
Explore our expert-made templates & start with the right one for you.
Iceberg 101: A Guide to Iceberg Partitioning
-
 Eran Levy
Eran Levy
- Cloud Architecture
- August 14, 2024
One of the most interesting innovations in Apache Iceberg is its approach to partitioning. As organizations grapple with ever-growing datasets, understanding and implementing efficient partitioning strategies becomes crucial for optimizing query performance and storage costs. Learn how it’s done in Iceberg natively, which parts are automated (and which aren’t), and how to ensure you squeeze every last bit of performance from your Iceberg tables.
Need a refresher on Iceberg fundamentals? Start with these articles:
- Iceberg 101: What is the Iceberg table format?
- Iceberg 101: Working with Iceberg tables
- How Apache Iceberg is reshaping the data lake
How Partitioning Works in Iceberg
Iceberg introduces a novel approach to data partitioning that significantly differs from traditional methods used in systems like Hive.
Partitioning in data lakes before Iceberg
In traditional Hive-based data lakes, rows are partitioned or grouped by a specific column into physical folders persisted to an object store. For example, data might be partitioned by year, month, and day, with each partition containing the relevant Parquet files.
The main problem with this approach is its lack of flexibility:
- Changing partition schemes requires restructuring the entire dataset, which can be time-consuming and resource-intensive.
- Adding or removing partition columns often necessitates data rewriting and folder reorganization.
- The partition structure is tightly coupled with the physical storage layout.
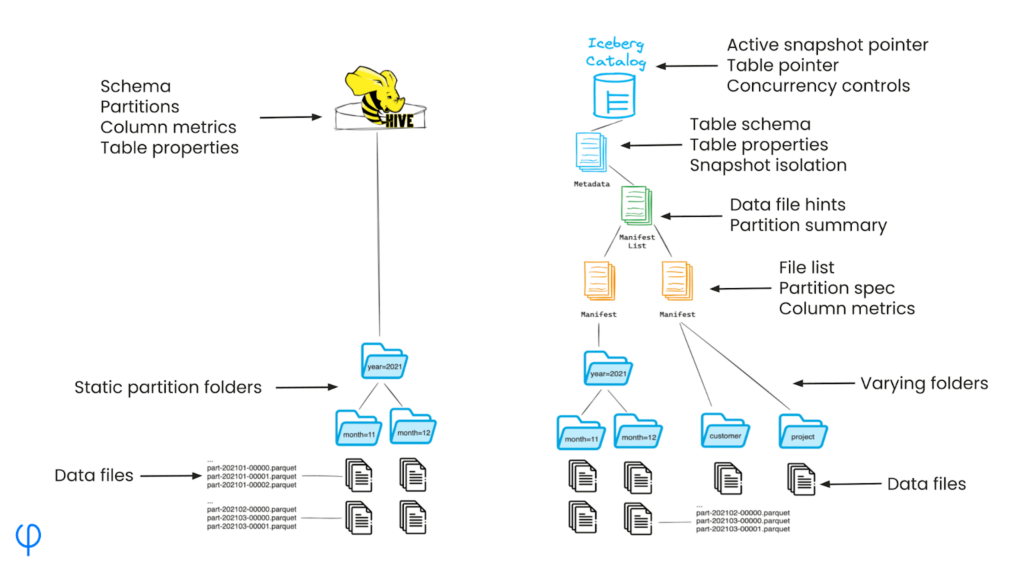
Iceberg’s ‘Hidden’ Partitioning
Unlike Hive, Iceberg doesn’t rely on a physical folder structure to define partitions. Instead, partitioning information is stored in metadata files, decoupling the logical partitioning scheme from the physical data layout.
This means that:
- Partition definitions are metadata-based, not physical folder-based.
- Changing partition schemes doesn’t require data rewriting or restructuring.
- Partitions are “hidden” from the storage layer, providing more flexibility in data organization.
Partition information is managed in Iceberg’s metadata layer, which includes partition specs – versioned definitions of how data should be partitioned – as well as partition data, i.e. Information about existing partitions and their contents.
This approach allows for easy modification of partition schemes like adding or modifying a partition column without affecting the underlying data. It also allows more complex and flexible partitioning strategies to improve query planning as business needs evolve.
Partition specs are stored in Iceberg’s manifest files, which provide a flexible and updateable way to define and manage partitions. When you query an Iceberg table, the system uses these manifest files to quickly determine which data files are relevant to your query based on the partition information.
Benefits of Iceberg Partitioning
1. Flexibility in Partition Evolution
One of the standout benefits of Iceberg partitioning is the ease with which you can change your partition scheme. Unlike traditional systems where modifying partitions is a major undertaking, Iceberg allows you to evolve your partitioning strategy without the headache or cost of data rewrites or restructuring.
Imagine you start with a yearly partition, but as your data grows, you realize you need monthly granularity. With Iceberg, you simply alter the table adding the month column as a partition column and newly inserted rows will be grouped by year and month. This flexibility is a huge time-saver and allows your data organization to evolve with your business needs.
