
Explore our expert-made templates & start with the right one for you.
Apache Airflow – When to Use it, When to Avoid it
-
 Jerry Franklin
Jerry Franklin
- Data Lakes
- October 28, 2021
This article below is part of our detailed technical report titled “Orchestrating Data Pipeline Workflows With and Without Apache Airflow.” In it, we conduct a comprehensive analysis of Airflow’s capabilities compared to alternative solutions. The full technical report is available for download at this link.
Apache Airflow is a powerful and widely-used open-source workflow management system (WMS) designed to programmatically author, schedule, orchestrate, and monitor data pipelines and workflows. Airflow enables you to manage your data pipelines by authoring workflows as Directed Acyclic Graphs (DAGs) of tasks. There’s no concept of data input or output – just flow. You manage task scheduling as code, and can visualize your data pipelines’ dependencies, progress, logs, code, trigger tasks, and success status.
Glossary terms mentioned in this post
- Apache Kafka – an open-source streaming platform and message queue
- ETL pipeline – the process of moving and transforming data
- Apache Airflow – an open-source workflow management system
Airflow was developed by Airbnb to author, schedule, and monitor the company’s complex workflows. Airbnb open-sourced Airflow early on, and it became a Top-Level Apache Software Foundation project in early 2019.
Written in Python, Airflow is increasingly popular, especially among developers, due to its focus on configuration as code. Airflow’s proponents consider it to be distributed, scalable, flexible, and well-suited to handle the orchestration of complex business logic. According to marketing intelligence firm HG Insights, as of the end of 2021 Airflow was used by almost 10,000 organizations, including Applied Materials, the Walt Disney Company, and Zoom. (And Airbnb, of course.) Amazon offers AWS Managed Workflows on Apache Airflow (MWAA) as a commercial managed service. Astronomer.io and Google also offer managed Airflow services.
Apache Airflow: Orchestration via DAGs
Airflow enables you to:
- orchestrate data pipelines over object stores and data warehouses
- run workflows that are not data-related
- create and manage scripted data pipelines as code (Python)
Airflow organizes your workflows into DAGs composed of tasks. A scheduler executes tasks on a set of workers according to any dependencies you specify – for example, to wait for a Spark job to complete and then forward the output to a target. You add tasks or dependencies programmatically, with simple parallelization that’s enabled automatically by the executor.
The Airflow UI enables you to visualize pipelines running in production; monitor progress; and troubleshoot issues when needed. Airflow’s visual DAGs also provide data lineage, which facilitates debugging of data flows and aids in auditing and data governance. And you have several options for deployment, including self-service/open source or as a managed service.
Popular Airflow Use Cases:
- Orchestrating batch ETL jobs
- Automatically organizing, executing, and monitoring data flow
- Handling data pipelines that change slowly (days or weeks – not hours or minutes), are related to a specific time interval, or are pre-scheduled
- Building ETL pipelines that extract batch data from multiple sources, and run Spark jobs or other data transformations
- Machine learning model training, such as triggering a SageMaker job
- Automated generation of reports
- Backups and other DevOps tasks, such as submitting a Spark job and storing the resulting data on a Hadoop cluster
As with most applications, Airflow is not a panacea, and is not appropriate for every use case. There are also certain technical considerations even for ideal use cases.
Prior to the emergence of Airflow, common workflow or job schedulers managed Hadoop jobs and generally required multiple configuration files and file system trees to create DAGs (examples include Azkaban and Apache Oozie).
But in Airflow it could take just one Python file to create a DAG. And because Airflow can connect to a variety of data sources – APIs, databases, data warehouses, and so on – it provides greater architectural flexibility.
Reasons Managing Workflows with Airflow can be Painful
First and foremost, Airflow orchestrates batch workflows. It is not a streaming data solution. The scheduling process is fundamentally different:
- batch jobs (and Airflow) rely on time-based scheduling
- streaming pipelines use event-based scheduling
Airflow doesn’t manage event-based jobs. It operates strictly in the context of batch processes: a series of finite tasks with clearly-defined start and end tasks, to run at certain intervals or trigger-based sensors. Batch jobs are finite. You create the pipeline and run the job. But streaming jobs are (potentially) infinite, endless; you create your pipelines and then they run constantly, reading events as they emanate from the source. It’s impractical to spin up an Airflow pipeline at set intervals, indefinitely.
