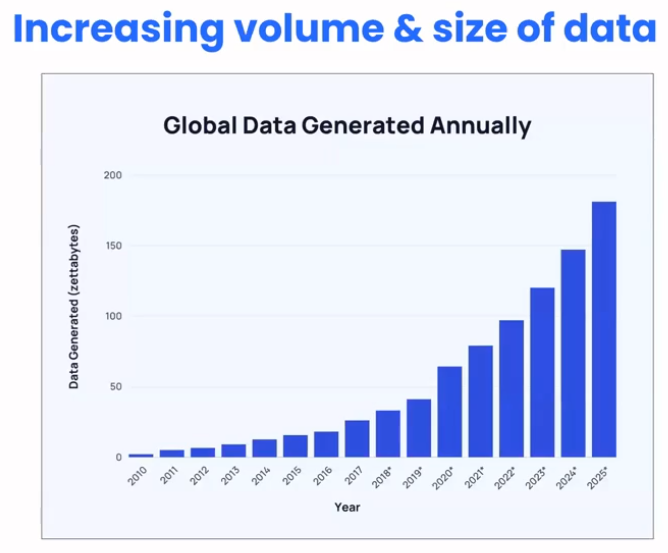
First up, as we have already identified, is the increasing volume and size of data. On a global scale, 53.72% of content is video, and every minute, the following content is generated:
- 231.4 million emails are sent
- 1.7 MM pieces of content are shared on Facebook
- 5.9 million searches on Google
Whilst these are big enough figures to get your head around, into the mix we can also throw the related metadata for the number of views, clicks, and interactions related to each piece. This is valuable data that we want to analyze to help us serve up more content that’s relevant to delivering a personalized experience. Metadata has become essential for LLMs and training models to produce recommendations on social platforms, an essential component for keeping viewers on a platform for as long as possible. And so it’s not just that we’re processing and consuming the content itself, but also the associated metadata that businesses can leverage.
Sourced from Exploding Topics, the chart below depicts the huge increase in data that we need to manage:
2. Competing High-Priority Projects
Data engineering frequently demands juggling multiple projects, each being of the highest priority to the stakeholder. Whether a project arises from within the business or an external customer, it’s not uncommon that when we show them the value of extracting insight from one use case, it leads to more ideas. While we certainly want to encourage this, the knock-on effect can be extra work as, more often than not, it’s not a one-off job to find and process the data, but an on-going project to manage the data.
Different use cases have individual requirements for data freshnesses: some need updating once a day or once a week, others in real-time. The volume of data and the update frequency has a huge impact on how you handle it and therefore what the costs are going to be, especially when the project scales.
3. Data Duplication and Waste
How often do we see different users or departments with versions of the same datasets? Marketing and Sales teams frequently maintain their own version of the same data, while Finance and Operations have metrics reporting the same results using different calculations.
All this contributes to duplication and waste, and additional data increases storage costs. When data is reproduced in multiple locations, it also loses quality and therefore trust, and businesses often find themselves without one version of the truth.
Technical Contributors to the Rapid Increase in Costs
As data warehouses have relocated from on-premise to cloud hosting, we have experienced a shift in the steps for loading our data. Moving from an ETL to ELT model, where we now perform the preparation and processing work in the warehouse rather than a staging database, means we accrue costs across compute and storage systems, through data movement, and also data gravity. Let’s explore each of these areas in more detail.
Compute Systems
When you provision a cloud data warehouse, you choose from the vendor’s t-shirt size style of compute model, where you don’t really get to optimize the compute, but rather must make the best choice you can from a pre-selected range of sizes (think XS to XXL). But if you don’t optimize your workloads, you are prone to spending a lot of money and, as you scale with more data, you need to consider the options of where you spend your money. When it comes to compute, there are generally three types of system:
1 – Self-managed
With a self-managed cloud hosted server such as AWS EC2, you are responsible for loading all the software and patches, and implementing security and HA. The cloud vendor simply gives you the hardware, though you choose the machines and regions. From a cost perspective, most of this is weighted in operations, as it needs a team of people who know the tools and processes to deploy, secure, and patch the system.
