
Explore our expert-made templates & start with the right one for you.
4 Guiding Principles for Modern Data Lake Architecture
-
 Shawn Gordon
Shawn Gordon
- Data Lakes
- March 18, 2020
Data lakes are the cornerstones of modern big data architecture, but getting them right can be tricky. How do you design a data lake that will serve the business, rather than weigh down your IT department with technical debt and constant data pipeline rejiggering? In this document we cover the four essential principles for effectively architecting your data lake.
Want to build a high-performance data lake in days instead of months, with your existing IT resources and without sacrificing performance? Upsolver has you covered. Check out our data lake ETL platform to learn how you can instantly optimize your big data architecture.
Modern Data Lake Architecture Guiding Principles
1. Use event sourcing to ensure data traceability and consistency
When working with traditional databases, the database state is maintained and managed in the database while the transformation code is maintained and managed separately. This can pose challenges when trying to ensure the consistency and traceability of data throughout the development lifecycle.
To understand why this matters, think of a typical development process: You have data transformation code running and constantly changing, which causes your database to be updated over time. One day you need to restore the entire system to a previous revision to recover from error or test new code.
The transformation code, which is probably backed up in some version control system like Git, can be easily restored; whereas your database state has already changed since the time that transformation was running and it will be difficult to restore it to the exact required state without having a backup of the database for each version of your transformation code.
In a data lake architecture where compute and storage are separated, you can and should use event sourcing.
In an event sourcing architecture, the approach is “store now, analyze later”. The first step is to maintain an immutable log of all incoming events on object storage, like Amazon S3. When analytics use cases present themselves, users can create ETL jobs to stream the data from the immutable log to a data consumption platform. This approach enables to reduce the costs of expensive databases, enable data teams to validate their hypotheses retroactively and enable operations teams to trace issues with processed data and fix them quickly by replaying from the immutable log.
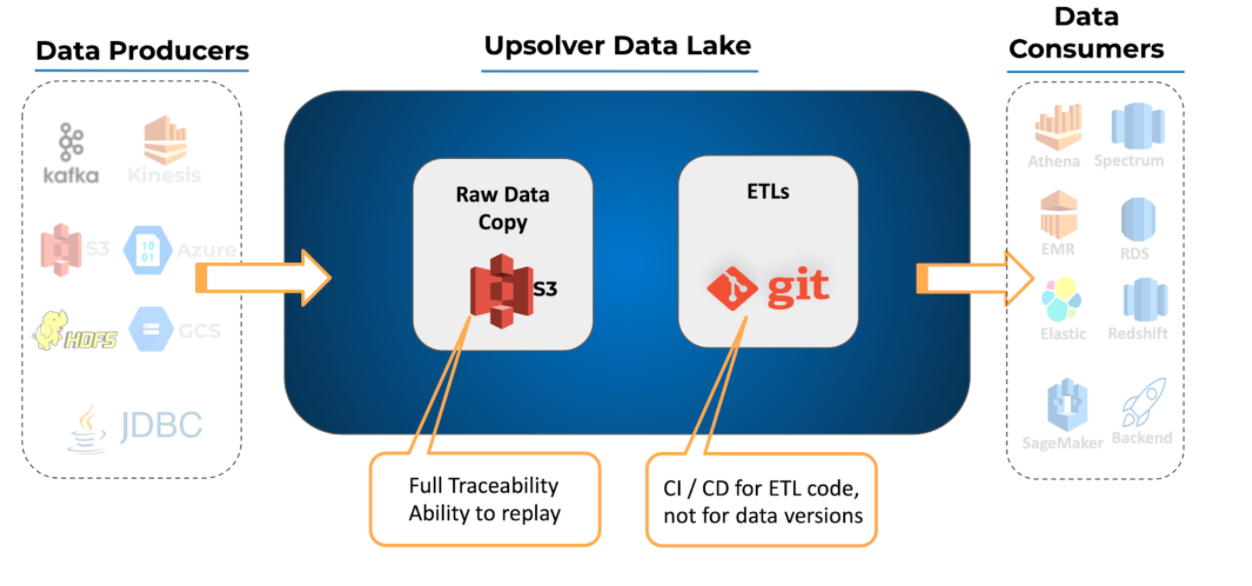
Unlike with databases where the previous state isn’t easily accessible (only backups), – event sourcing enables you to ‘go back in time’ and retrace your steps to learn about the exact transformation applied on your raw data, down to the event level. If there was an issue in your ETL code, you can easily fix it and run the new code on the immutable original data.
