Explore our expert-made templates & start with the right one for you.
Pipelines for data in motion on AWS
“We use Upsolver to ingest and optimize 20B events per day into our data lake on AWS, resulting in fresh data being available within minutes and a 10X acceleration of data lake queries.”
– Boaz Goldstein, R&D Manager, Data Architecture & Business Intelligence, Peer39.
Upsolver in the AWS ecosystem
Upsolver is a serverless data pipeline platform. Its the fastest way to build pipelines that ingest and transform streaming and batch data for use in Athena, Redshift and other native and 3rd-party systems on AWS.
AWS Glue and AWS EMR are native services for building data processing pipelines on AWS. However, these systems require expertise in technologies such as Python, Scala, Spark and Airflow. Upsolver users write pipelines with a guided wizard that uses SQL for declaring pipeline logic and blends batch and streaming data sources in a single pipeline, and it automatically orchestrates and optimize pipelines.
As we like to say, “Write a query, get a pipeline.”
| Upsolver | AWS Glue | AWS EMR | |
| Main dev language | Wizard or SQL | Python/Scala | Python/Scala/Java |
| Orchestration | Self-orchestrated | Manual (+Airflow) | Manual (+Airflow) |
| Stream+Batch | 1 engine | Separate engines | Separate engines |
| Recommended for | SQL data engineers Non data engineers |
Spark data engineers | Spark data engineers |
SQL simplicity combined with AWS scale
Upsolver combines the simplicity of wizard- or SQL-based pipeline development with the infinite operating scale of Amazon object storage and processing. With Upsolver, creating an always-on data pipeline that delivers up-to-the-minute, high-quality data from event streams, logs and database sources is as easy as filling out a form or writing a query. Upsolver automatically creates a data lake for raw data that is queryable and highly performant. At its core, Upsolver is a stream processing engine combined with a scalable state store for large joins, aggregations, and upserts.
Without Upsolver, data engineers need to stitch together a solution across multiple AWS services, including Glue streaming, Glue batch, Glue crawlers, step functions or Airflow for orchestration, Amazon DynamoDB for state management, and scripts for implementing best practices to optimize performance.
With Upsolver, you can:
|
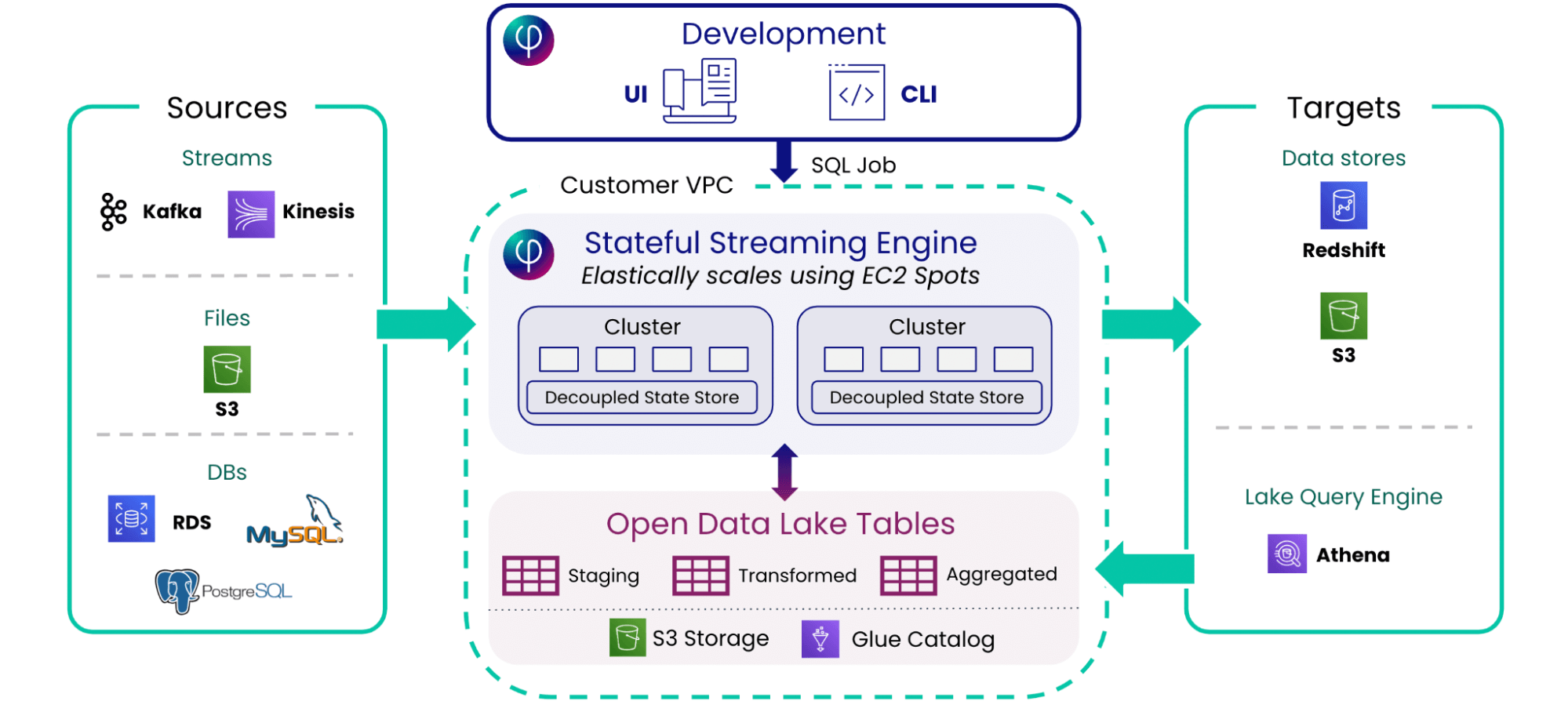
Reference architecture for AWS
Ingestion: Upsolver connects data sources such as Amazon Kinesis Data Streams, Amazon Managed Streaming for Apache Kafka (MSK), Amazon S3, Amazon Aurora, and Amazon RDS.
