
Explore our expert-made templates & start with the right one for you.
MySQL CDC to Iceberg Lake in Minutes
-
 Ajay Chhawacharia
Ajay Chhawacharia
- Change data capture
- April 10, 2024
Need to optimize your Iceberg lakehouse? Check out our free e-learning module: Iceberg Tables Optimization Techniques to learn about effective data ordering, partitioning strategies, file management, and sharing tables. Watch or bookmark here!
Change data capture (CDC) enables you to replicate changes from transactional databases to your Iceberg data lake and other targets like data warehouse. In this tutorial you will learn how to
- Configure your MySQL database to enable CDC
- Build a data pipeline to replicate change events from MySQL to Iceberg datalake as they occur
If you need a refresher on CDC, check out the definition and basics of CDC in our previous article.
Run it!
1. Configure MySQL for CDC replication
2. Use SQLake Wizard to create and deploy the pipeline
Configure MySQL for CDC replication
- Create user with required permissions
Start by creating a user and assigning them the required permissions to manage the CDC process. Substitute the username and password for your own.
CREATE USER 'cdcuser'@'%' IDENTIFIED BY 'password'; GRANT SELECT, RELOAD, SHOW DATABASES, REPLICATION SLAVE, REPLICATION CLIENT ON *.* TO 'cdcuser' IDENTIFIED BY 'password'; FLUSH PRIVILEGES;
If you are using Amazon RDS or Amazon Aurora for MySQL, they don’t allow a global read lock. You will need to configure a table-level lock to create a consistent snapshot. In this case, you need to also grant LOCK TABLES permission to the CDC user.
GRANT LOCK TABLES ON *.* TO 'cdcuser' IDENTIFIED BY 'password';
- Enable logical replication
MySQL uses a binlog to track changes to databases and tables. SQLake uses this binlog to replicate changes to your data lake and data warehouse. To enable the binlog, you need to update your MySQL server configuration file by including the following properties:
