
Explore our expert-made templates & start with the right one for you.
24 Features to Boost Your Data Movement in 2024: Part 1
-
 Rachel Horder
Rachel Horder
- Building Data Pipelines
- December 12, 2023
As we say goodbye to 2023 and welcome in the New Year, we’re reflecting on some of the features we’ve built into Upsolver over the past six months that will make ingesting your data an even better experience next year – our 24 for 2024!
We’re half-way through the countdown of the Upsolver Feature Advent Calendar that we’ve been running on LinkedIn, so let’s have a recap:
- Improved Wizard Experience for Easier Ingestion
- System Table for Running Queries
- Smoother Error Handling with IF EXISTS
- Monitoring Integration with Amazon CloudWatch and Datadog
- In-Built Data Observability Tools for Tracking the Health of Your Data
- Love Microsoft SQL Server? Then you’ll love Upsolver!
- Extensive Metrics to Monitor Your Jobs
- Deduplicate Your Streaming Data
- Snapshot Multiple Tables in Parallel
- Cancel Button Added to Stop Running Queries
- Managing Data Quality with Expectations
- Ingest Your MongoDB Data
1 – Improved Wizard Experience for Easier Ingestion
Whether you need change data capture or streaming ingestion at scale, our new and improved no-code Wizard will help you connect to your source and deliver your data to your target. Alongside automatic schema evolution, and built-in monitoring and observability, our Wizard will have your data flowing before you know it!
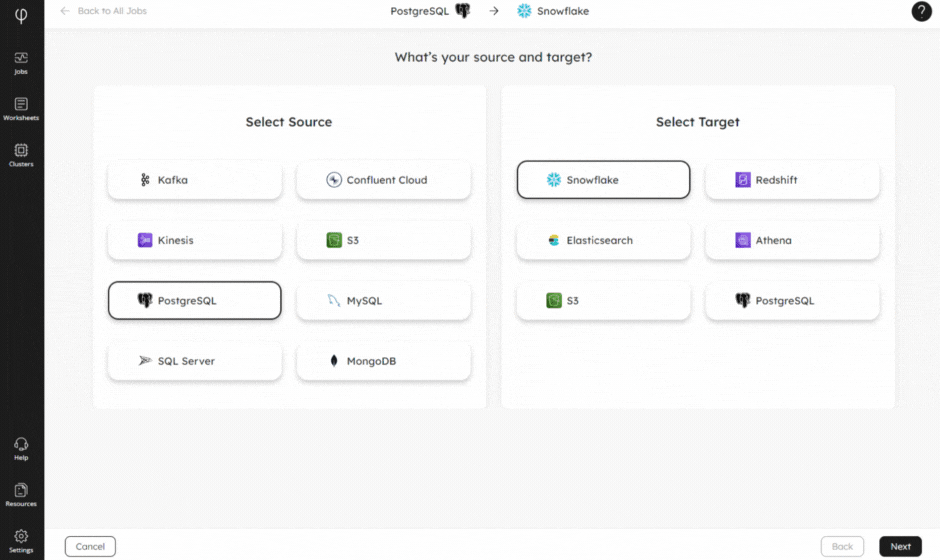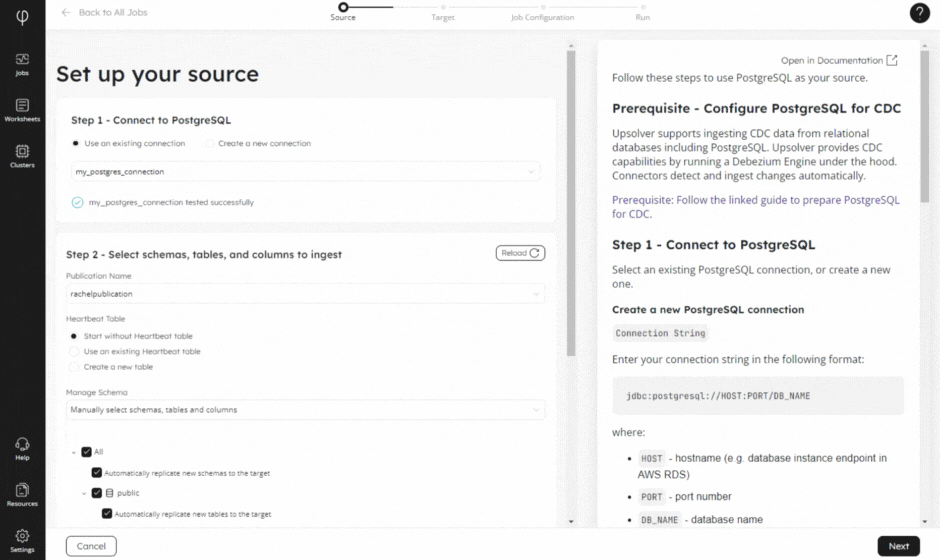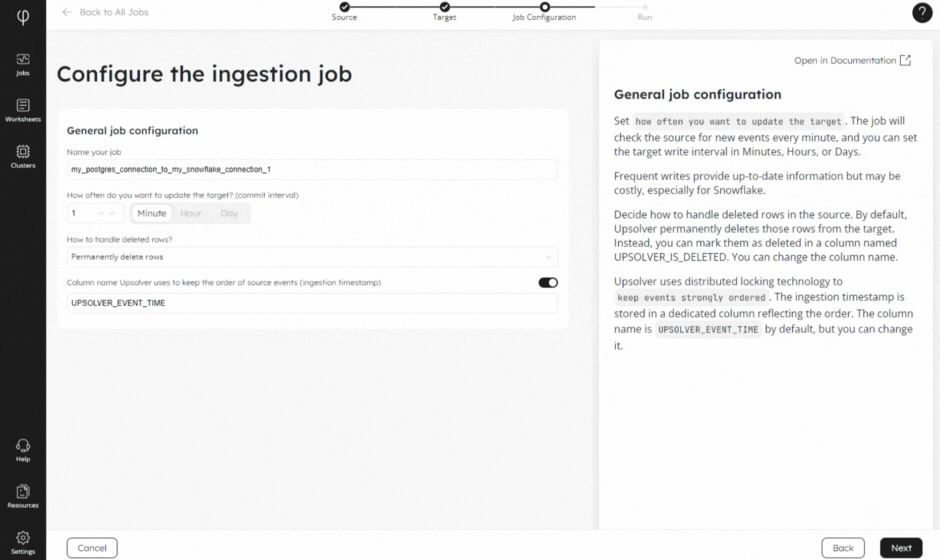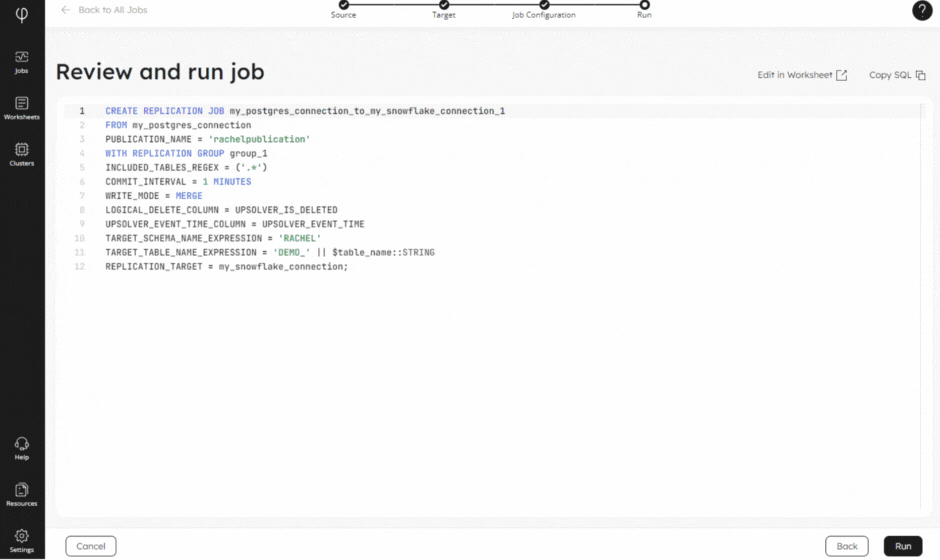