Outputs: Live tables are output to Amazon Redshift, Amazon S3, and Amazon Athena, as well as to 3rd-party services such as Snowflake and Elasticsearch.
Processing: Upsolver runs on AWS infrastructure and leverages Amazon S3 for affordable storage, Amazon EC2 Spot for low-cost data processing, and AWS Glue Data Catalog for metadata management.
Certifications
Some of the companies winning with Upsolver and AWS
 |
 |
 |
 |
| How ironSource Built a Data Lake with Upsolver
ironSource uses Upsolver to build, manage, and orchestrate its data lake with minimal coding and maintenance. They saved hundreds of thousands of dollars per year by creating an architecture that separates compute and storage. |
The Meet Group drives real-time insights with Upsolver
The Meet Group is a leading provider of online dating solutions. After several acquisitions, The Meet Group sought a solution to integrate its data pipelines and central data collection to drive better real-time analysis. |
SimilarWeb Analyzes Hundreds of Terabytes
SimilarWeb reduced time to insight from 24 hours to minutes with a performant, cost effective, and efficient solution built on Athena for SQL analytics, S3 for events storage, and Upsolver for data pipelines. |
Bigabid Improves its Modeling Accuracy 200x
Bigabid drives new user insights and advertising opportunities with machine learning via Upsolver and AWS. Using Upsolver’s data pipeline platform, Bigabid built a working proof of concept for its real-time pipeline in hours. |
Test drive Upsolver today
- Get started with a free 30-day trial of Upsolver on AWS. No credit card required.
- Download the O’Reilly eBook “Unlock Complex and Streaming Data with Declarative Data Pipelines“
- Read up on benchmarks comparing Upsolver + Athena with Google BigQuery
- Learn how to reduce cost and increase data freshness using Upsolver, AWS, and Snowflake together (benchmark).
- See “How to Build & Manage Data Pipelines for Streaming Data on AWS” in this webinar with Upsolver and AWS.
Discover how companies like yours use Upsolver
Data preparation for Amazon Athena.
Browsi replaced Spark, Lambda, and EMR with Upsolver’s self-service data integration.
Read case studyBuilding a multi-purpose data lake.
ironSource operationalizes petabyte-scale streaming data.
Read case studyDatabase replication and CDC.
Peer39 chose Upsolver over Databricks to migrate from Netezza to the Cloud.
Read case studyReal-time machine learning.
Bigabid chose Upsolver Lookup Tables over Redis and DynamoDB for low-latency data serving.
Read case study
Start for free - No credit card required
Batch and streaming pipelines.
Accelerate data lake queries
Real-time ETL for cloud data warehouse
Build real-time data products