- binlog_format = ROW
- binlog_row_image = FULL
Or execute the following statement:
SET GLOBAL binlog_format = 'ROW'; SET GLOBAL binlog_row_image = 'FULL';
To check if the binlog is correctly configured, run the following query against you database:
show global variables where variable_name in ('binlog_format', 'binlog_row_image');
For Amazon RDS, you need to configure these properties in the parameter group of your database. Once set, you will need to restart the database for it to take effect. If your RDS database is using the default param group, you cannot modify it. In that case, create a new parameter group for your database version. This inherits all the default params from the default group automatically. And then modify these two properties.
After you make the changes, make sure the parameter group is set and the database is updated.
show global variables where variable_name in ('binlog_format', 'binlog_row_image');
For more detailed information about configure MySQL CDC replication, follow the instructions in the Debezium documentation.
Lets Begin!
- Launch SQLake and click on “New Job” in the “Job” menu page

- Select your Source as MySQL and Target as AWS Glue Data Catalog (Upsolver will catalog your parquet Iceberg files in Glue)
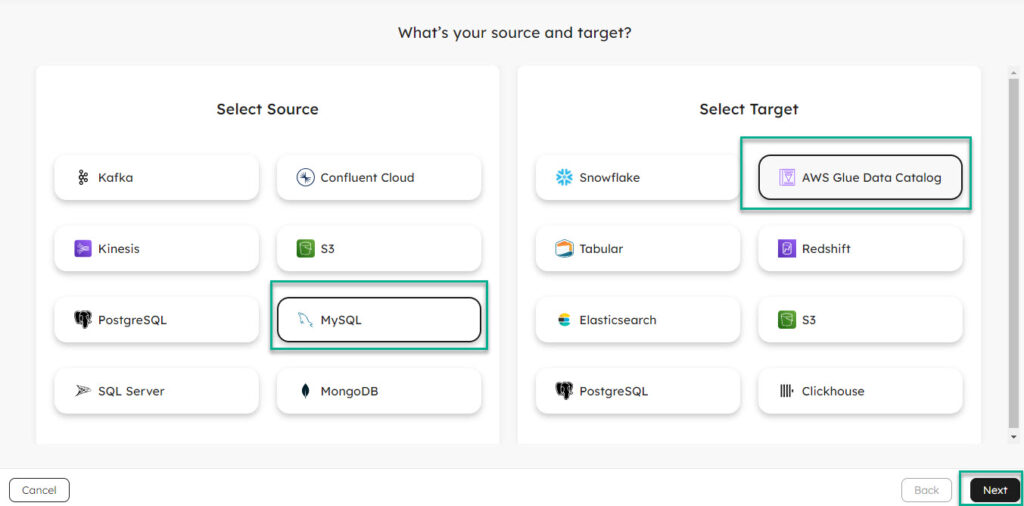
- Configure the MySQL connection & Test the connection (if connection was configured before, existing connections will automatically appear in a dropdown)
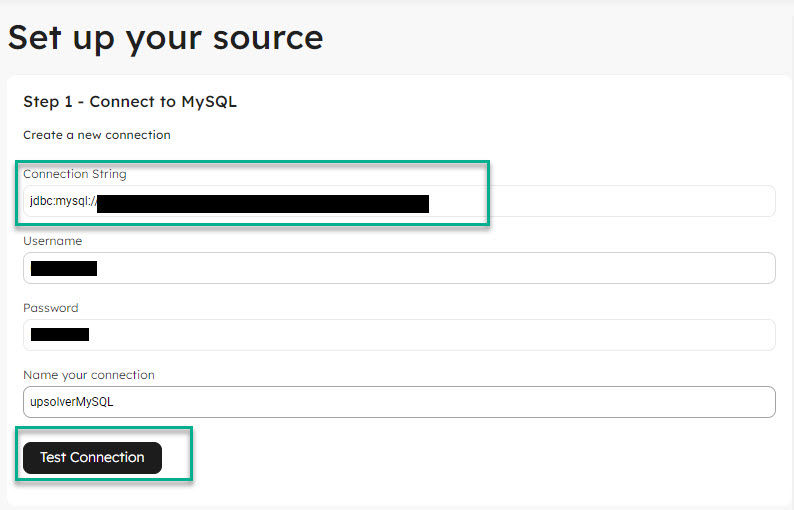
- Upsolver by default selects all the databases, tables and columns in each table for replication. Make your desired selections as applicable for the pipeline.
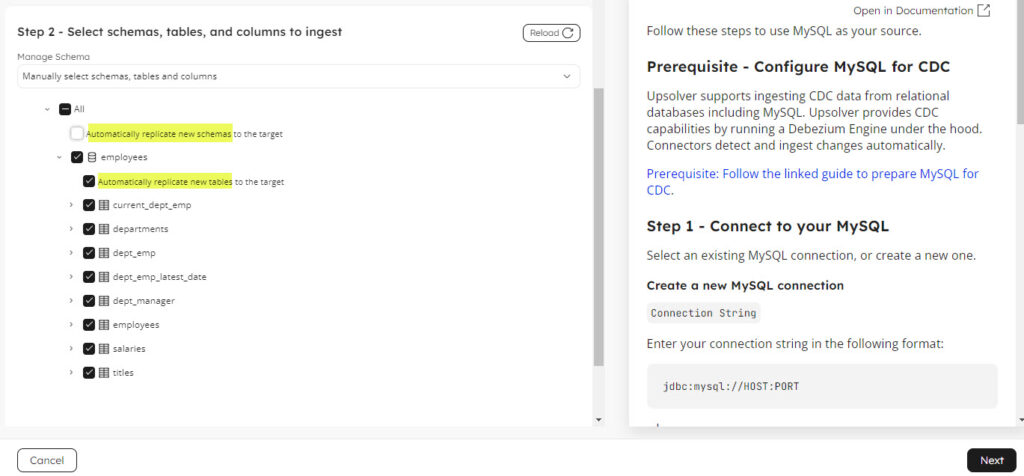
- Configure target which in this case is a Glue catalog, table format by default is Iceberg and target database. Optionally select prefix for the replicated tables if desired.