2 – System Table for Running Queries
On Day 1, we showed that we have improved our no-code Wizard for building pipelines. But if you want to roll your own using SQL, open a Worksheet in Upsolver and start coding! Our extensive library of options, functions, and operators enables powerful pipelines. Keep an eye on your running queries using the system.monitoring.running_queries table that returns the SQL statement, start time, duration in milliseconds, the number of bytes scanned, and the number of items scanned. To view this table, open a worksheet in Upsolver and run the following command:
SELECT * FROM system.monitoring.running_queries;
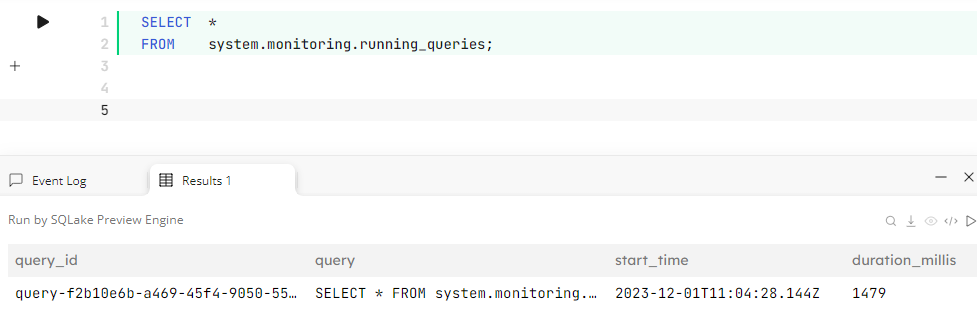
Find out more about the system.monitoring.running_queries table, and also how to cancel a long running query.
3 – Smoother Error Handling with IF EXISTS
When it comes to coding, it’s always good practice to catch an error and handle it gracefully, rather than be confronted with a big red cross. That’s why our engineers added support for including IF EXISTS to your drop statements. If you run the following statement:
DROP TABLE IF EXISTS "my_table";
And if the table does not exist, you’ll be presented with a message to say the entity does not exist, rather than an error message. A much nicer coding experience! Supported objects include: clusters, connections, tables, jobs, and materialized views.
4 – Monitoring Integration with Amazon CloudWatch and Datadog