2. Layer your data lake according to your user’s skills
A data lake is meant to serve many different users across the organization: from researchers analyzing network data, through data scientists running predictive algorithms on massive datasets, to business analysts looking to build dashboards and track business performance.
An efficient data pipeline will ensure that each of these consumers gets access to the data using the tools they already know, and without relying on manual work by data providers (DevOps, data engineering) for every new request. Data scientists might want access to almost all fields within the raw data to serve as ‘fodder’ for neural networks, while business intelligence teams might prefer a much thinner and more structured version to ensure reports are performant and cost-effective.
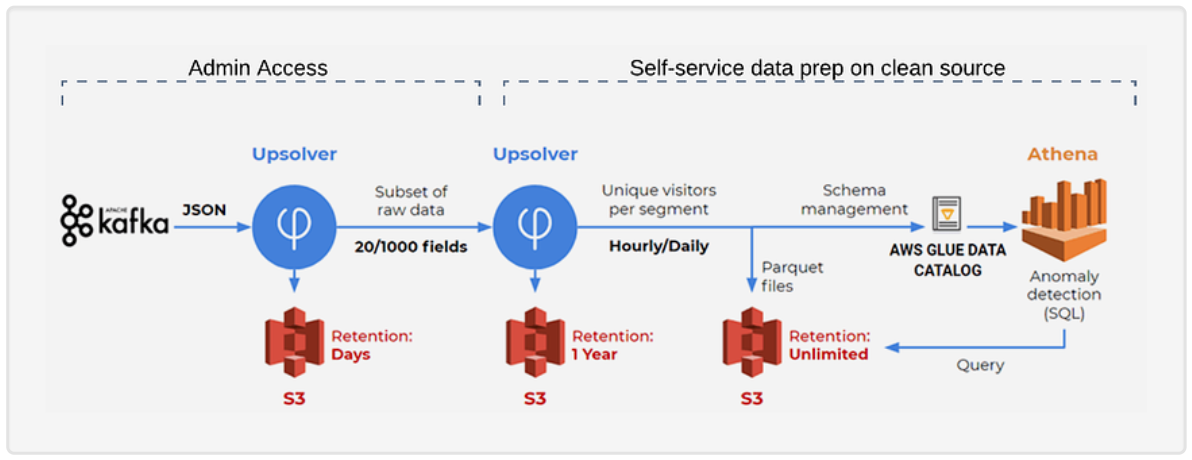
When we organize our data lake, we have the possibility to store multiple copies of the data for different use cases and consumers. By automating the ETL pipelines that ingest the raw data and perform the relevant transformations per use case we can prevent the data engineering bottleneck that might form if we rely on coding-based ETL frameworks such as Apache Spark.
