
Explore our expert-made templates & start with the right one for you.
Building Data Pipelines? Don’t Overlook These 6 Factors
-
 Roy Hasson
Roy Hasson
- Cloud Architecture
- April 6, 2022
It’s easy to think of a data pipeline as a generic, cohesive construct that enables you to move data from a source, through some transformations, into a destination. In most instances, the reality is vastly more complex. Just as a physical pipeline requires connectors (valves and joints), observability (meters, sensors, monitors), transformation (heaters, chemical reagents), flow control (pumps and valves), interoperability standards, and more to do the job, a data pipeline welds multiple components and processes together to reliably take raw data from point A, perform simple or complex transformations to it, and deliver useful analytics-ready data to point B.

We define data pipelines and their function more fully elsewhere. In this article, we break down data pipelines into their component processes, explain 6 factors you must be aware of when creating them, and discuss how systems for building and running pipelines are changing to address these factors and make data pipelines accessible to a broader cross-section of data practitioners.
Why Data Pipelines are Complex
Broadly, pipelines consist of processes for data ingestion, data transformation, and data serving or delivery. The complexity becomes apparent as soon as you start to drill down.
- Ingestion – You can ingest data from multiple sources – from databases, applications, file systems, IoT sensors, and so on. Each data source may have a different schema or a different data model or a different format. Further, some data may arrive as event streams (real-time); others as batch files (historical); you must work equally well with each.
- Transformation – In this part, you filter the data, clean and normalize it, and/or enrich it using operations such as aggregations, joins, windowing, and so on.
- Delivery –The output format (CSV files, columnar Parquet, and so on) must suit the destination, whether that’s a data warehouse such as Amazon Redshift or Snowflake, or a query engine such as Amazon Athena or Redshift Spectrum, or a machine learning application such as Amazon SageMaker.
On top of all that, data pipelines must also have processes for job orchestration and data observability, which can span the length of the pipeline:
- Orchestration ensures that the jobs that constitute the pipeline operation run in the proper order and any dependencies are adhered to. Often there are specific tools to handle this – Apache Airflow is the most common. They help you create a directed acyclic graph (DAG) of the processing steps. But a DAG can be quite time-intensive to build, test, then maintain and fix as source schema “drifts” or data consumption requirements necessitate changes to the pipeline transformation logic.
- Observability alerts you to breakage and performance deterioration. Is your stream coming in? Is it dropping events? Is the data quality of the output good enough for the business? Are you adhering to the SLA metrics you’ve established to meet the downstream requirements of your data consumers?
Pipelines are how businesses derive value from their data. There are countless ways organizations can deploy their pipelines. But there are certain principles to keep in mind.
6 Key Factors When Building Data Pipelines
There are multiple factors you could easily overlook under the pressure of getting your pipelines up and running, alleviate your engineering backlog, and provide your data analysts and scientists with the support for which they’ve been clamoring.
But ignoring any one of these factors could lead to serious issues just a bit downstream. So be sure to pay attention to the following as you choose data pipeline tools and technology and assign tasks:
1. Understand the engine you’re running
2. Write output in an efficient way
3. Manage scheduling and orchestration
4. Perform consistently at scale
5. Stay flexible to deal with underlying changes
6. Know the skill level of your target users
Understand the engine you’re running
A great many tools are based on Apache Spark. With such tools little is automated. To be sure, Spark handles a great many tasks – memory management, garbage collection, shuffling data between nodes, and so on. But these functions start to fail or degrade as the amount of data being processed increases. In turn, that means your data engineers need expertise in Spark to configure and tune these functions to handle the load and make their code as efficient as possible.
Also, while the actual writing of the code is fairly straightforward, the way the code is executed is quite different from engine to engine. If you don’t understand how those engines work, you can’t really optimize your code to improve performance and deal with issues and errors.
So whether it’s Databricks, Google, or EMR, you must understand the underlying engine to scale your jobs in any significant way.