2. Improved Query Performance (Without Manual Optimization)
Iceberg’s metadata-rich approach to partitioning can lead to significant query performance improvements. When you run a query, Iceberg uses its manifest files to quickly identify which data files are relevant, based on your partition specs and partition statistics. This means less time spent scanning irrelevant data and faster query results.
Returning to our time-based example, if you’re querying last month’s data in a table partitioned by date, Iceberg can instantly zoom in on the relevant files without having to scan the entire dataset or even irrelevant files within the month partition. This targeted approach can dramatically speed up your analytics workflows.
3. Efficient Storage Utilization
By decoupling the logical partitioning from the physical storage layout, Iceberg allows for more efficient use of storage. You’re no longer bound by the constraints of folder-based partitioning, which can sometimes lead to many small files or uneven data distribution.
Iceberg’s approach allows for smarter ways to organize your data, potentially reducing your overall storage footprint and the associated costs. Plus, with features like small file compaction, you can maintain optimal file sizes for querying efficiency.
Best Practices for Working with Iceberg Partitions
In a data lakehouse:
- Optimize partition sizes: Finding the right balance in partition granularity is crucial. Too fine-grained partitions can lead to excessive metadata and small files, while overly coarse partitions might not provide enough query selectivity. Consider your typical query patterns and data distribution when defining partition specs.
For time-based data, start with a coarser granularity like month, and only move to finer granularity if your query patterns justify it. Remember, with Iceberg, you can always evolve your partition scheme later without rewriting data.
- Use partition evolution: Take advantage of Iceberg’s ability to evolve partition schemes. If you notice that your initial partitioning strategy isn’t optimal for your evolving query patterns, don’t hesitate to add or modify partition fields. Iceberg will apply the new scheme to new data without requiring a full table rewrite.
- Use partition transforms: Decouple column value from partition value by using Iceberg built-in partition transforms. Want to partition your table by month, but only have an event_time column? Use Iceberg’s month(event_time) transform when partitioning your table and your Iceberg-compatible engine, like Upsolver, will virtually partition the table by month without rewriting the original data. Choose from a number of other useful transforms like bucket and truncate.
In Snowflake
Snowflake has taken a unique approach to implementing Iceberg tables, which is worth understanding if you’re considering using Iceberg within the Snowflake ecosystem:
- Managed vs. unmanaged tables: Snowflake offers both managed and unmanaged Iceberg tables. Managed tables use Snowflake’s catalog and data manipulation processes, providing a more integrated experience but with less flexibility for external access. Unmanaged tables offer more openness but with some limitations on Snowflake’s functionality.
If you need to access your Iceberg data from multiple systems, consider using Snowflake’s unmanaged Iceberg tables, hosted by an external Iceberg-compatible catalog like AWS Glue Data Catalog. This setup gives the benefit of Snowflake’s query performance while maintaining the flexibility to read and write your data through other systems that support Iceberg.
- Clustering: Rather than using Iceberg’s native partitioning, Snowflake applies its own clustering concept to Iceberg tables, similar to how Snowflake’s own native tables are supported. You define a cluster key, and Snowflake optimizes data layout based on this key. This approach leverages Snowflake’s existing optimizations but may result in different performance characteristics compared to native Iceberg partitioning.
Snowflake’s implementation may use more storage compared to some optimized Iceberg setups, but it can offer comparable query performance to Snowflake’s native tables in many scenarios. The exact trade-offs will depend on your specific use case and data patterns.
When working with Iceberg in Snowflake, be aware of these differences and adjust your strategies accordingly. You may need to rely more on Snowflake’s native optimizations and less on Iceberg-specific partition management techniques like partition transforms or partition statistics.
Fuss-Free Partition Optimization with Upsolver
While Iceberg offers many improvements over Hive out of the box, it does not mean that you can simply ‘set it and forget it’. At larger volumes and with more complex and streaming data, you will find that ensuring optimal performance requires more upfront planning and manual tuning.
This is where Upsolver’s Dynamic Partitioning comes in. This feature, combined with several key Iceberg optimizations that Upsolver runs automatically, allows you to keep tables in tune with query needs without lifting a finger.
How it works: Upsolver will monitor table data and identify opportunities to rearrange table layout to accelerate queries by adding or removing physical partitions. If creating a partition is not ideal, Upsolver may choose to cluster the rows until more data is available warranting creating a physical partition.
For example, let’s say your data is partitioned by country. If the majority of your customers are in the United States, Upsolver will create a partition in S3 called “country=us”. For countries with very low volume of data – let’s say you just launched in Europe and are seeing few customers from Malta – Upsolver will store the data for Malta in a file that includes all the relevant rows, clustered and sorted by country. As more data starts to accumulate, Upsolver will create a physical folder, “country=malta”, for Malta and migrate the relevant files into it. This process happens automatically and continuously. You only define which column users often filter a table by, the partition column, and Upsolver does the rest for you.
Published in:
Blog
,
Cloud Architecture