An example of this can be found in this case study on AWS: SimilarWeb layer and clean raw event data within their data lake, in order to eventually create a dataset that analysts can query using SQL in Amazon Athena. Each layer contains a subset of the data and has its own retention policy: AAA
3. Keep your architecture open
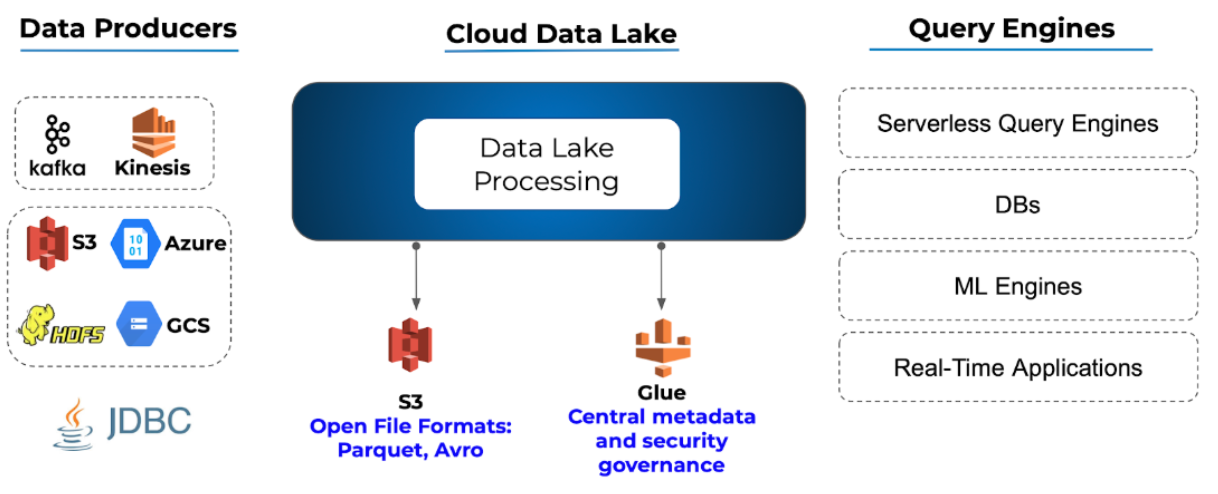
Keeping data accessible means avoiding vendor lock-in, or overreliance on a single tool or database (and the gatekeepers that come with it). The idea behind a data lake is to have all your organizational data in one place while also enabling ubiquitous access to the data with a wide variety of tools, and by a broad range of services.
To create an open architecture, you should:
- Store your data in open formats like Avro and Parquet which are standard, well-known and accessible by different tools (rather than proprietary file formats built for a specific database such as Delta Lake).
- Retain historical data in object storage like Amazon S3. This will allow you to cut costs compared to storing your data in a database/data warehouse. Moreover, storing your data in an object store will enable you to always have your data available for you no matter the platform you use to manage your data lake and run your ETLs.
- Use a central meta-data repository such as AWS Glue or Hive. This will allow you to centralize and manage all your meta-data in a single location, reducing operational costs in infrastructure, IT resources and engineering hours. Here too you would be best advised to use open-source based storage to avoid vendor lock-in.
4. Plan for performance
Storing data is all well and nice, but eventually you’ll want to actually put the data to use. For analytics purposes this would generally mean running some SQL query against the data to answer a business question. In an AWS data lake, the tool of choice would be Amazon Athena, which can retrieve data directly from lake storage on Amazon S3; for other purposes you might want to use databases such as Redshift or Elasticsearch on top of your lake.
To ensure high performance when querying data, you need to apply storage best practices to make data widely available. We’ve covered these in previous articles that we will link in the bottom of this related article, but here are a few key ones to keep in mind:
- You want every file stored to contain the metadata needed in order to understand the data structure. Your data lake is being queried by various query engines such as Amazon Athena and Apache Presto. These engines require a schema for querying.
- Use columnar file formats such as Apache Parquet and ORC. Storing your data in columnar format enables you to create metadata for your data, which in turn allows you to understand the structure of your data when querying it. With columnars formats, you can query only the columns you need and avoid scanning redundant data.
- Keep your data in optimal file sizes (compaction). We recommend implementing a Hot/Cold architecture: Hot – small files for good freshness; cold – merging small files into bigger files for better performance.
- Build an efficient partitioning strategy to ensure queries run optimally by only retrieving the relevant data needed in order to answer a specific analytical question – read our guide to data partitioning to learn more.
Further Reading: Improving Data Lake Performance
Next Steps
- Want to unlock the true value of your data lake? Schedule a demo of Upsolver to see how you can prepare petabyte-scale streaming data for analysis with a simple visual interface and SQL.
- Try SQLake for free (early access). SQLake is Upsolver’s newest offering. It lets you build and run reliable data pipelines on streaming and batch data via an all-SQL experience. Try it for free. No credit card required.
Published in:
Blog
,
Data Lakes