
Explore our expert-made templates & start with the right one for you.
Iceberg 101: Better Data Lakes with Apache Iceberg
-
 Upsolver Team
Upsolver Team
- Data Lakes
- May 8, 2024
TLDR: Apache Iceberg provides a table abstraction layer for data stored in data lakes – enabling ACID transactions, schema evolution, time travel, and query optimizations. This brings warehouse-like capabilities to data lakes, making them more manageable, performant, and adaptable to various analytics use cases.
The problem with data lakes
The need to store and analyze massive amounts of data has led to the widespread adoption of data lakes. Data lakes offer a cost-effective way to store structured and unstructured data at scale, enabling organizations to break down data silos and gain insights from diverse data sources.
However, as data lakes have grown in size and complexity, they have become increasingly difficult to manage and query efficiently. The lack of transactional consistency, schema enforcement, and performance optimizations has led many data lake implementations to become “data swamps” – disorganized, difficult to navigate, and challenging to extract value from.
Apache Iceberg, an open table format, aims to address these challenges and to make data lakes more performant, manageable, and adaptable to various use cases.
Getting Definitions out of the Way
- A data lake is a centralized repository that allows you to store structured and unstructured data at any scale. It provides a cost-effective way to store raw data in its native format, enabling you to process and analyze it any time. Learn more: What is a data lake?
- Apache Iceberg is an open table format designed for huge analytic tables. It provides a high-performance format for data lake tables that supports schema evolution, ACID transactions, time travel, partition evolution, and more. Iceberg brings a table abstraction layer to data lakes, similar to what you would find in a traditional data warehouse. Learn more about the Iceberg table format
The Role of Iceberg in Modern Data Lakes
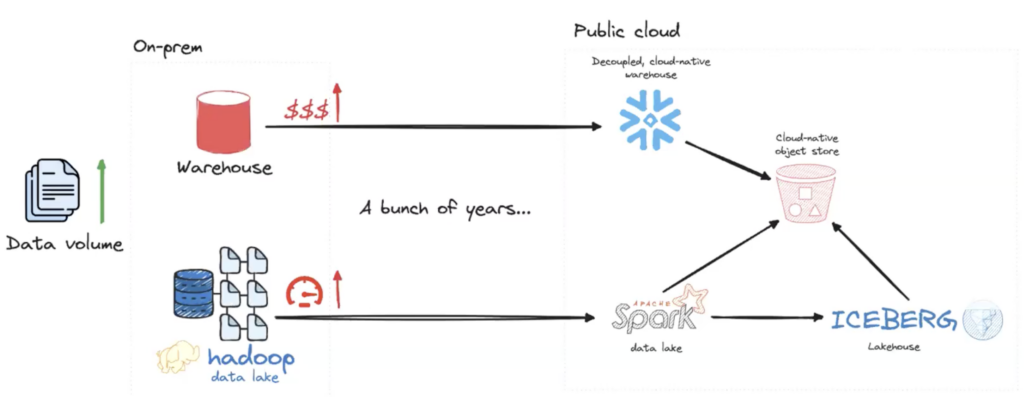
Iceberg plays a crucial role in modern data lake architectures by bringing a set of warehouse-like capabilities to data lakes (this is often referred to as a data lakehouse):
- Iceberg provides a table abstraction layer over data files stored in the lake, which allows users to interact with the data using familiar SQL commands, making it easier to query and manage data in the lake.
- Iceberg also supports ACID transactions, which ensure data consistency and reliability. With ACID transactions, multiple users can concurrently read and write data to the same table without conflicts or data corruption. This is particularly important in data lake environments where data is constantly being updated and accessed by multiple users and applications.
- Iceberg supports schema evolution. As data evolves, Iceberg allows users to easily add, drop, or rename columns in a table without the need to rewrite the entire dataset. This flexibility enables organizations to adapt to changing data requirements and avoid costly data migrations.
- Iceberg also provides powerful optimization features that improve query performance in data lakes. One such optimization is data compaction, which involves merging small data files into larger ones, reducing the number of files that need to be scanned during query execution. Iceberg also supports partition pruning, which allows queries to skip irrelevant partitions, significantly reducing the amount of data that needs to be processed.
- Iceberg enables time travel – i.e., users can query historical versions of a table. This is particularly useful for auditing, debugging, and reproducing results. With time travel, users can easily compare data changes over time and track the lineage of their data.
By bringing these warehouse-like capabilities to data lakes, Iceberg makes them more usable and adaptable – enabling organizations to run complex queries, perform real-time updates, and support diverse workloads, including batch processing, streaming, and machine learning.
Why Companies are Adopting Iceberg as the New Standard for Data Lakes
Companies are increasingly adopting Iceberg for their data lake architectures due to several compelling reasons. One of the primary advantages of Iceberg is its open format, which avoids vendor lock-in. Unlike proprietary data formats, Iceberg is an open-source project that is supported by a growing community of developers and organizations. This means that companies can use Iceberg with a wide range of tools and platforms, giving them the flexibility to choose the best solutions for their needs.
Standardization is another important driver of Iceberg adoption. With growing adoption of Iceberg, companies can rely on a common set of rules and conventions for storing and accessing data, ensuring consistency and reliability across different applications used to query or manage the data.
The data management and query optimization described in the previous section are attractive to companies since they offer a simpler way to operationalize data. With Iceberg, data lake projects can get off the ground faster, and are at smaller risk of becoming a data engineering resource sink.
Finally, Iceberg enables companies to expand their data lake use cases beyond traditional SQL analytics. With Iceberg’s support for real-time updates and streaming data ingestion, companies can build real-time applications and data pipelines that process data as it arrives. Iceberg also integrates well with machine learning frameworks, allowing data scientists to train models directly on data stored in the lake.
Upsolver – The Missing Piece to Go from Data Lake to Operational Data Lakehouse
While Iceberg provides a powerful foundation for building data lakehouses, implementing and managing an Iceberg-based data lake can still be challenging. This is where Upsolver comes in.
Upsolver, the control center for your lake, simplifies the process of building and managing data lakehouses using Iceberg. You can easily ingest data from various sources, including streaming platforms like Kafka and Kinesis, and write it into an S3 data lake in analytics-ready Iceberg tables; there’s also a visual interface for defining data transformations and pipelines. This allows users to build complex data flows without writing code, making it easier for any developer to move data.
Upsolver also connects to existing Iceberg tables, allowing users to analyze the health of tables created by other engines. In addition, Upsolver optimizes these tables to ensure consistent performance and compliance for all tables in the lakehouse. This integration helps companies accelerate adoption of Iceberg-based lakehouses and begin to reap benefits with minimal upfront investment.
>> Get a free trial of Upsolver
>> Learn more about how Iceberg is reshaping data lake file management
Published in:
Blog
,
Data Lakes