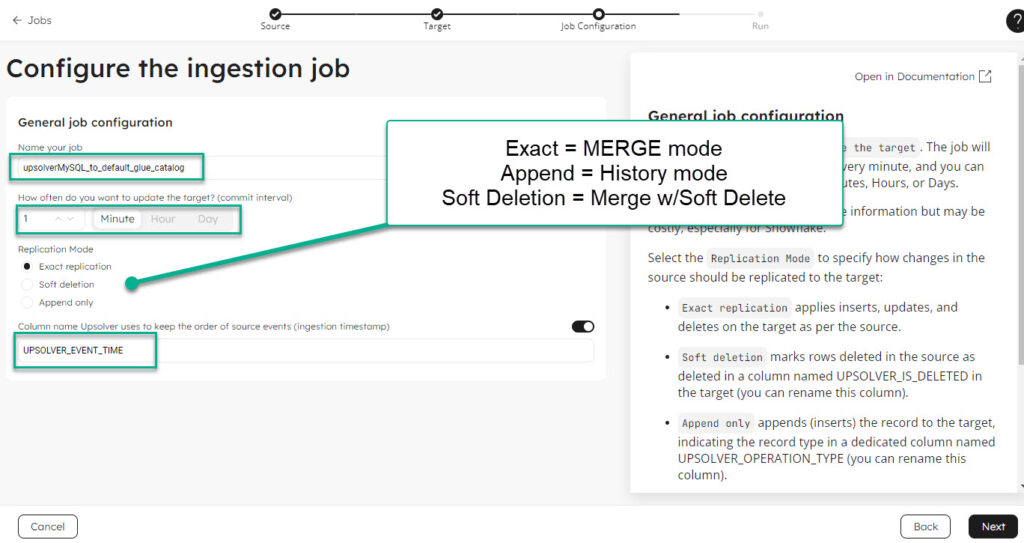
- Configure the replication job. By default Upsolver gives a unique name to the job, configures to commit to the target every minute, chooses MERGE as replication mode and adds a system column $eventtime which captures when Upsolver processed that record. Configure the commit interval to target and replication mode per business need.
- Replication mode
- APPEND: target table maintains history of each Insert/Update/Delete operation
- MERGE mode: target table reflects the latest state in source MySQL table with hard deletes
- Soft deletion: MERGE with soft delete
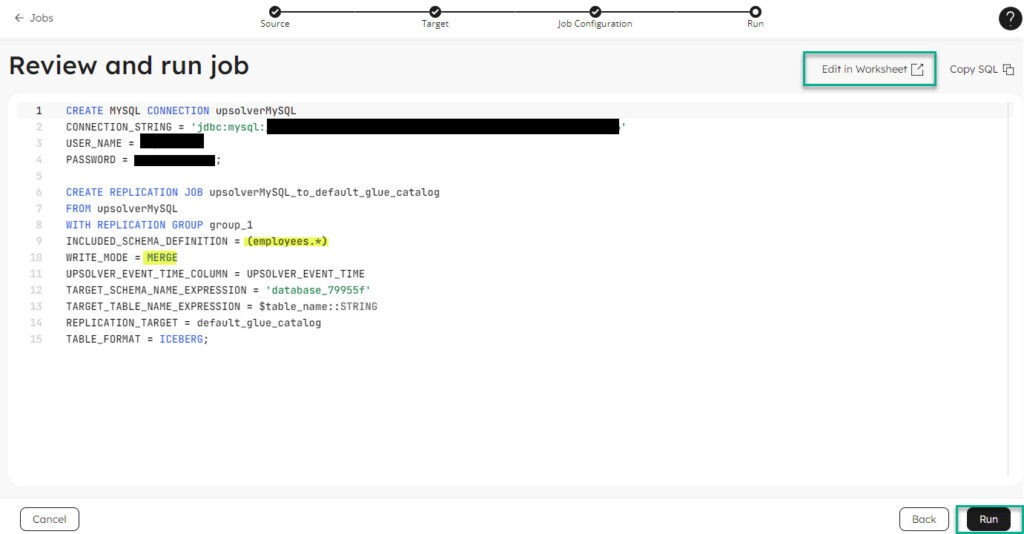
- Upsolver auto generated the code for the cdc pipeline. Run it or Edit in worksheet to save a copy of this code snippet.