Monitoring your pipelines is essential for ensuring your data keeps on flowing. In Upsolver, it is quick and easy to create a job to send your metrics to Amazon CloudWatch and Datadog, enabling you to consolidate your monitoring and support the reliability and performance of your data pipelines. Use this feature to benefit from:
- Centralized Visibility: monitor your systems and data from a single tool.
- Alerting & Notifications: create alerts on predefined thresholds for immediate response.
- Customization: leverage advanced visualization tools for enhanced reporting.
Learn how to monitor your jobs from Amazon CloudWatch and Datadog.
5 – In-Built Data Observability Tools for Tracking the Health of Your Data
Datasets in Upsolver provide powerful information to enable you to observe the flow and volume of your data, check for quality issues, and uncover changes to your source schema. These statistics are built in as standard in Upsolver, saving you the time and expense of having to query your data warehouse or acquire additional resources to build custom reports. However, if you want to run your own queries, we also provide system tables you can interrogate for your own use cases and custom reporting.

Whether you’re a data engineer responding to end-user queries about the data lineage in your pipelines, or a consumer investigating the freshness of your data, the Datasets tab is your go-to location for data observability.
Read the article How to Observe Data with Datasets to get started, or take a look at the Datasets documentation reference for more in-depth information on each statistic.
6 – Love Microsoft SQL Server? Then you’ll love Upsolver!