Pipeline versioning is another consideration. Storing metadata changes about workflows helps analyze what has changed over time. But Airflow does not offer versioning for pipelines, making it challenging to track the version history of your workflows, diagnose issues that occur due to changes, and roll back pipelines.
Also, while Airflow’s scripted “pipeline as code” is quite powerful, it does require experienced Python developers to get the most out of it. Python expertise is needed to:
- create the jobs in the DAG
- stitch the jobs together in sequence
- program other necessary data pipeline activities to ensure production-ready performance
- debug and troubleshoot
As a result, Airflow is out of reach for non-developers, such as SQL-savvy analysts; they lack the technical knowledge to access and manipulate the raw data. This is true even for managed Airflow services such as AWS Managed Workflows on Apache Airflow or Astronomer.
Also, when you script a pipeline in Airflow you’re basically hand-coding what’s called in the database world an Optimizer. Databases include Optimizers as a key part of their value. Big data systems don’t have Optimizers; you must build them yourself, which is why Airflow exists.
But despite Airflow’s UI and developer-friendly environment, Airflow DAGs are brittle. Big data pipelines are complex. There are many dependencies, many steps in the process, each step is disconnected from the other steps, and there are different types of data you can feed into that pipeline. A change somewhere can break your Optimizer code. And when something breaks it can be burdensome to isolate and repair. For example, imagine being new to the DevOps team, when you’re asked to isolate and repair a broken pipeline somewhere in this workflow:
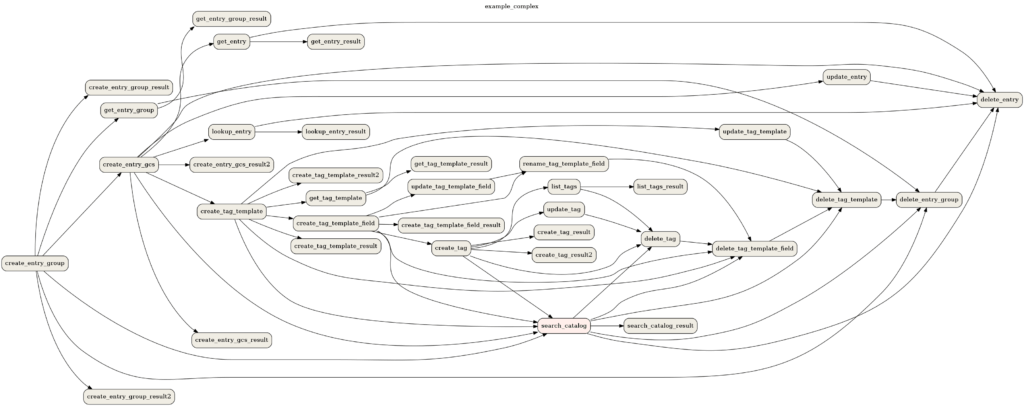
Source: Apache Software Foundation
Finally, a quick Internet search reveals other potential concerns:
- steep learning curve
- Operators execute code in addition to orchestrating workflow, further complicating debugging
- many components to maintain along with Airflow (cluster formation, state management, and so on)
- difficulty sharing data from one task to the next
It’s fair to ask whether any of the above matters, since you cannot avoid having to orchestrate pipelines. And Airflow is a significant improvement over previous methods; is it simply a necessary evil? Well, not really – you can abstract away orchestration in the same way a database would handle it “under the hood.”
Eliminating Complex Orchestration with Upsolver SQLake’s Declarative Pipelines
Upsolver SQLake is a declarative data pipeline platform for streaming and batch data. In a declarative data pipeline, you specify (or declare) your desired output, and leave it to the underlying system to determine how to structure and execute the job to deliver this output.
One of the numerous functions SQLake automates is pipeline workflow management. This means for SQLake transformations you do not need Airflow. Airflow requires scripted (or imperative) programming, rather than declarative; you must decide on and indicate the “how” in addition to just the “what” to process. In a way, it’s the difference between asking someone to serve you grilled orange roughy (declarative), and instead providing them with a step-by-step procedure detailing how to catch, scale, gut, carve, marinate, and cook the fish (scripted). Apologies for the roughy analogy!