Write output in an efficient way
Most of today’s tools tend to focus primarily on the data processing part of the pipeline, but not properly preparing the output for the destination system. They may indicate the data’s ready to query, but it’s not necessarily so. It may be in JSON format, or not partitioned or structured properly, or require a separate update to the metadata catalog. So you may not get exactly what you want – a queryable dataset that’s fast and optimized. Each of these steps to improve performance can be addressed through more code, but it does create extra friction in the development process and more to maintain once you are in production.
Manage scheduling and orchestration
Pipelines are made up of multiple tasks and they do multiple things. You must orchestrate them – run them at regular intervals, for example, or run them when new data arrives. It’s not sustainable if each time new data comes in you must manually update, reschedule, and re-order the job.
There are tools to help with this – Apache Airflow, dbt, AWS Step Functions. But that means more systems that data engineers must learn, maintain, and scale, occupying time they could otherwise use to design the business logic that sits on top of the pipeline, and that actually converts the data into something valuable for the business.
Perform consistently at scale
Many pipeline processing tools tout their easy user experience. They fit in your pipeline, and when you start running your data through them they work fine. But when you start to scale, you often run into problems. Note that it’s easy to conflate auto-scaling with improving data ingestion and processing throughput. Most tools auto-scale, making it easy to add more nodes. But other factors can still create a bottleneck. During processing, data doesn’t always distribute evenly across the nodes you’ve added. And if the processing task can only run on a single node (such as aggregations and joins), it doesn’t matter how many nodes you have.
How do you diagnose these types of scaling bottlenecks? And do you have the mechanisms to fix them yourself?
Stay flexible to deal with underlying changes
The need to constantly manage, update, and troubleshoot pipelines leads to data engineers becoming overwhelmed with “data plumbing” – constantly chasing the latest bug, recovering from a pipeline crash, or addressing dropped data. This can be especially painful and time-consuming when working in a data lake architecture, when dealing with schema evolution, or when working with real-time data streams.
Yes, it is simple enough to write code to move a daily batch of data from an application to a database. But what happens when you want to add additional fields or a new data source, or reduce refresh time from a day to an hour or minutes? What about changes to business rules or application logic that require you to rerun your pipelines? You must be able quickly to adjust your pipelines as circumstances warrant without the need to manually rebuild, re-architect, or scale your platform.
Know the skill level of your target users
More and more organizations are moving towards an open core mindset. Rather than investing in proprietary technology and getting locked in and having to pay extra money, they try to do as much as possible using open source. But open source is also really hard. If you don’t have developers and others who understand how to work with it, you will struggle. And whether developers will be working in the vendor’s environment or your own also makes a difference. Will they be writing code and debugging and monitoring, or will they mostly just be executing code? The skills you have or are willing to acquire in-house will end up dictating the tools you use.
The choice of language you use to develop your pipelines is important in this regard. SQL is familiar both to data engineers and many data consumers. It’s broadly accessible and portable. It’s well known and easy to understand, and it has a low barrier to entry. It’s also easy to test, and it translates well across platforms if you choose to switch vendors. By contrast, GUI-only tools are difficult to port, test, and automate. And programming languages such as Java, Python, and others have a high learning curve. It’s not feasible to expect everyone in your organization to learn them if they want to produce data.
The Future of Data Pipelines: Bundled Services in a Unified Pipeline Platform
How are technology vendors approaching the challenges we described above? Let’s travel forward in time.
As businesses ask more and more of their pipelines, building and deploying them must continue to simplify. We’re moving towards a self-service model such as Wix or WordPress in the web world; just as you can create a website or online store without knowing any Java or even HTML, you can produce business-critical datasets without knowing Scala or Python.
Today, those wanting to design a data pipeline architecture must stitch different tools together – data integration, data transformation, data quality, data governance, data observability – to assemble a complete solution. But soon enough you’ll no longer need separate tools for each of these functions. The trend in modern data pipelines is towards bundling all of that together, right into an integrated pipeline platform. How does this help? Because when these tools are an integrated part of the pipeline platform you can take immediate corrective action based on the information you detect; there’s no delay or extra step. For example, having your data quality in a separate system from your transformation logic is akin to keeping your rear-view mirror in the trunk of the car and looking at it only when you stop.