This route gives the flexibility of choosing your hardware, such as how many CPUs or memory you want. If your platform team is versed in managing the environment, you can save a lot of money on compute costs. The downside is that you have to manage it on your own.
2 – Fully-managed
This service comprises cloud managed servers and software, for example AWS EMR, and the cloud provider gives you everything you need, including perhaps Hadoop or Spark, and handles the security and patching on your behalf. However, you are responsible for scheduling jobs, scaling, and deployment, and handling monitoring and logging requirements.
While your operational costs are lower than a self-managed server, the hardware cost is typically higher to account for the managed experience.
3 – Serverless
A serverless experience provides fully hosted and managed compute and software, e.g AWS Glue, and AWS Lambda, where you are only responsible for your application and scheduling, and potentially some monitoring operations.
While your human resource costs are lower because there’s less to do, vendor costs are higher because they take on the management work, including scaling and deployment, and HA/DR and security.
The serverless option offers less choice of hardware – again, these are scaled in t-shirt sizes – with very little option to optimize your workloads. Ultimately, you can end up paying more money than expected as you can’t optimize the workload to the compute.
Storage Systems
In a storage system environment, you will typically see the following three scenarios:
1 – Specialized Databases
Specialized databases include traditional OLTP systems such as PostgreSQL or MySQL, though more common these days are niche databases – Pinecone and DuckDB for example – that offer a specific use case other than simple row storage and a basic select query. Niche databases offer specialist storage and retrieval services for handling particular data needs, such as search data.
Much of the cost of a specialized database is consumed in planning how to store the data. As well as being responsible for deploying and scaling the database and providing continuous resilience with HA/DR, you also need to perform data ingestion and modeling. There are decisions to be made on whether it needs sharding or the data requires sorting or hashing, and if you want multiple databases to separate hot and cold data – which increases the cost.
Data will typically be stored on disks, whether SSDs or EBS volumes, where it is network attached, and more expensive than object stores such as Amazon S3.
2 – Column Store
Columnar storage includes data warehouse platforms such as Amazon Redshift, Snowflake, and DuckDB. Modeling, structuring, and organizing the data, performing transformations, and ensuring queries are performant consumes most of the cost. The more you transform and create copies of data, the higher the cost.
Again, these databases typically use disks, but you can use object stores and cache data on disk for an extra cost. Furthermore, you’ll be paying for the management of security, integration, scaling, and compression.
3 – Object Store
Object stores for building data platforms are increasingly popular, with data managed on big cloud providers Amazon AWS, Microsoft Azure, and Google GCS. As with columnar storage, much of the cost is in data modeling and managing the lifecycle of the data. Object stores deliver a serverless-style experience because cost and complexity are abstracted away from you.
Object store has the advantage of enabling you to work with as many tools as you want by reducing the typical vendor lock-in of a data warehouse. This advantage is drawing organizations away from the specialized data stores that offer low latency for high volume data. The majority of use cases don’t need that level of high performance and can therefore benefit from the savings to be made by using object stores.
Data Movement
There are typically three ways in which data is moved, with each incurring different levels of cost:
1 – Intra-cluster
With intra-cluster movement, you have one cluster with multiple nodes and you can shuffle data between the nodes without much of a cost concern.
2 – Inter-cluster
In this scenario, data is transferred between clusters of different types, such as across availability zones. Sometimes data must stay within a zone, such as Europe because of GDPR privacy laws, but you may want to create aggregated views of the data that can be transferred across borders for analysis. Costs start rising in line with increased volumes of data.
3 – Cross cloud
Moving data between systems on different clouds tends to incur a high cloud egress cost, with snapshot copies, event and change streams, and queries all generating traffic. Platforms such as Azure Fabric, Google Omni, and Snowflake have all made data sharing across clouds easy to do, but it comes with a transfer cost.
Data Gravity Centers of Control
The concept of data gravity originated from Dave McCrory, an IT researcher. He proposed that as data accumulates in a single location, it develops a gravitational pull. This “mass” attracts services and applications, as proximity to the data improves latency and throughput.
The process intensifies as more data converges. Eventually, organizations find themselves in a predicament where relocating data and applications to accommodate business workflow requirements becomes challenging or unfeasible. This situation can lead to several adverse effects: escalating costs, diminished workflow efficiency, and potential compliance issues.