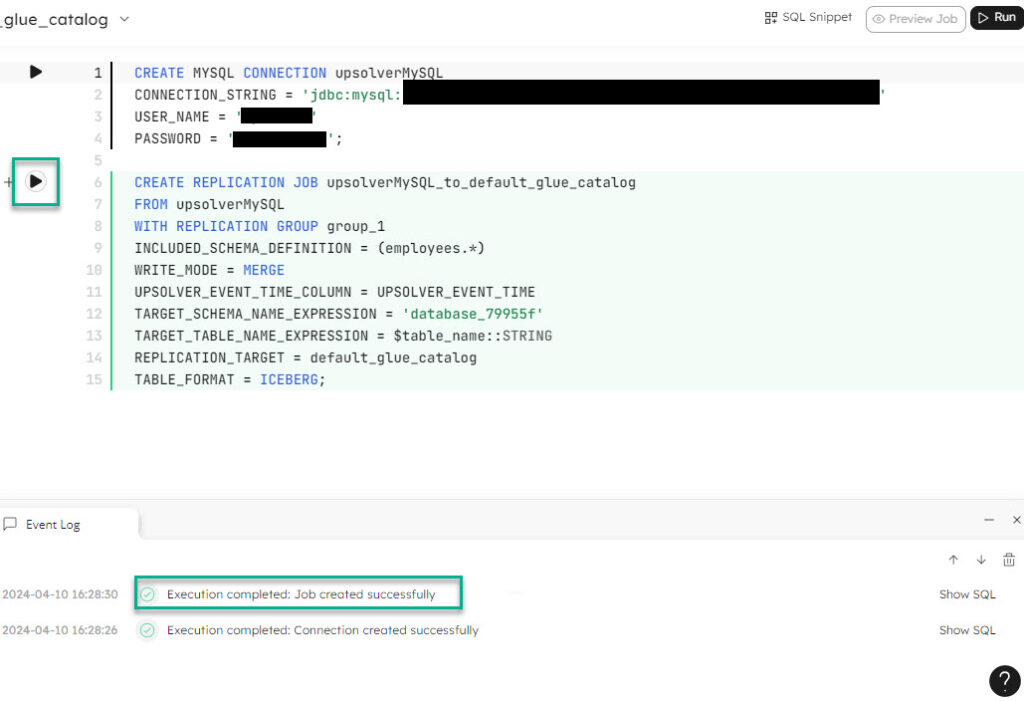
- This is the worksheet mode. Run using the play button. Save in your code repository to deploy in production environments.
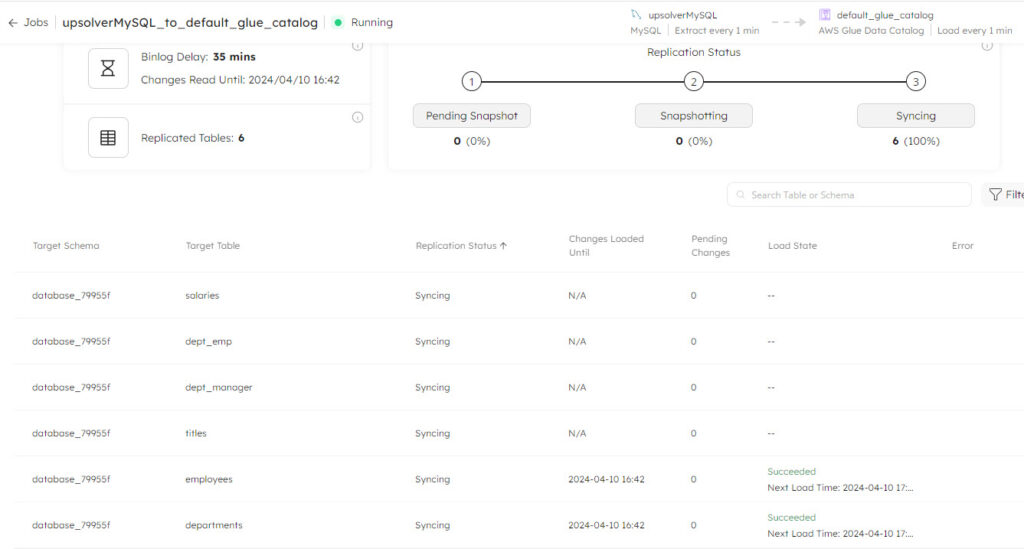
Once the job starts to run, SQLake will take a snapshot of each of the tables you selected to replicate. After SQLake has finished copying the historical data using a snapshot it will start streaming CDC events. You can monitor the status of the snapshot and streaming process using the job properties window

Summary
SQLake provides a simple to use CDC capability that allows you to easily replicate tables from your operational MySQL database to the Iceberg data lake and/or data warehouse. SQLake automatically creates an append-only wide table in the data lake to hold the full history of your source tables. It continuously appends changed events captured from the source. This makes it easy and economical to store raw data for ML model training and reprocessing to fix quality and corruptions in the data without going back to the source. You create jobs that merge the change events from the staging table into output tables that are kept in sync with the source. Furthermore, you can model, prepare and enrich tables before loading the final results to your final target tables in the data lake or warehouse for analysis and BI.
Published in:
Blog
,
Change data capture
