Explore our expert-made templates & start with the right one for you.

Upsolver’s Adaptive Optimizer for Apache Iceberg
✓ Maximize Query Performance
✓ Minimize Storage Costs
The Problem
If you’re managing large-scale data in a lakehouse, you know how quickly things can become complicated.
Data often arrives in unpredictable, disorganized formats, making it difficult to maintain efficient storage and fast query performance.

You likely find yourself spending countless hours manually optimizing tables, fixing issues, and running maintenance tasks just to keep everything running smoothly.

These manual processes not only slow down queries but also increase storage costs, creating ongoing challenges in keeping your system efficient.
The Solution?
Upsolver’s Adaptive Optimizer

Automatically determines the right data layout for your tables, continuously adjusting to variations in data distribution, skew, and cardinality, all without manual intervention.

Continuously evaluates and adapts to produce the most impactful optimizations possible for each individual table, delivering unmatched query speeds and cost reduction out of the box.

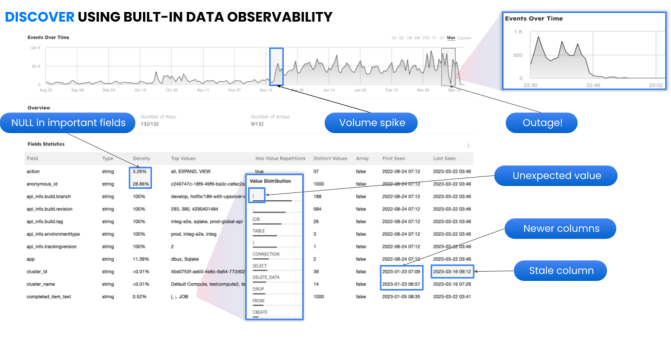
Easily inspect the optimizations and cleanups performed by Adaptive Optimizer, isolate performance bottlenecks and assess their impact on query performance and storage savings.
Get value from Upsolver’s Adaptive Optimizer in minutes
Built and designed to meet data management needs

Improved Query Performance
Adaptive Optimizer delivers over 2.5X faster query execution by intelligently organizing data based on usage patterns, partitioning, and clustering.

Efficient Storage Management
Reduce storage usage by up to 50% by automatically managing compaction, partitioning, and file expiration.
Conflict-Free Data Management
Prevent data corruption and write conflicts through continuous auditing and file management, eliminating the need for manual troubleshooting.
Seamless Compatibility
Works with AWS Glue Data Catalog, Apache Hive Metastore, Apache Polaris Catalog, and other Iceberg-compatible systems, enabling efficient management at scale.

Algorithmic Analysis
Advanced algorithms continuously assess data characteristics, query patterns, and table properties to determine the most impactful optimizations.
Adaptive Clustering
Automatically adjusts table layout and partitioning to align with changing data profiles, reducing the need for custom partitioning strategies.

Observability
Built-in monitoring and reporting provide visibility into optimization results, helping users track query performance improvements and storage savings.
Want to learn more? Book time with an engineer.
Empowering the next generation
of data developers
From startups to enterprises

