
Explore our expert-made templates & start with the right one for you.
Cut Data Warehouse Costs in Half with Apache Iceberg
-
Rachel Horder
- Cloud Architecture
- May 8, 2024
Dremio, the unified self-service analytics platform, conducted a survey among 500 data leaders and practitioners from major enterprises to assess their understanding and adoption of data lakehouses. The findings were published in the State of the Data Lakehouse 2024 Survey, and we had the privilege of hosting Dremio’s Developer Advocate, Alex Merced, who presented the results at our recent Chill Data Summit in New York City.
For those who may have missed it, below are the notable highlights from the survey, particularly focusing on the anticipated data warehouse cost reductions for businesses transitioning to a lakehouse architecture within the next three years.
Awareness and Adoption of Lakehouses
A data lakehouse amalgamates the advantages of a data warehouse with the scalability and flexibility of a data lake. Given the lack of transactional consistency in data lakes and the scalability challenges of data warehouses, the lakehouse represents a hybrid solution addressing the constraints of each architecture.
For an in-depth exploration of the differences between data lakes and lakehouses, including architecture, limitations, and capabilities, please refer to Lakehouse vs. Data Lake: The Ultimate Guide.
The survey begins by examining respondents’ awareness of data lakehouses, revealing that 85% were “very familiar” with the concept.
The term “data lakehouse” has become notably more prevalent than it was a couple of years ago, correlating with an uptake in adoption. When asked about the percentage of analytics anticipated to operate within a data lakehouse in the next three years, two thirds of respondents indicated this to be more than 50%.
While the preceding decade witnessed a push to migrate data into cloud data warehouses, promising previously unattainable scalability and flexibility for on-premises implementations, the associated high costs have outweighed the benefits for many organizations.
Respondents believe that embracing a lakehouse architecture will result in, or has already led to, cost savings exceeding 50% over their current data warehouse. Moreover, nearly a third of respondents from organizations with over 10,000 employees anticipate savings surpassing 75%. These savings stem from reduced data replication, egress, and compute costs.
A deeper analysis of the data sources migrated to the lakehouse reveals that 42% originate from cloud data warehouses, 35% from enterprise data warehouses, and 22% from the data lake.
Open Table Formats
When it comes to Apache Iceberg, the future looks promising. A comparison between current adoption of open table formats and projected adoption within the next three years indicates Iceberg’s dominance of the open table space. We can see that Iceberg is leading the way and is predicted to overtake Delta lake.

The Prominence of Apache Iceberg
Iceberg’s expansive developer community – including notable brands such as Apple, Netflix, LinkedIn, and Amazon Web Services (AWS) – is propelling its adoption. In contrast, Delta Lake is primarily driven by Databricks.
Numerous companies, including Upsolver, are either constructing or supporting Iceberg in their products, thereby fostering uptake and broadening opportunities for customers to reap its benefits. With backing from these tech giants, Apache Iceberg emerges as the preferred choice.
The Rise of Data Mesh
Data mesh complements data lakehouse technology. A key advantage of the open table format facilitated by the lakehouse is that disparate tools can operate on the same data. Consequently, this enables the segmentation of data into sets, so various teams within an organization can develop and deliver data products, thereby expediting scalability.
Upon questioning, 84% of respondents confirmed having fully or partially implemented a data mesh, with 97% expecting its expansion in the coming year.
Just as with existing relational databases or data warehouses necessitating ongoing maintenance and performance tuning, the same holds true for Apache Iceberg. Further insights on how Upsolver automates these tasks are detailed below.
Upsolver Embraces Apache Iceberg
Upsolver is fully dedicated to supporting Iceberg lakehouses through three core solutions aimed at ensuring customers experience efficient queries and reduced costs.
Our solutions are designed for ease of use with minimal learning curves, handling the heavy lifting and ongoing maintenance, allowing you to focus on critical business activities.
Ingestion to Apache Iceberg Tables
When you ingest data to Iceberg with Upsolver, we automatically manage your tables by executing background compaction processes based on industry best practices. These operations run at optimal times to deliver optimal results, reducing the size of your tables and file count, thereby saving on storage costs and enhancing data scan speeds.