The following popular architectures demonstrate where data resides in each system and how the gravitational pull of data impacts the cost:
Data Warehouse
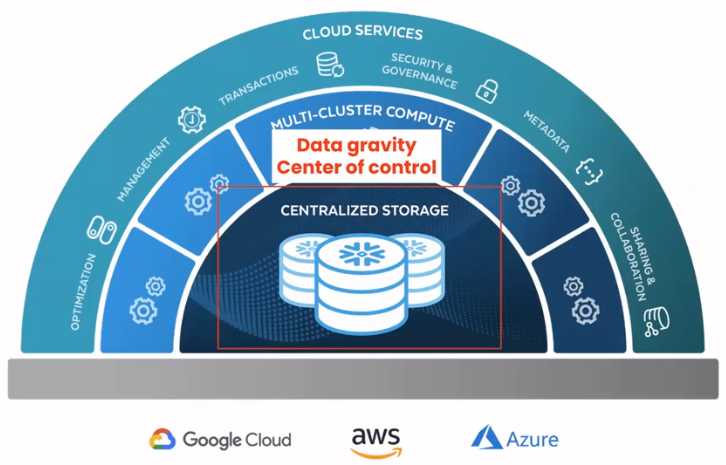
A data warehouse, whether Snowflake, Redshift, or Big Query for example, is a common “mass” that attracts heavy business activity as it is generally considered to hold the master data. Data gravity is controlled by the data warehouse vendor and, while your data may be on AWS, Azure, or Google Cloud, you can’t really access it because the vendor manages. While storage on object stores has a cost advantage, you’ll see compute costs rise if you want to perform transformations.
Fits on Disk
Organizations working with small datasets that don’t run into the petabytes scales, can run analytics on a local machine. In this scenario, you as an individual have control of the data by running DuckDB, Trino, or Spark locally if you have enough computing power.
With DuckDB, you can extend your workload into the cloud and share your data with your team. They can pull the data from the cloud service and work with it locally. This might be ideal for small teams, but if this becomes a continuous pattern, then data movement costs will accrue. Furthermore, you would also need to consider privacy laws when moving data across borders.
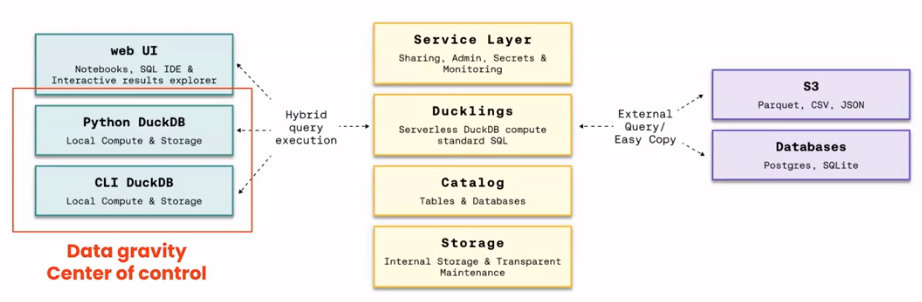
Image Source: https://motherduck.com/docs/architecture-and-capabilities/
Data Lakehouse
In a lakehouse architecture, data gravity is controlled by many, but in a consistent and compliant manner. Open table formats allow us to consolidate table services in a reliable way, regardless of user or tools, or where in the world the data is processed.