There are many reasons why SQL Server remains a hugely popular and much-loved data platform: a robust OLTP engine, user-friendly UI, and feature-rich integration and reporting components are just a few. Copying your data from SQL Server to your data lake or data warehouse such as Snowflake or Amazon Redshift, is as easy as enabling CDC and running Upsolver’s ingestion Wizard.
But wait a second! You’re a SQL developer and want to write your own code, right? Of course you can! Using familiar SQL syntax in Upsolver you can build your jobs using our library of options, functions, and operators.
CREATE SYNC JOB load_raw_data_from_mssql
COLUMN_TRANSFORMATIONS = (email = MD5(email))
COMMENT = 'Ingest CDC data from SQL Server'
AS COPY FROM MSSQL my_mssql_connection
INTO default_glue_catalog.upsolver_samples.orders_raw_data
TABLE_INCLUDE_LIST = ('dbo.customers', 'dbo.orders')
COLUMN_EXCLUDE_LIST = ('dbo.*.credit_card', 'dbo.customers.address_.*')
WITH EXPECTATION exp_orderid_not_null EXPECT orderid IS NOT NULL ON VIOLATION DROP;Learn how to ingest your Microsoft SQL Server data into the data lake, Amazon Redshift, PostgreSQL, Elasticsearch, or Snowflake.
7 – Extensive Metrics to Monitor Your Jobs
In Upsolver, metrics are continuously gathered to monitor job performance, issues, and errors. These metrics provide extensive information on the running of the job, the data processed by the job – whether an ingestion or transformation job – and details regarding your cluster. You can use these metrics to ensure your jobs run as expected, and that data is flowing efficiently.
The new and improved user interface will quickly show you where you have errors or delays, and enable you to troubleshoot issues within your pipelines:
- View the number of queued jobs to keep an eye on your backlog
- Check how many rows were scanned and processed
- Discover the number of rows filtered out by a
WHEREclause in a job - Monitor the performance of your cluster and diagnose issues
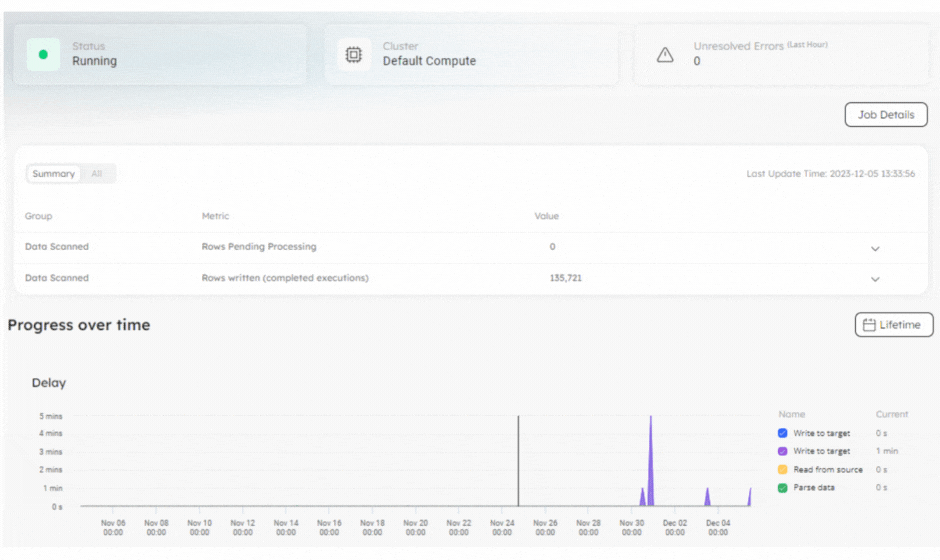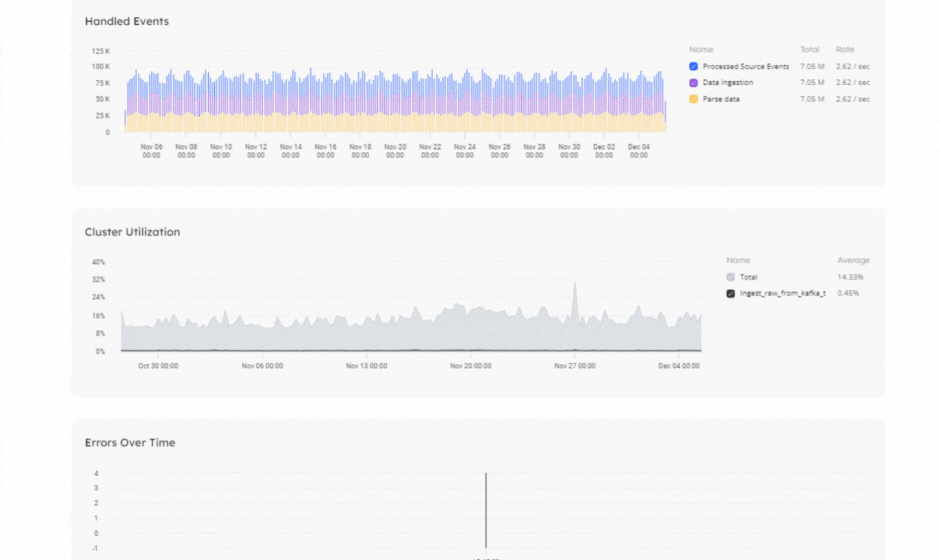
Discover how you can monitor your job status with Upsolver.
8 – Deduplicate Your Streaming Data
