
Explore our expert-made templates & start with the right one for you.
Effortless Table Management with Adaptive Optimizer for Apache Iceberg: Boost Performance & Cut Costs
-
 Roy Hasson
Roy Hasson
- Cloud Architecture
- October 17, 2024
Boost query performance by more than 2.5X and reduce storage costs by 50% compared to self-tuned Hive tables, without lifting a finger.
Today, data teams need to manually develop and schedule custom tasks to maintain each and every table in their Lakehouse, leading to inconsistent query performance and runaway costs. Code- and engineering-intensive workflows are used to ensure tables are always optimized, old versions of tables are properly expired and newly ingested data doesn’t conflict with on-going optimizations. This creates unnecessary overhead and reduces the value businesses can generate from their lakehouse through analytics and AI implementations.
Today, we are pleased to introduce the latest addition to Upsolver’s Lakehouse Management platform. Adaptive Optimizer for Apache Iceberg is an intelligent agent that continuously audits your data files and optimizes how they are organized and stored for faster queries and lower storage costs. Adaptive Optimizer automatically manages your tables to eliminate write conflicts and possible data corruption, freeing up hundreds of engineering hours spent on monitoring, troubleshooting and optimization tasks.
Adaptive Optimizer works on Iceberg tables registered with AWS Glue Data Catalog, Apache Hive Metastore, Apache Polaris Catalog (self-managed as well as Snowflake-managed) and any Iceberg REST compatible catalog. Optimizations are powered by Upsolver’s highly scalable, cloud native Lakehouse platform making it easy and cost-effective to manage petabyte scale lakes.
Get started today with Adaptive Optimizer by signing up to Upsolver.
Data layout and file optimization is a hard problem
Organizations adopt Apache Iceberg and the lakehouse architecture in order to make all their data available for analytics and AI, in a more scalable way than traditional data warehouses or data lakes. However, ingesting operational data into ready-to-query formats often becomes a stumbling block.
To extract the best query performance from Iceberg tables, files must be grouped into the right number of partitions, with rows sorted and coalesced efficiently among other techniques, to produce an ideal layout that best matches changing query patterns. Getting this right consistently requires deep technical expertise, long testing cycles and tedious manual troubleshooting, tuning and tweaking.
That’s only the beginning, engineers also need to answer:
- Which tables should be optimized?
- How often should optimizations be performed?
- Which table properties should be tuned and to what values?
- How to ensure table data is retained for only the allowed duration?
Having gathered these answers, teams must then develop the code and procedures to implement and run these operational tasks. Tasks will include scheduling optimizations per table, recovering from write conflicts, diagnosing failures, and validating proper expiration and deletion of data. Finally, teams must continuously test, tune and update these jobs as data volume increases, new tables are added, and access patterns change.
Adaptive Optimizer solves data management problems as your business grows, automatically!
With Adaptive Optimizer, Upsolver takes care of all the Iceberg data layout, optimization and maintenance for you. Upsolver runs in AWS and integrates with Apache Hive Metastore, AWS Glue Data Catalog, Apache Polaris Catalog and any Iceberg REST compatible catalog. Upsolver-managed Iceberg tables can be queried with Snowflake, Amazon Redshift and Athena, Dremio, Starburst, Apache Presto and Trino, Spark, DuckDB, StarRocks and any other Iceberg compatible engine.
Once it’s running, Adaptive Optimizer offers four main capabilities:
Algorithmic analysis determines the most impactful way to optimize your Iceberg tables
Adaptive Optimizer determines when and how to optimize Iceberg data. It also calculates when to delete files based on factors such as data profile, table properties, frequency of row-level changes, cost and performance characteristics. Using advanced algorithms, Adaptive Optimizer continuously evaluates and combines these factors to produce the most impactful optimizations possible for each individual table, delivering unmatched query speeds and cost reduction out of the box. During ingestion and compaction, Adaptive Optimizer collects and refreshes table statistics, without the need to run ANALYZE on each table. These statistics assist query engines in further accelerating the planning and execution of queries on Iceberg tables.
In our tests, we found that querying Snowflake External Iceberg tables optimized by Upsolver was 80% faster (clustered) and 50% faster (unclustered) than Snowflake Managed Iceberg tables. More in this benchmark.