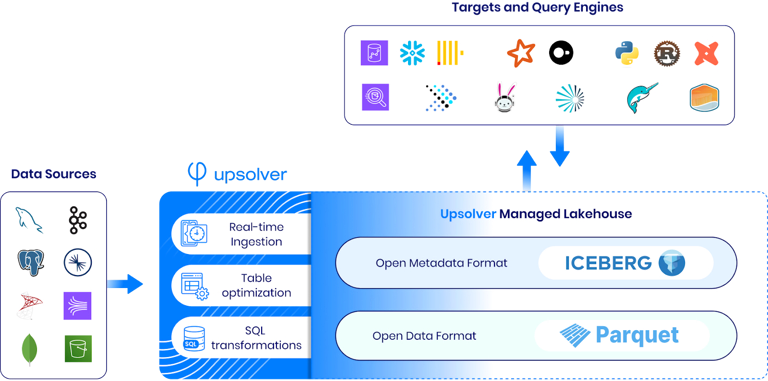
Iceberg Table Optimization Tool
For existing tables in Iceberg not managed by us, our standalone optimization tool enables analysis to identify areas requiring compaction and tuning. By connecting to your AWS Glue Data Catalog or Tabular catalog, you can initiate optimization within minutes.
Simply designate the tables for Upsolver to manage, and we continuously compact files to minimize table size, decreasing storage costs and improving data scan performance.
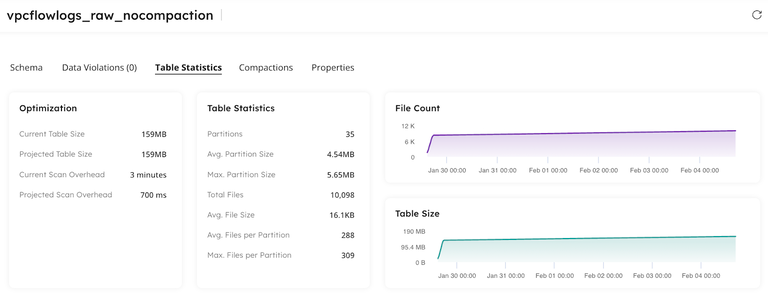
Free Iceberg Table Analyzer CLI
Our open-source analyzer swiftly identifies tables in your lakehouse requiring compaction. Installation is straightforward, and running it against your existing lakehouse reveals tables in need of tuning. The analyzer generates a report illustrating potential savings for each table.
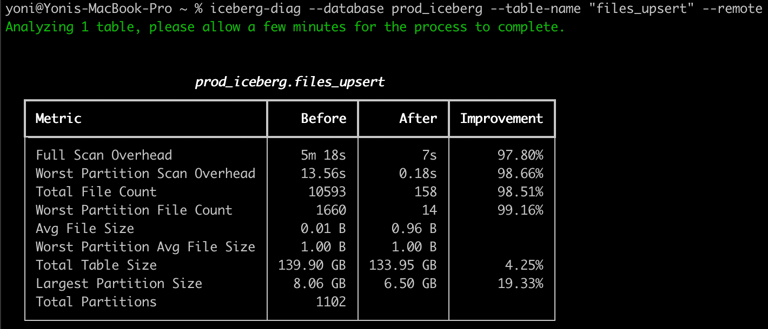
From this survey, it is evident that open table formats and Apache Iceberg are witnessing adoption as organizations recognize the user-friendliness, performance, and cost-saving advantages of open data. Iceberg, tailored for high-scale analytics, holds the potential to substantially reduce costs by migrating data from existing warehouses without compromising performance.
Next Steps
- Watch Alex’s presentation, Reflecting on the State of the Data Lakehouse Survey, recorded live at the Chill Data Summit in NYC.
- Check out our documentation which will have you up and running with the above tools – and your Iceberg tables compacted and optimized – in no time at all!
- Alternatively, schedule an obligation-free demo to see Upsolver in action.
Published in:
Blog
,
Cloud Architecture