This is a super cool feature that helps ensure your target only receives unique events so that your dashboards and reports won’t reflect incorrect numbers as a result of duplicate records. We recently introduced the DEDUPLICATE_WITH job option to prevent duplicate rows from arriving in your target. To deduplicate your streaming data, define one or more columns in a list that serve as a unique key, and all events within your specified timeframe window will be deduplicated:
// Ingest Kafka to Snowflake and dedupe on orderid
CREATE SYNC JOB ingest_kafka_to_snowflake
COMMENT = 'Load orders into Snowflake'
CONTENT_TYPE = JSON
// dedupe on orderid using a 1 day timeframe
DEDUPLICATE_WITH = (COLUMNS = (orderid), WINDOW = 1 DAY)
COMMIT_INTERVAL = 5 MINUTES
AS COPY FROM KAFKA upsolver_kafka_samples
TOPIC = 'orders'
INTO SNOWFLAKE my_snowflake_connection.demo.orders_transformed;So for example, if you have a third-party application sending the same event multiple times a day, you can define one or more columns as your key and set the time frame to be 1 DAY. Upsolver excludes all duplicate events that arrive within the day. Goodbye dupes!
Learn more about building pipelines for your streaming data.
9 – Snapshot Multiple Tables in Parallel
If you’re ingesting data from a CDC database source, you can use the SNAPSHOT_PARALLELISM job option to define how many tables you want Upsolver to snapshot simultaneously. This will quicken the time it takes to have your data streaming to your target. It’s very easy to define in your job syntax:
CREATE JOB load_orders_raw_data_from_postgres
COMMENT = 'Ingest PostgreSQL data to staging'
PUBLICATION_NAME = 'sample'
SNAPSHOT_PARALLELISM = 5
AS COPY FROM POSTGRES upsolver_postgres_samples
INTO default_glue_catalog.upsolver_samples.orders_raw_data;This applies to Microsoft SQL Server, MongoDB, MySQL, and PostgreSQL.
10 – Cancel Button Added to Stop Running Queries
Today’s feature is super simple, yet oh so needed when your query is taking a bit longer to run than first anticipated…
Running queries can now be stopped via the UI with a new Cancel button. You will find the Cancel button next to a running query in the Event Log tab at the bottom of your query window:

And yes, we’ve all been there!
11 – Managing Data Quality with Expectations
We’ve released some pretty major features this year, and expectations are no exception. Despite being super easy to add to your jobs, expectations offer precise control over the quality of your in-flight data, preventing bad data from reaching your downstream target where it’s more difficult to fix.