The rise of the data mesh paradigm only accelerates this trend. In a data mesh, the “ugly plumbing” of data pipelines becomes the responsibility of discrete business domains, to improve business agility and scale and deliver data as a discrete product. But domains won’t have the same access to experienced data engineers that a central IT or DevOps group would. So those central groups must set up the domains with tools that automate and simplify the pipeline building process such that non-experts – business owners, data analysts, and so on – can work with their data and deliver data products to their customers across the business. An integrated data pipeline platform is required to deliver data as a product.
Finally, data pipelines are incorporating some of the AI that until recently they’ve only enabled. They’re becoming programmable and automated; they can connect new data sources to new targets and adjust data transformations on the fly without manual intervention from a data practitioner. They enable data practitioners to deliver new products almost as soon as a new use case is identified.
Upsolver Simplifies Pipelines for Every Data Engineer
Upsolver is an integrated pipeline platform that takes advantage of these trends. You build your pipelines using SQL commands to describe the business logic and use connectors to define both ingestion sources (such as streams, files, or databases via CDC) and output destinations (a data lake table, your cloud data warehouse, or perhaps back into another event stream). Upsolver automates everything else, including schema detection on read, task orchestration, file system management, state management, UPSERTs, and pipeline monitoring.
Upsolver reduces from months to weeks – or even days – the time it takes to build pipelines and place them into production – even if you’re executing joins on streams being ingested at millions of events per second. You don’t have to learn different languages or become an expert on distributed processing. You don’t need a separate orchestration tool; you don’t need to deal with orchestration at all. And you don’t need to deploy a NoSQL database for state management at scale.
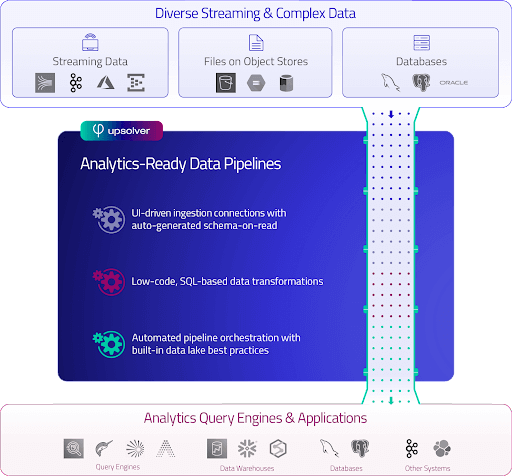
Upsolver normalizes processing across both batch and streaming, and enables different transformations So how does Upsolver fare on the 6 factors above?
- You don’t have to program to the specifics of a particular processing engine.
- Pipelines can output can be to object storage, query engines, data warehouses, databases, or stream processors.
- Orchestration is completely automated.
- Customers have Upsolver pipelines in continuous operation at millions of events per second and PB-scale data sets.
- Changes are easier to make through detection of schema changes, use of SQL to change business logic, and raw data retention and built-in state management that allows pipeline replay.
- Pipelines can be built by anyone who is SQL-savvy.
Further Reading on Data Pipelines
- Learn more about data pipeline challenges and how to overcome them in this recorded talk by Upsolver CEO Ori Rafael.
- Read about how you can build, scale, and future-proof your data pipeline architecture.
- To speak with an expert, please schedule a demo: https://www.upsolver.com/schedule-demo.
- Try SQLake for Free (Early Access). SQLake is Upsolver’s newest offering. It lets you build and run reliable data pipelines on streaming and batch data via an all-SQL experience. Try it for free. No credit card required.
If you have any questions, or wish to discuss these trends or explore other use cases, start the conversation in our Upsolver Community Slack channel.
Published in:
Blog
,
Cloud Architecture