The difference from a data engineering standpoint?
- Some data engineers prefer scripted pipelines, because they get fine-grained control; it enables them to customize a workflow to squeeze out that last ounce of performance.
- Others might instead favor sacrificing a bit of control to gain greater simplicity, faster delivery (creating and modifying pipelines), and reduced technical debt.
But there’s another reason, beyond speed and simplicity, that data practitioners might prefer declarative pipelines: Orchestration in fact covers more than just moving data. It also describes workflow for data transformation and table management.
SQLake’s declarative pipelines handle the entire orchestration process, inferring the workflow from the declarative pipeline definition. And since SQL is the configuration language for declarative pipelines, anyone familiar with SQL can create and orchestrate their own workflows. Further, SQL is a strongly-typed language, so mapping the workflow is strongly-typed, as well (meaning every data item has an associated data type that determines its behavior and allowed usage). Airflow, by contrast, requires manual work in Spark Streaming, or Apache Flink or Storm, for the transformation code.
Using only SQL, you can build pipelines that ingest data, read data from various streaming sources and data lakes (including Amazon S3, Amazon Kinesis Streams, and Apache Kafka), and write data to the desired target (such as e.g. Amazon Athena, Amazon Redshift Spectrum, and Snowflake). You also specify data transformations in SQL. SQLake automates the management and optimization of output tables, including:
- various partitioning strategies
- conversion to column-based format
- optimizing file sizes (compaction)
- upserts (updates and deletes)
With SQLake, ETL jobs are automatically orchestrated whether you run them continuously or on specific time frames, without the need to write any orchestration code in Apache Spark or Airflow. This is how, in most instances, SQLake basically makes Airflow redundant, including orchestrating complex workflows at scale for a range of use cases, such as clickstream analysis and ad performance reporting.
In the following example, we will demonstrate with sample data how to create a job to read from the staging table, apply business logic transformations and insert the results into the output table. You can test this code in SQLake with or without sample data.
CREATE JOB transform_orders_and_insert_into_athena_v1
START_FROM = BEGINNING
ADD_MISSING_COLUMNS = TRUE
RUN_INTERVAL = 1 MINUTE
AS INSERT INTO default_glue_catalog.database_2883f0.orders_transformed_data MAP_COLUMNS_BY_NAME
-- Use the SELECT statement to choose columns from the source and implement your business logic transformations.
SELECT
orderid AS order_id, -- rename columns
MD5(customer.email) AS customer_id, -- hash or mask columns using built-in functions
customer_name, -- computed field defined later in the query
nettotal AS total,
$commit_time AS partition_date -- populate the partition column with the processing time of the event, automatically cast to DATE type
FROM default_glue_catalog.database_2883f0.orders_raw_data
LET customer_name = customer.firstname || ' ' || customer.lastname -- create a computed column
WHERE ordertype = 'SHIPPING'
AND $commit_time BETWEEN run_start_time() AND run_end_time();
Summary
- Airflow fills a gap in the big data ecosystem by providing a simpler way to define, schedule, visualize and monitor the underlying jobs needed to operate a big data pipeline.
- Airflow was built for batch data, requires coding skills, is brittle, and creates technical debt.
- SQLake uses a declarative approach to pipelines and automates workflow orchestration so you can eliminate the complexity of Airflow to deliver reliable declarative pipelines on batch and streaming data at scale.
More Information
There’s much more information about the Upsolver SQLake platform, including how it automates a full range of data best practices, real-world stories of successful implementation, and more, at www.upsolver.com.
Better yet, try SQLake for free for 30 days. It lets you build and run reliable data pipelines on streaming and batch data via an all-SQL experience. Try it for free. No credit card required. And you can get started right away via one of our many customizable templates. Try it with our sample data, or with data from your own S3 bucket.
Visit SQLake Builders Hub, where you can browse our pipeline templates and consult an assortment of how-to guides, technical blogs, and product documentation.
If you have any questions, or wish to discuss this integration or explore other use cases, start the conversation in our Upsolver Community Slack channel.
To speak with an expert, please schedule a demo: https://www.upsolver.com/schedule-demo.
Published in:
Blog
,
Data Lakes