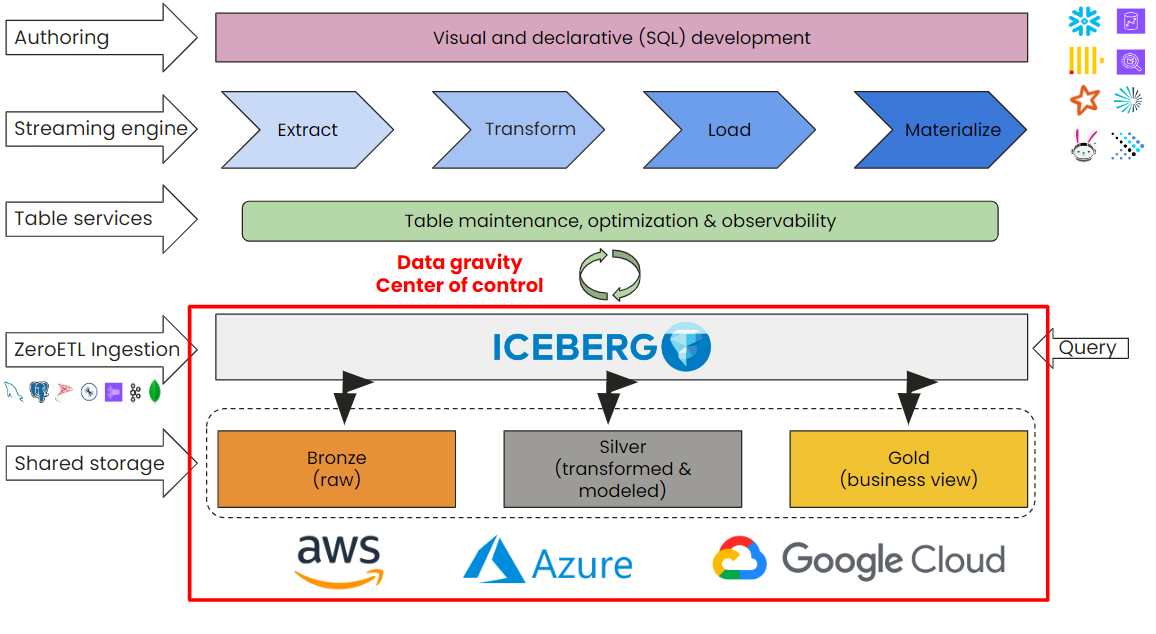
The cost of each architecture is influenced by different factors within each design, as we can see from the chart below:
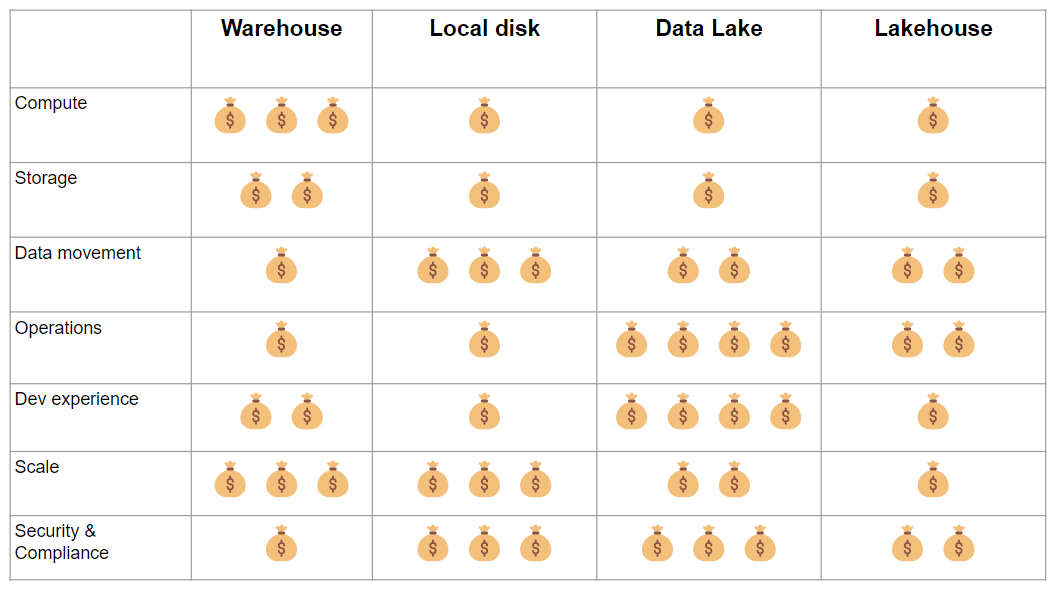
The managed data warehouse is expensive and you have little control over your data. If you’re running a workload on your local disk, this is cheap until you move data or need to scale. With the data lake and lakehouse, again, compute and storage are cheap and you can select the hardware that is appropriate for your use case.