Intelligent optimizations uniquely adapts to your data for improved lake hygienes and fast queries
Not all tables are created equal. Adaptive Optimizer, as its name suggests, adapts to the chaotic, suboptimal characteristics of raw data to uniquely structure, organize and optimize, delivering the most impactful performance and cost savings, per table. Previously, engineers applied a one-size-fits-all approach to table optimization or sacrificed performance and cost savings by only tuning the most popular tables. With Adaptive Optimizer, you get both performance and cost savings across all of your tables without lifting a finger.
Compared to the undiscerning, one-size-fits-all approach to optimization employed in both Snowflake native tables (using a proprietary format) and Snowflake managed Iceberg tables, Upsolver’s intelligently optimized Iceberg tables require 23% – 69% less storage and deliver query performance on par with Snowflake native tables.
Automatic file layout and partitioning makes your life easier and your queries faster
A standout feature of Upsolver’s Adaptive Optimizer is Adaptive Clustering, designed to simplify and accelerate the creation and management of Iceberg-based Lakehouses optimally, even for previously unseen data.
With Adaptive Clustering, you no longer need to worry about partitioning, as it figures out the right data layout for your tables, delivering better read and write performance compared to manually tuned and partitioned tables. This makes it easy for any user to create and load new Iceberg tables without needing prior knowledge of the data layout or planning and testing different partitioning strategies. Using Adaptive Clustering, you can onboard new datasets and make them available to analytics and data science users in minutes and without data engineering resources.
Cluster keys that you choose will be used to dynamically partition or cluster rows based on characteristics of your data such as density, cardinality and skew. Once applied, benefits of the optimized clusters or partitions apply across all query engines. Adaptive Clustering additionally provides flexibility to redefine clustering keys without rewriting existing files, allowing you to evolve table layout over time to meet users’ query needs.
Adaptive Clustering on Iceberg tables delivers a performance boost out-of-the-box on any new or existing lakehouse deployment. In a recent benchmark on Upsolver’s own log analytics lake, Adaptive Clustering reduced the total number of partitions by 60X and number of files by 140X, compared to a manually tuned partitioned table. Start using Adaptive Clustering today.
Built-in observability makes troubleshooting simpler and the benefits transparent and measurable
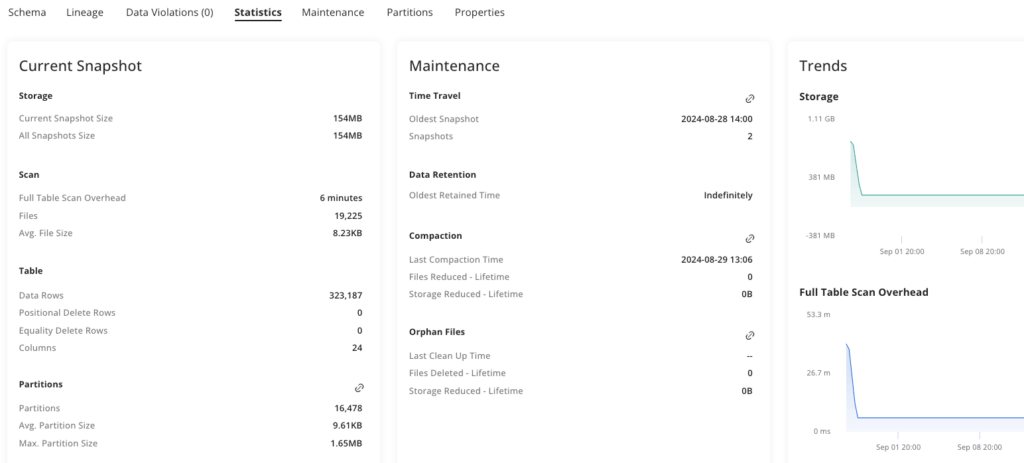
With built-in observability, users can quickly inspect the optimizations and cleanups performed by Adaptive Optimizer and assess their impact on query performance and storage savings. Upsolver’s observability dashboard allows you to understand your data profile, schema evolution, and partition distribution as well as isolate performance bottlenecks in a single place. In addition, you can build custom monitoring and expose them as Iceberg tables for users to query, enabling data consumers to troubleshoot tables themselves, reducing their reliance on data engineers.
Get started today
You can get started today for free by signing up to Upsolver or connect with our solution architects to learn more and see how Adaptive Optimizer can work for you.
Published in:
Blog
,
Cloud Architecture