
Explore our expert-made templates & start with the right one for you.
5 Exciting Redshift and Athena Announcements from re:Invent 2019
-
 Eran Levy
Eran Levy
- Cloud Architecture
- December 12, 2019
Amazon’s annual re:Invent conference in Las Vegas produced a flurry of headlines, with much of the attention devoted to the announcement of Amazon Managed Apache Cassandra Service, which carries the potential to shake-up a whole new segment of the database market. However, what caught our attention were some really interesting announcements related to two of our favorite outputs – Amazon Athena and Amazon Redshift.
1. Redshift Data Lake Export to Apache Parquet
You can now store the result of a Redshift query as an Apache Parquet file on Amazon S3. This is really great news for companies that use Redshift as part of their cloud data lake – columnar Parquet storage is highly efficient when it comes to analytical querying, and enables access from a wide variety of additional services such as Athena and Redshift Spectrum. Upsolver also leverages Parquet when ingesting data to S3, and we think this new feature will definitely make lives easier for companies that rely on Redshift as a core component of their data lake architecture.
Read the full announcement on the AWS website.
2. Federated Queries for Redshift
Currently still in preview, this is another new Redshift feature that adds flexibility and versatility to Redshift, by allowing you to execute Redshift queries on live data in Amazon RDS for PostgreSQL, as well as Amazon Aurora. According to the announcement, “Federated Query also makes it easy to ingest data into Redshift by letting you query operational databases directly, applying transformations on the fly, and loading data into the target tables without requiring complex ETL pipelines.”
Read the full announcement on the AWS website.
3. Next-generation Compute Instances for Redshift
Hailed as the “next generation of Nitro-powered compute instances”, Amazon’s new RA3 instances for Redshift promises to deliver 3x the performance of other databases. This new cluster type brings decoupled storage and compute to Redshift, with separate optimizations for each, and leverages 48 vCPUs, 384 gigabytes of memory and up to 64 terabytes of storage per instance. These enhancements are meant to provide up to 2x better performance and 2x more storage to existing Redshift customers using DS2, without increasing their AWS bill.
Read the full announcement on the AWS website.
4. Advanced Query Accelerator (AQUA) for Redshift
AQUA was described in Andy Jassy’s keynote as an “innovative new hardware-accelerated cache that delivers up to 10x query performance than other cloud data warehouses”. Amazon explains that AQUA will make Redshift faster by running data-intensive tasks closer to the storage layer to reduce data movements between storage and compute clusters, as well as by leveraging a scale-out architecture and purpose-designed processors developed by AWS. This sounds very promising and we’ll be keeping a close eye on Redshift query performance in the coming period!
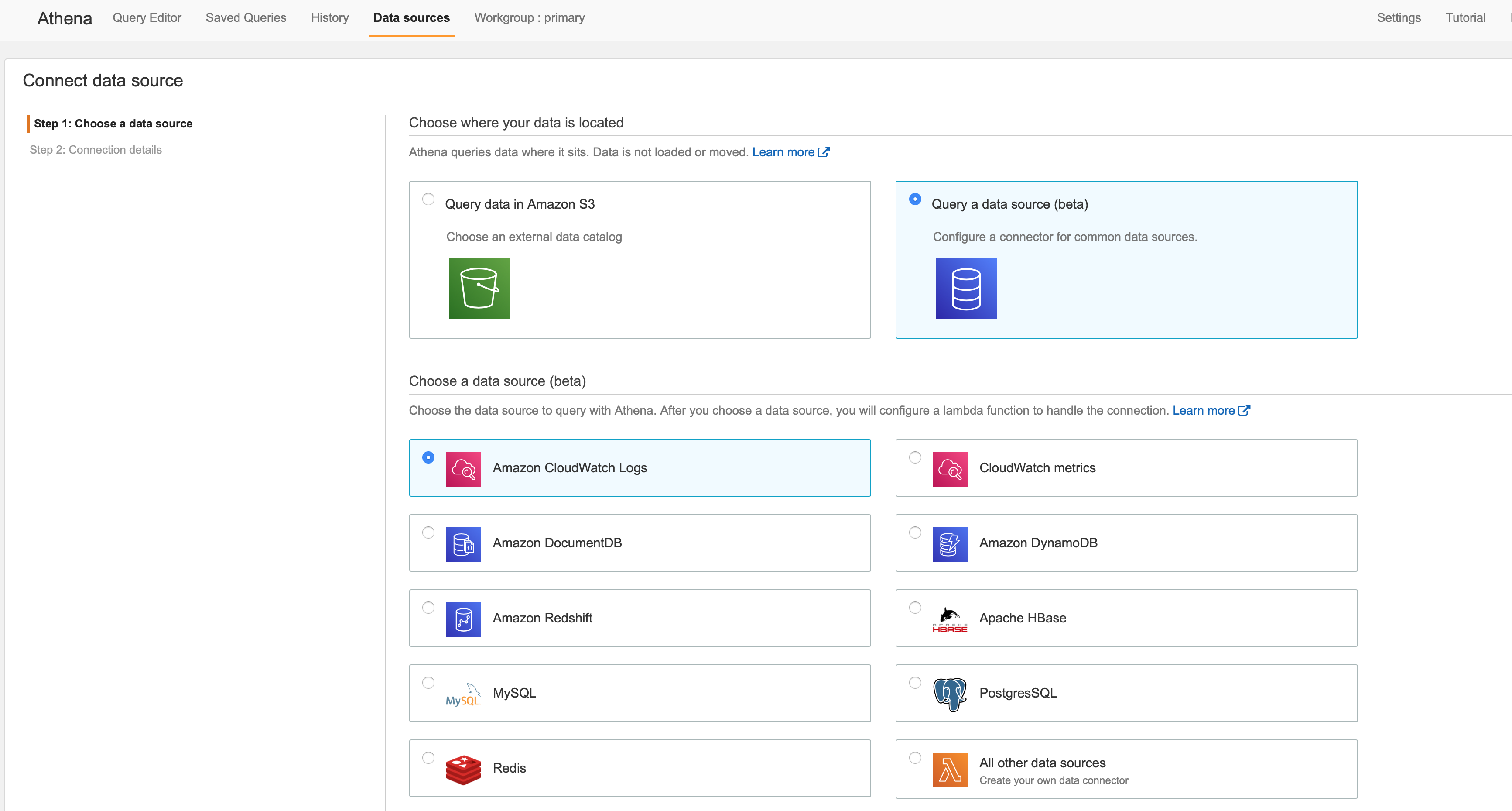
5. Data source connectors for Athena
We’re used to seeing Amazon Athena used to query data stored on S3, often as part of an AWS data lake; this new feature, currently still in preview, offers a way to significantly extend Athena functionality by allowing you to query several additional data sources directly in Athena, using its familiar SQL syntax. Queries run on AWS Lambda, with connectors currently available for DynamoDB, HBase, Document DB, Redshift, CloudWatch, and JDBC-compliant relational databases such as MySQL and PostgreSQL.
Using Athena or Redshift? Upsolver can help you get the most out of your AWS data lake. Learn how you can easily manage batch and streaming ETL in your data lake with UpSQL.
Published in:
Blog
,
Cloud Architecture