However, the data lake is costly to operate and doesn’t give the best development experience, which is a major driver towards the widespread adoption of the lakehouse. The lakehouse is the next iteration of the data lake and removes much of the complexity and pain associated with managing a data lake.
Open Table Formats on Object Stores
Open table formats include Apache Iceberg, Apache Hudi, Apache Paimon, and Databricks Delta Lake. Each format uses an open standard for creating, updating, and optimizing large analytics tables on object stores. While they can reside anywhere, including your local machine, they are optimized for object stores.
Features in an open table format that take it from data lake to lakehouse include:
- Inserts, updates, and deletes
- ACID transactions
- Schema evolution
- Dynamic partitions
- Pluggable data store format (Parquet, Avro, ORC)
- Storage optimizations
The lakehouse format you choose will come down to preference in ecosystem and performance, otherwise there’s no big feature divide to differentiate them.
The Importance of Shared Storage for Data Interoperability
Shared storage enables data to be accessed by multiple engines. If you have a data warehouse, such as Snowflake, the data might be stored on Amazon S3, it’s locked away in the vendor’s own table format.
Now that Snowflake supports Apache Iceberg and there may be a limitation on who can write and update those tables, the data is stored in an open format. Data that Snowflake writes to Iceberg can now be shared with other vendor platforms such as Salesforce, or Microsoft Fabric, meaning data doesn’t need to be duplicated as different platforms can read from the one source.
Looking at the image below, because all the tools in the stack understand the open table format, they can interoperate and you can be flexible about where and how you manage, transform, and access your data.
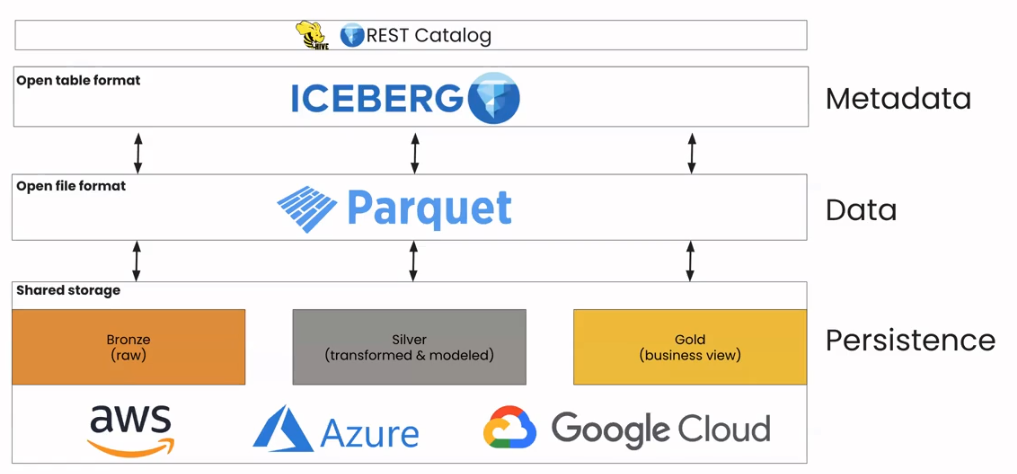
How Do Open Table Formats Save Money?
As well as decreasing data duplication to lower your data platform costs, the following features can be leveraged in a lakehouse to further streamline your outgoings:
- Compaction: lots of small files are combined into larger, optimized files, thereby reducing storage costs
- Sorting: rows in files are organized to improve encoding and compression and accelerate queries
- Compression: different compression algorithms (GZip, Snappy, ZSTD) can be applied to reduce data size
- Cleanup: files no longer referenced by the table can be deleted
- Open: data is openly accessible to multiple tools so it doesn’t require duplication between platforms
- Fast: storage is optimized to reduce compute time and return queries faster
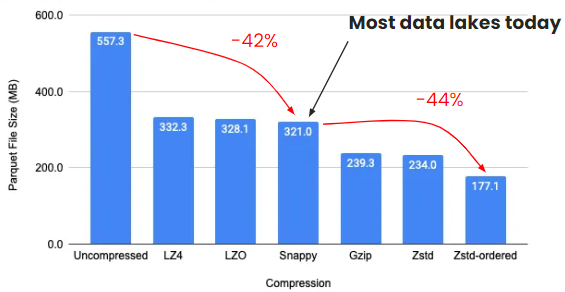
The open format enables you to choose the appropriate compression tool, which you can change as and when required. The following image from Insider Engineering demonstrates the advantages to be gained from compressing date:
Real World Examples of How Data Lakehouses Reduce Costs
At the Apache Iceberg Summit 2024, Crowdstrike and Branch shared their stories of the costs they recouped by moving to a lakehouse architecture, highlighting that the larger the datasets, the more savings there are to be made:
- Crowdstrike made the journey to Iceberg and benefitted from big savings as a result. With a system that handles petabytes of data a day, Crowdstrike transitioned to Iceberg and ran an hourly compaction operation in partitioned data. This resulted in a 30% reduction in the size of the data, which immediately translated into reduced storage costs.Sorted columns are now 50% smaller, so that queries can run faster on that data and save compute costs.