You can use any of the Upsolver-supported conditions in your expectations, as long as a Boolean value is returned.
// CREATE INGESTION JOB WITH EXPECTATIONS
CREATE SYNC JOB raw_orders_to_kafka_dataset
CONTENT_TYPE = JSON
AS COPY FROM upsolver_kafka_samples
TOPIC = 'orders'
INTO default_glue_catalog.upsolver_samples.orders_raw_data
WITH EXPECTATION exp_state
EXPECT LENGTH(customer.address.state) = 2 ON VIOLATION WARN
WITH EXPECTATION exp_nettotal EXPECT nettotal > 0 ON VIOLATION WARN;
// ADD EXPECTATION TO CHECK POST CODE IS NOT NULL
ALTER JOB raw_orders_to_kafka_dataset
ADD EXPECTATION exp_postcode
EXPECT customer.address.postcode IS NOT NULL ON VIOLATION DROP;
// ADD EXPECTATION TO CHECK FOR TAXRATE
ALTER JOB raw_orders_to_kafka_dataset
ADD EXPECTATION exp_taxrate
EXPECT taxrate = 0.12 ON VIOLATION DROP;You can then monitor the violations captured by your expectations in the Datasets feature and observe the flow of data in your pipelines and the quality within:
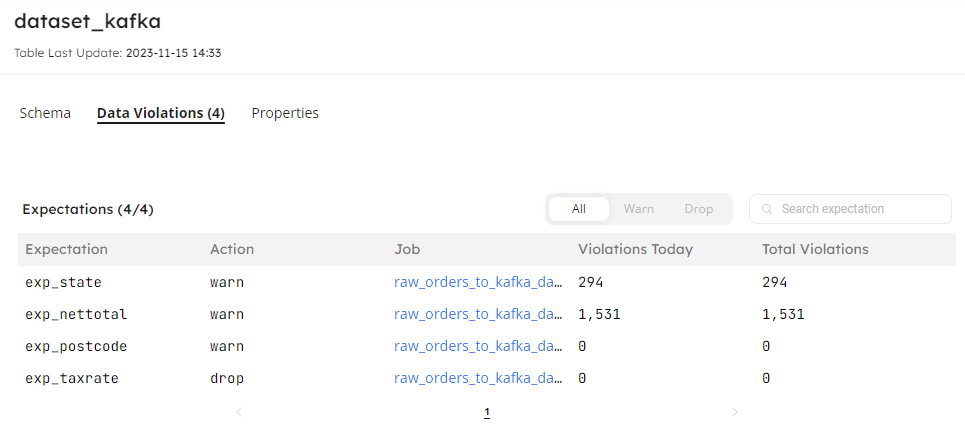
For more information on expectations, read the how to guide for Managing Data Quality – Ingesting Data with Expectations.
12 – Ingest Your MongoDB Data
Of course, we couldn’t support Microsoft SQL Server, MySQL, and PostgreSQL CDC sources and leave MongoDB out in the cold. This year, we added support for MongoDB, the popular NoSQL database that uses a flexible, schema-less data model that enables developers to work with evolving data structures and adapt to changes in requirements more easily than traditional relational databases.
Add in the ability to scale horizontally, and it is well-suited for handling large amounts of data and traffic… And Upsolver can ingest those large volumes of data into the destination of your choice.
CREATE SYNC JOB load_raw_data_from_mongodb
COLUMN_TRANSFORMATIONS = (email = MD5(email))
COMMENT = 'Ingest CDC data from MongoDB'
AS COPY FROM MONGODB my_mongodb_connection
COLLECTION_INCLUDE_LIST = ('sales.customers', 'sales.orders')
INTO default_glue_catalog.upsolver_samples.orders_raw_data;Discover how to ingest your data from MongoDB.
If you have high-scale big data, streaming, or AI workloads, try out Upsolver’s self-serve cloud data ingestion service FREE for 14 days or book a demo with of our expert solution architects.
Published in:
Blog
,
Building Data Pipelines