- Branch migrated their Parquet files from the data lake to Iceberg and also discovered major cost savings. The speed increase in query performance reduced compute costs by 40%. Having already had their data compressed in Parquet files, the storage gain came not from any additional compression but from eliminating data duplication, with Iceberg’s open format enabling multiple tools to access one set of data.
Object Stores
There’s no doubt that object stores are the future. Being fast, scalable, and cost-effective means your business can benefit from the following:
- Lower $/Byte Cost effective for large volumes of data
- Ubiquitous Large majority of tools have native read/write support for object stores
- Zero-ops Serverless, secure, auto-scalable, and highly reliable data store
- Scalability Avoid frequent platform redesign as volume & RPS hits current design limits
- Any data Text, audio, images, video, anything goes; experience the same price, performance, and scale
The recent rise of cloud data warehouse platforms, such as Snowflake, drove the trend in ELT, where we would load the data into the warehouse and transform it there. While this works at a technical level, there’s typically a high cost associated.
Now, with Apache Iceberg, there’s less heavy lifting as we can update and optimize the data with an ease that was unavailable on the data lake, making modern ETL efficient, flexible, and cost-effective:
- Compute Choice of instance types, configurations, pricing (on-demand, Spot, self or fully managed) can be matched much more closely to requirements
- Engine Bring the best engine for the job: Spark for batch, Flink for streaming, and Trino for ad-hoc workloads
- Filter Only materialize data you need, and store historical data in low-cost object store
- Reuse Avoid reprocessing the same data for different needs; lower impact on source systems
- Any data Text, audio, images, video, anything goes; not just analytics or AI; Snowflake can’t process videos or images but it can be done in the lakehouse
Summary
Businesses typically think about the size of their data today and fail to predict future growth and costs. Data platform costs increase as the volume of data stored and processed increases, so it is best to consider this during the architectural planning phase. Managed services are easy to use, but could increase your costs as you scale.
Decomposing a vertically integrated solution such as Snowflake provides options to optimize for cost savings within each layer of the stack enabling you to control cost and performance. This was the big selling point of data lakes, but which turned out to be too hard to use and expensive to implement. Today we can do things better by leveraging a data lakehouse, so be sure to choose a solution that allows you to:
- Leverage object stores to retain and access data – if the tool you’re using doesn’t support object store, reconsider replacing it unless it’s absolutely critical
- Choose your own compute (no t-shirt sizing) so you can optimize
- Utilize open table and file formats to reduce storage size and eliminate waste – get stuff out of proprietary format as it loses its value
- Modernize with ETL to filter, prepare, and optimize the incoming firehose of data
- Easily share between users, tools, and clouds in a cost-effective way and avoid duplication: keep one copy of high quality data that can be shared
Build Your Apache Iceberg Lakehouse
With Upsolver, you can build, manage, and optimize an Apache Iceberg lakehouse with ease.
→ Use Upsolver’s Adaptive Optimizer for existing Iceberg tables. Start free
→ Try Upsolver’s Iceberg Live Tables to ingest, prepare and optimize your data in real time. Start free
→ Find out how Upsolver can fit with your specific needs by booking 30 minutes with our solution architect today – no sales, just tech. Chat with our team
Published in:
Blog
,
Data Lakes